






impala
是cloudera提供的一款高效率的 sql 查询工具,比 sparksql 还要更加快速,号称是当前大数据领域最快的查询sql工具,其来自于cloudera,后来贡献了apache,impala是参照谷歌的新三篇论文(Caffeine--网络搜索引擎、Pregel--分布式图计算、Dremel--交互式分析工具)当中的Dremel实现而来,其中旧三篇论文分别是(BigTable,GFS,MapReduce)分别对应HBase 、 HDFS 以及 MapReduce。
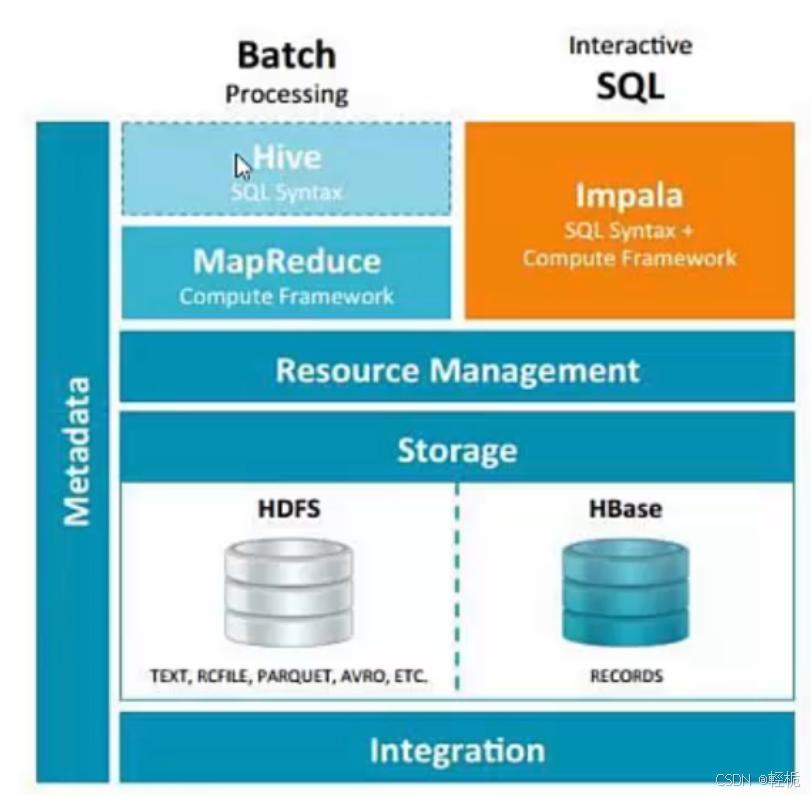
impala是基于hive的大数据分析查询引擎,工作底层依赖于hive,使用内存进行计算,兼顾数据仓库,具有实时,批处理,多并发等优点,是一个实时的sql交互查询工具。impala类似于hive操作方式,只不过执行效率得到极大提高(hive适合于批处理查询的sql软件),是直接使用hive的元数据库metadata,其元数据存储在hive中的metastuore中,共用一套metastore,意味着impala 元数据都存储在 hive的 metastore 当中,并且 impala 兼容 hive 的绝大多数sql语法。所以安装impala必须先安装hadoop和Hive两个框架,保证hive 安装成功服务正常可靠,并且还要启动 hive 的 metastore 服务。
Hive 元数据包含用 Hive 创建的 database、table等元信息。元数据存储在关系型数据库中,如 Derby、MySQL等。客户端连接 metastore 服务,metastore 再去连按 MySQL 数据库来存取元数据。有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接metastore服务即可。impala和hive最大不同在于不再把sql编译成mr程序执行编译成执行计划数。
nohup hive --service metastore >>~/metastore.log 2>&1 &准备impala依赖包:(通过yun源)
linux121安装httpd服务器
新建测试页面
