



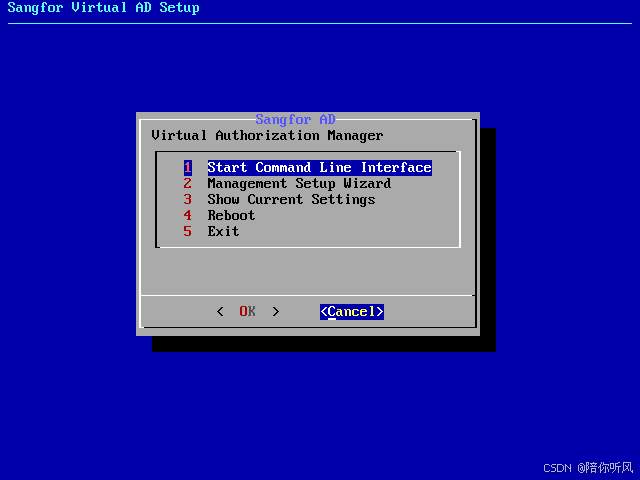
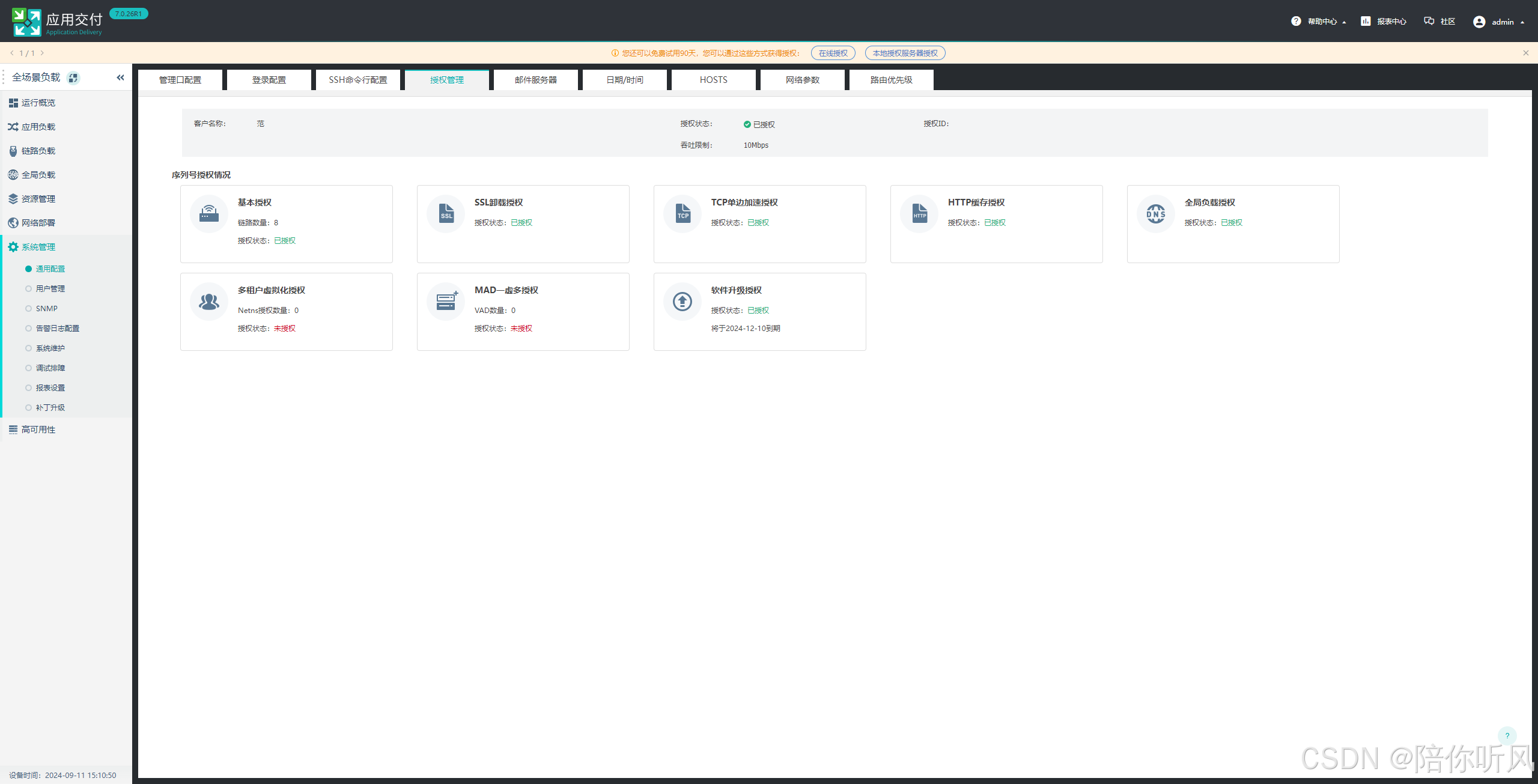
1、下载vAD虚拟化系统,导入vmware。启动后配置管理口地址,登录系统。申请试用授权,在授权管理里导入激活。