下载impala所需要的rpm包
使用httpd盛放依赖包
修改yum源配置file
Impala与Hive 都是构建在 Hadoop 之上的数据查询工具,各有不同的侧重适应面,从客户端使用来看Impala与 Hive 有很多的共同之处,如数据表元数据、ODBC/JDBC驱动、SQL语法、灵活的文件格式、存储资池等。但是 Impala 跟 Hive 最大的优化区别在于:没有使用 MapReduce 进行并行计算,虽然MapReduce 是非常好的并行计算框架,但它更多的面向批处理模式,而不是面向交互式的SQL执行。
impala vs hive
1、impala使用的优化技术
使用LLVM 产生运行代码,针对特定查询生成特定代码,同时使用Inline的方式减少函数调用的开销,加快执行效率。(C++特性)
充分利用可用的硬件指令(SSE4.2)。
更好的i/o调度,Impala 知道数据块所在的磁盘位置能够更好的利用多磁盘的优势,同时Impala支持直接数据块读取和本地代码计算checksum。
通过选择合适数据存储格式可以得到最好性能(Impala支持多种存储格式)。
最大使用内存,中间结果不写磁盘,及时通过网络以stream 的方式传递。
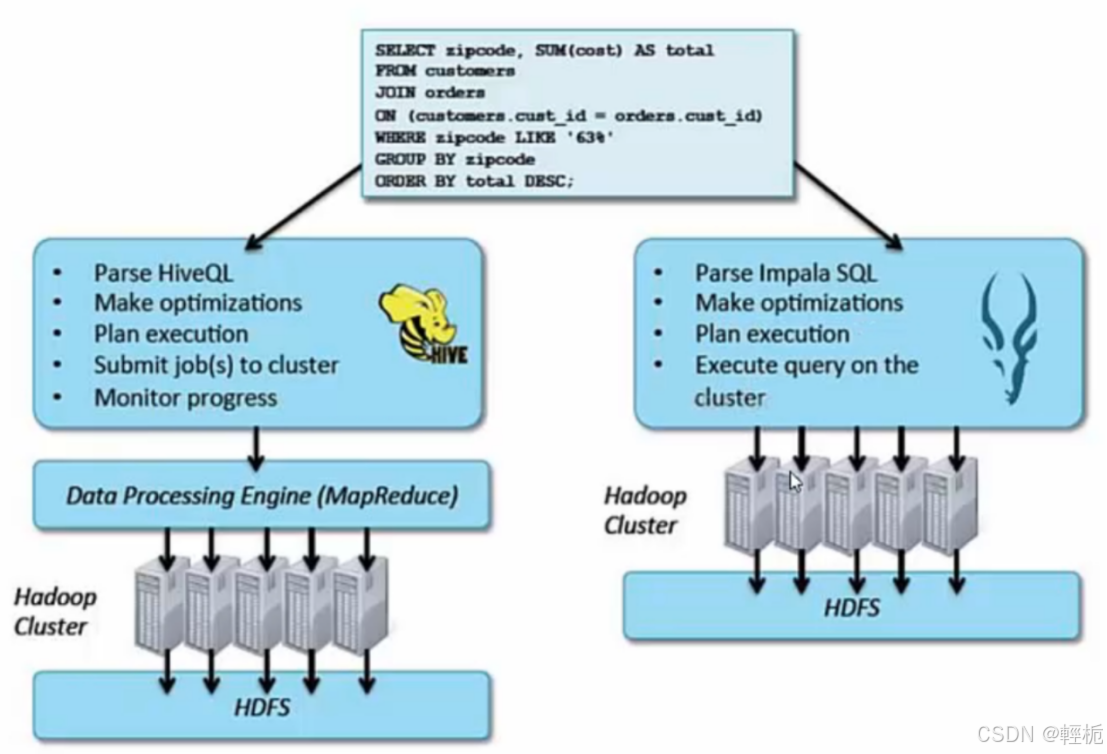
2、与MapReduce 相比,Impala把整个查询分成一执行计划树,而不是一连串的MapReduce 任务。Impala使用服务的方式避免每次执行查询都需要启动的开销,即相比Hive没了MapReduce启动时间。
Hive:依赖于MapReduce执行框架,执行计划分成map->shuffle->reduce->map->shuffle->reduce…的模型。如果一个 Query 会 被编译成多轮 MapReduce,则会有更多的写中间结果。由于MapReduce 执行框架本身的特点,过多的中间过程会增加整个Query的执行时间。Impala:把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询,而不用像Hive那样把它组合成管道型的map->reduce 模式,以此保证 lmpala有更好的并发性和避免不必要的中间 sort 与shuffle.
3、在分发执行计划后,Impala用拉式获取数据的方式获取结果,把结果数据组成按执行树流式传递汇集,减少了把中间结果写入磁盘的步骤,再从磁盘读取数据的开销。hive采用推的方式每一个节点计算完成后将数据主动推给后续节点。
4、Hive:在执行过程中如果内存放不下所有数据,则会使用外存,以保证 Query能顺序执行完。每一轮 MapReduce 结束,中间结果也会写入HDFS中,同样由于MapReduce执行架构的特性,shuffle过程也会有写本地磁盘的操作。
Impala:在遇到内存放不下数据时,版本 1.0.1是直接返回错误,而不会利用外存,以后版本应该会进行改进。这使用得Impala目前处理Query会受到一定的限制,最好还是与 Hive 配合使用。
5、Hive:任务调度依赖于 Hadoop的调度策略;Impala:调度由自己完成,目前只有一种调度器 simple-schedule,它会尽量满足数据的局部性,扫描数据的进程尽量靠近数据本身所在的物理机器。
6、Hive:依赖于Hadoop 的容错能力。
Impala:在查询过程中,没有容错逻辑,如果在执行过程中发生故障,则直接返回错误(这与Impala的设计有关,因为Impala 定位于实时查询,一次查询失败, 再查一次即可)
Impala: 避免数据落盘,不用每次I/O磁盘
处理进程无需每次启动
默认不用对数据key排序
遇到错误只能重新启动,没有容错
查询速度快,实时大批量数据分析
做到百节点级,并发查询达到20个左右,基于MPP架构
资源不能通过YARN统一实现资源管理调度
MPP:大规模并行处理,用于处理存储在hadoop里面的大量数据
性能最高的SQL引擎,提供类似于RDBMS的性能
在数据驻留时执行数据处理,不需要对存储在hadoop上的数据进行数据转换和数据移动
不提供对任何序列化和反序列化的支持
只能读取文本文件,不支持二进制文件
当新的record添加到HDFS中的数据目录时,该表需要被更新
Hive: 基于批处理的Hadoop的MapReduce,通过MR引擎实现所有中间结果,并进行落盘
但是有很好的容错性能
Impala架构:
Impalad服务由:query planner,query coordinator和query executor三个模块组成,分布式查询引擎构成
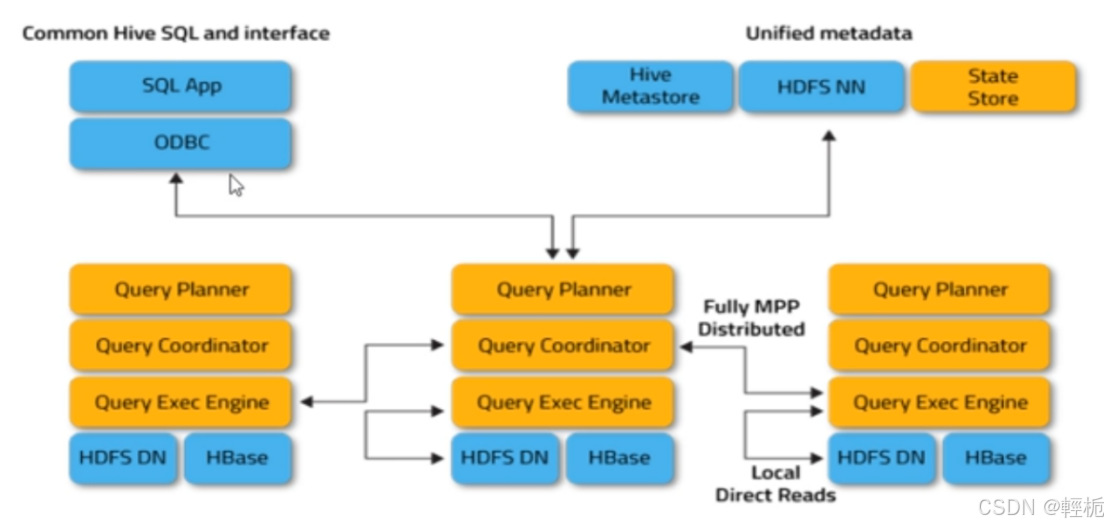
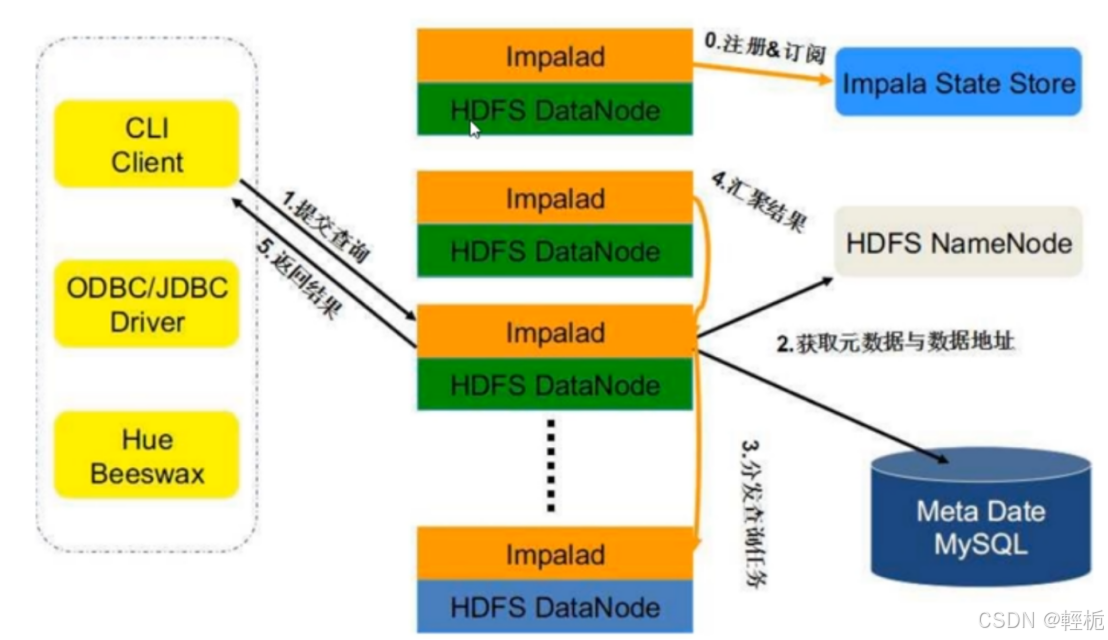
Impala 主要由Impalad、State Store、Catalogd 和 CLI 组成,可以集群部署。