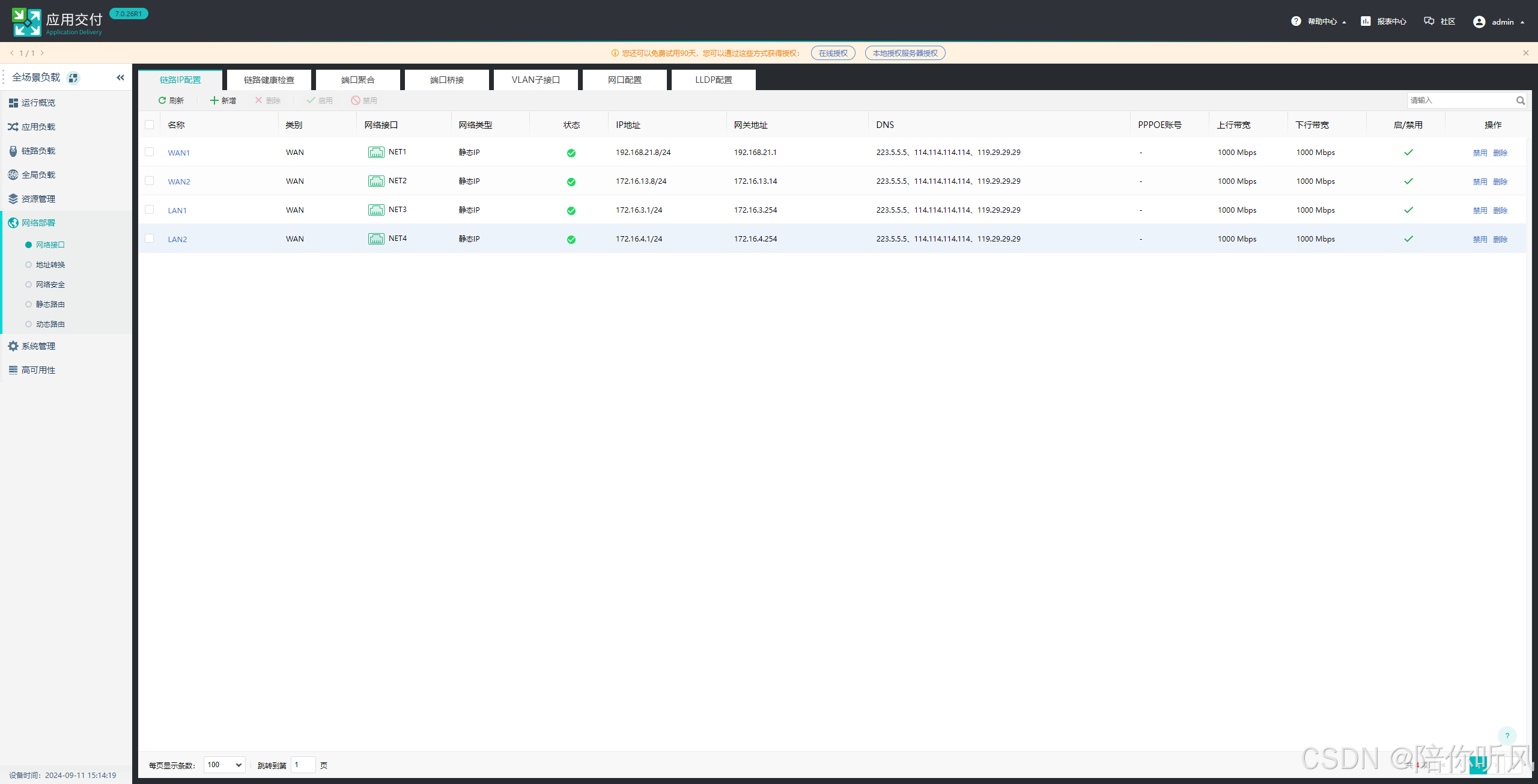
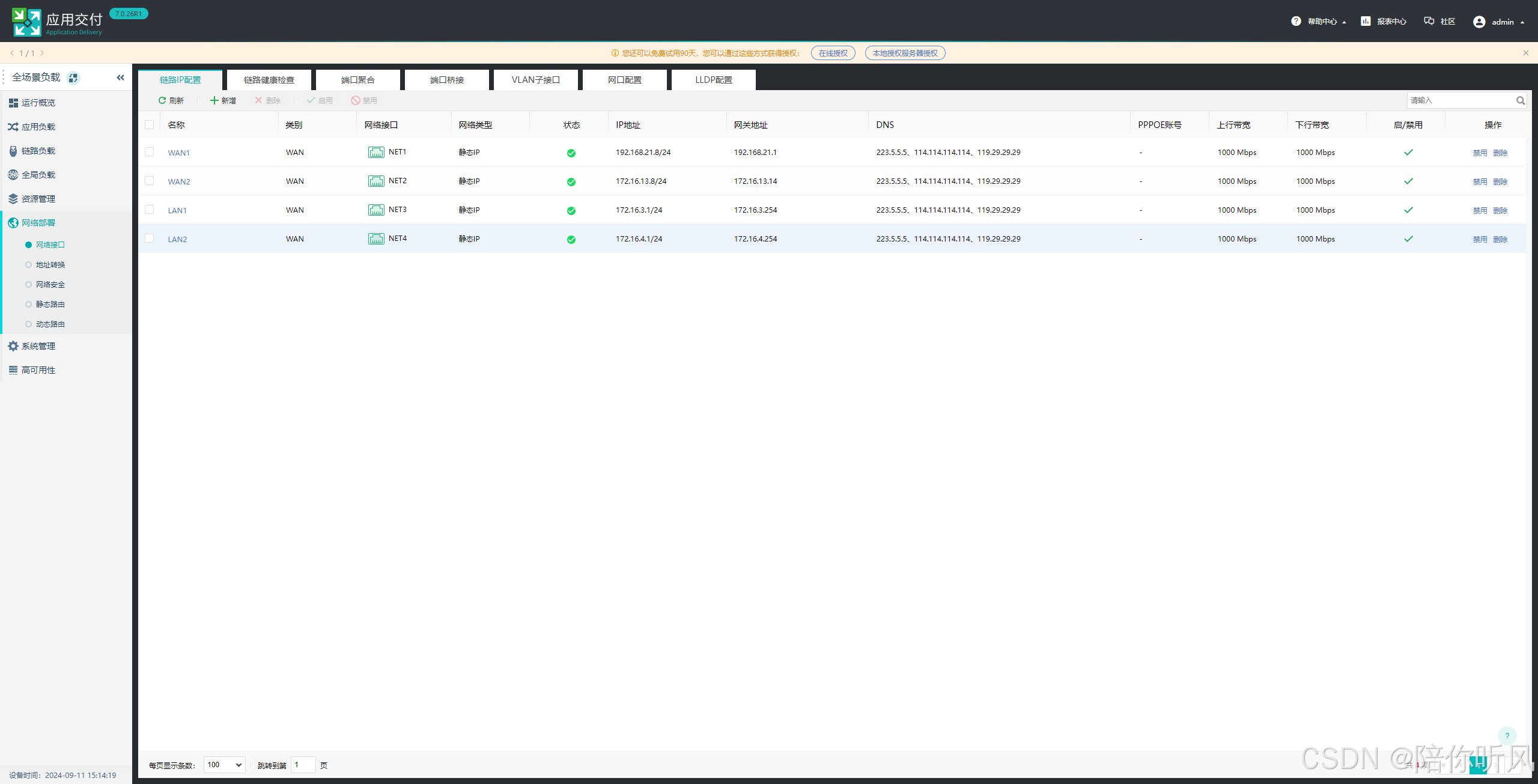
2、规划网络网口,进行网口配置。
网络部署-网络接口中配置接口