impalad(impala server):可以部署多个不同机器上,是核心组件(守护进程),负责读写数据文件,接受来自impala-shell,JDBC,ODBC查询请求,与集群其他impalad分布式完成查询任务,返回给中心协调者;通常与datanode部署在同一个节点,方便数据本地计算,通过短路读取数据(client直接读取file data,提升性能,客户端和数据放在同一主机),负责具体执行本次查询sql的impalad称之为Coordinator。每个impala server都可以对外提供服务。由 Impalad 进程表示,它接收客户端的查询请求(接收查询请求的Impalad为coordinator,Coordinator 通过JNI 调用java前端解释SQL查询语句,生成查询计划树,再通过调度器把执行计划分发给具有相应数据的其它Impalad 进行执行(可以将查询提交到专用impalad或以负载平衡方式提交到集群中的另外一个impalad)),读写数据,并行执行查询,并把结果通过网络流式的传送回给 Coordinator,由 Coordinator 返回给客户端。同时 impalad 也与 State Store 保持连接,用于确定哪个Impalad 是健康和可以接受新的工作。在Impalad中会启动三个ThriftServer:beeswax server(连接客户端),hs2 server(借用 Hive 元数据),be server(lmpalad 内部使用)和一个impalaServer 服务。
Impala State Store:健康监控角色,跟踪集群中的Impalad 的健康状态及位置信息,保存impalad的状态信息 监视其健康状态,statestored 进程表示,它通过创建多个线程来处理Impalad的注册订阅和与各Impalad 保持心跳连接,各Impalad 都会缓存一份 State Store 中的信息,当 StateStore 离线后(lmpalad 发现 StateStore 处于离线时,会进入recovery模式,反复注册,当 State Store 重新加入集群后,自动恢复正常,更新缓存数据)因为Impalad有 State Store 的缓存仍然可以工作,但会因为有些lmpalad 失效了,而已缓存数据无法更新,导致把执行计划分配给了失效的impalad,导致查询失效;如果由于任何原因导致节点故障,statestore将更新所有节点关于此故障,一旦此类通知可用于其他impalad,其他impala守护进程不会向受影响的节点分配任何进一步的查询。