网络部署-静态路由中配置路由
网络部署-地址转换中配置源地址转换

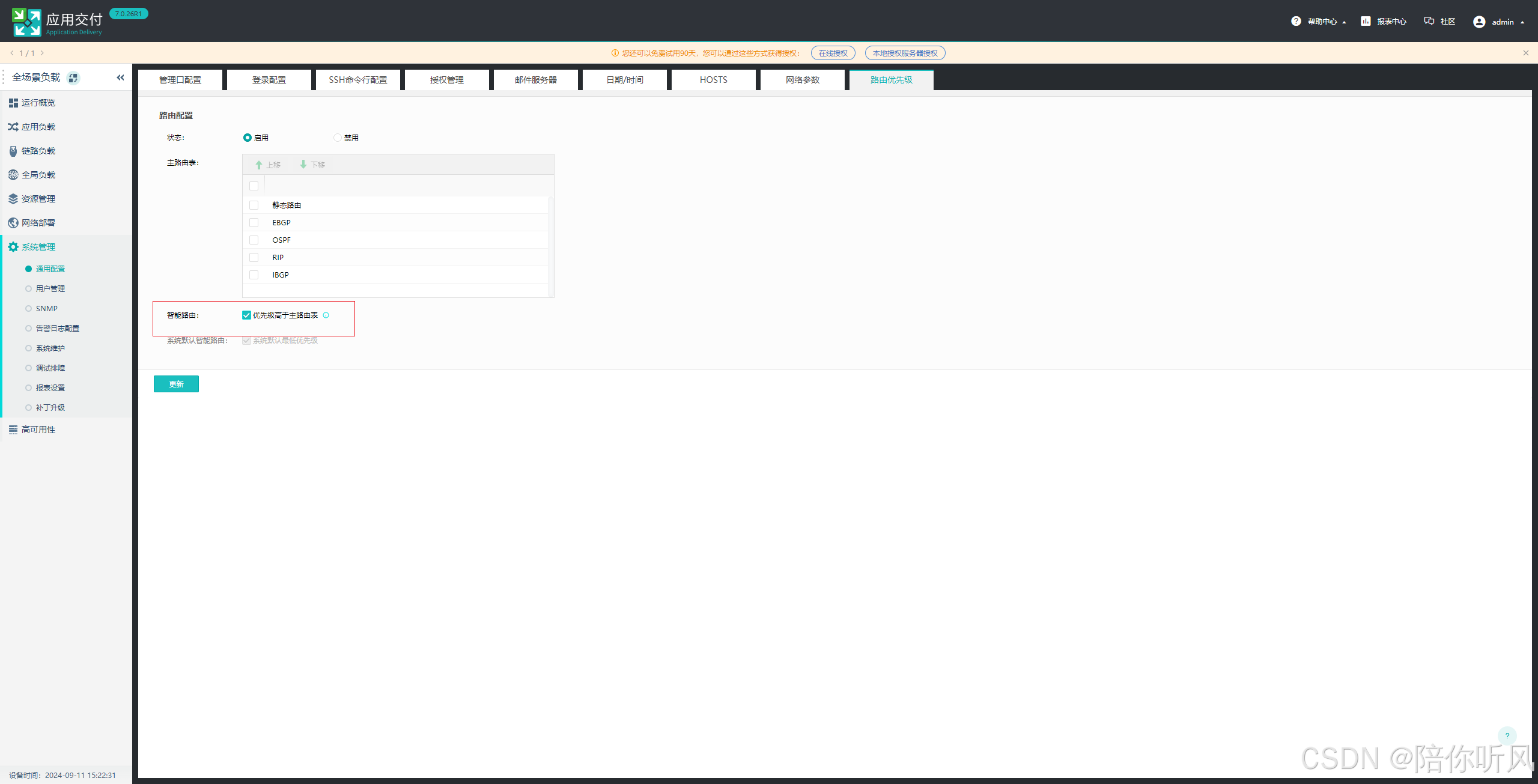
3、配置路由优先级,智能路由优先级高于主路由表
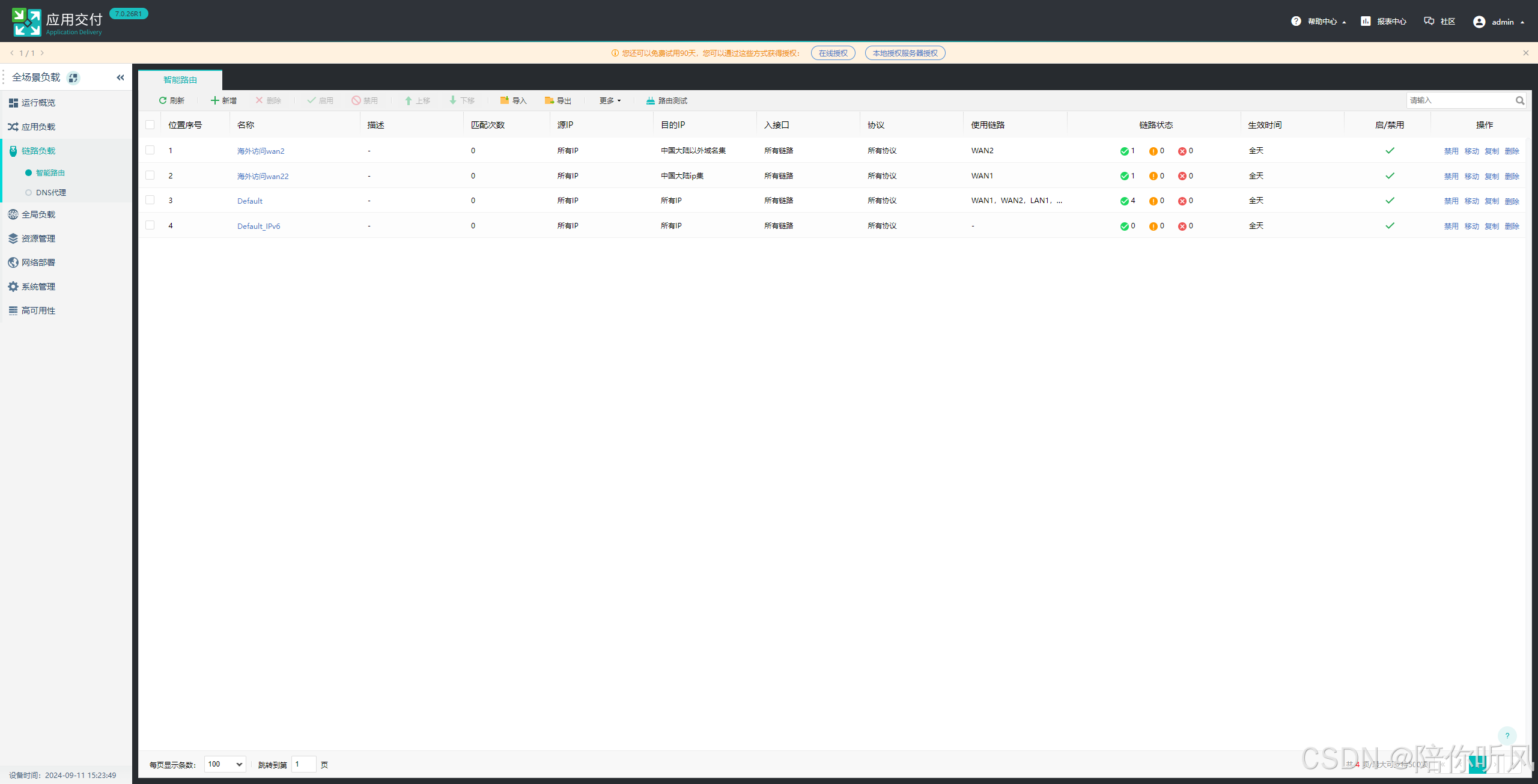
4、在链路负载中配置智能路由
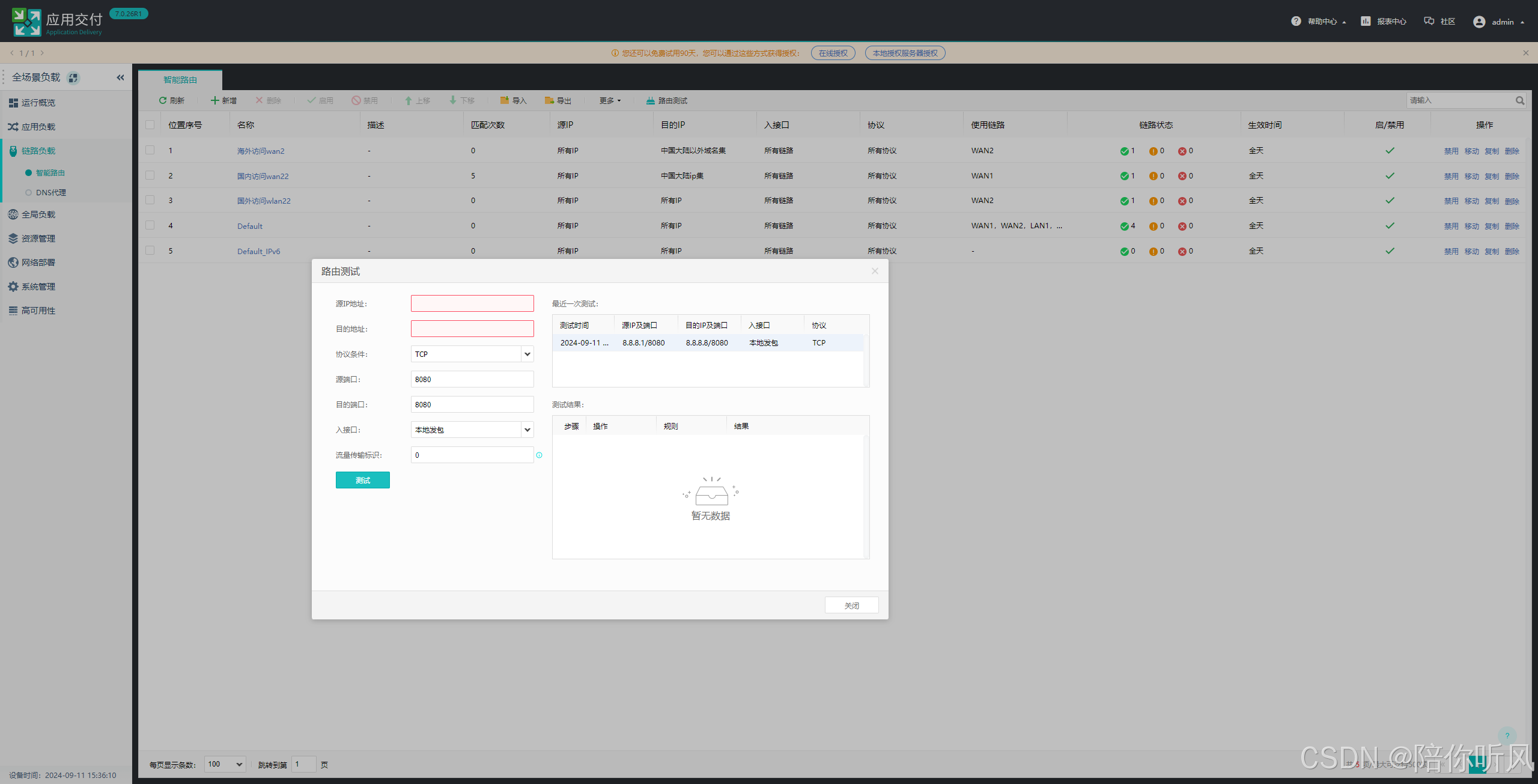
5、配置完成后进行路由测试
1、下载vAD虚拟化系统,导入vmware。启动后配置管理口地址,登录系统。申请试用授权,在授权管理里导入激活。
2、规划网络网口,进行网口配置。
网络部署-网络接口中配置接口
网络部署-静态路由中配置路由
网络部署-地址转换中配置源地址转换
3、配置路由优先级,智能路由优先级高于主路由表
4、在链路负载中配置智能路由
5、配置完成后进行路由测试
 5869
9578
1万+
5869
9578
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





