Catalogd:作为metadata访问网关,从Hive Metastore等外部 catalog 中获取元数据信息,放到impala 自己的 catalog 结构中,同步hive的元数据到impala自己的元数据中。impalad 执行 ddl 命令时通过catalogd 由其代为执行,该更新则由statestored 广播。管理和维护元数据Hive,把impala-sever更新的元数据通知给其他impala-sever,Cataloged日志监控。
CLI:用户操作impala的方式(impala shell、jdbc、hue ),提供给用户查询使用的命令行工具 impalad shell是用python实现
JDBC: JAVA程序访问关系型数据库的API接口
加载数据库驱动
连接数据库:getconnection
创建操作对象:statement对象或者preparedstatement对象来执行SQL语句
处理查询结果:resultset对象处理从数据库返回的结果
释放资源:Close()方法释放资源
ODBC:开放数据库互连,定义访问数据库的API规范,API可以独立于不同厂商的DBMS,使用ODBC可以使得各种类型的数据库进行交互。ODBC driver manager
Hue:
单机查询任务:
分布式并行查询执行计划:
impala 查询处理流程
impalad分为java前端(接收解析sql编译成执行计划树),c++后端(负责具体的执行计划树操作)
impala sql--->impalad(Coordinator)--->调用java前端编译sql成计划树--->以Thrift数据格式返回给C++后端--->根据执行计划树、数据位于路径(libhdfs和hdfs交互)、impalad状态分配执行计划 查询---->汇总查询结果---->返回给java前端---->用户cli
跟hive不同就在于整个执行中已经没有了mapreduce程序的存在
业务系统需要从 MySQL 数据库里读取 500w 数据行进行处理,在处理数据时大批量数据组装成excel很慢处理方式,(响应时间长,全量加载慢,加载到内存导致进程oom,不可用):
自定义线程池,用多线程
Countdownlatch
大分页sql优化
并发处理
优化思路:
- 用户角度:暂时没什么优化
- db:全量查询的sql好像也没有什么优化的,其实也有,查询的时候尽量只写需要的字段
- 导出处理环节:之前一个线程干活,那多几个线程干活可不可以呢?(确实可以)
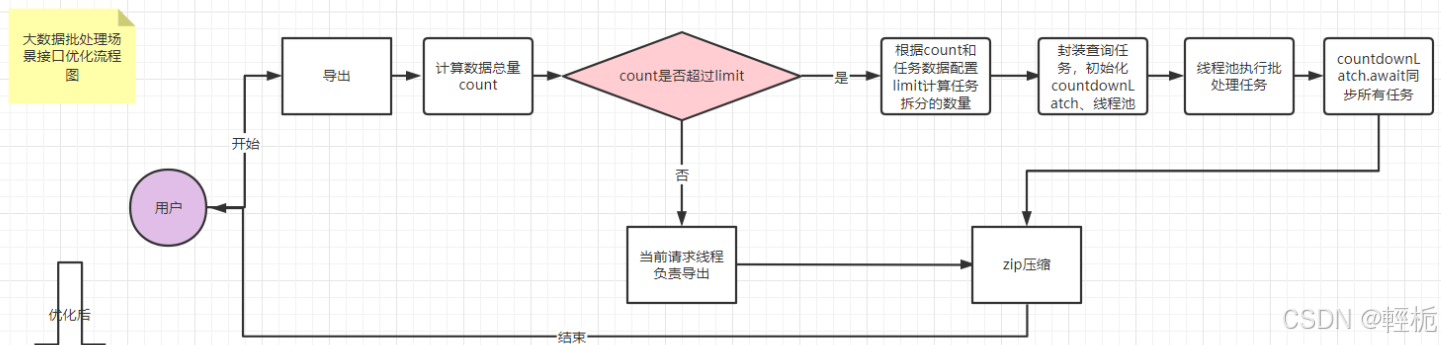
可以通过配置的limit字段(代码里用的是exportExcel字段)来进行任务的拆分
任务拆分后,称之为task,此时发现每个任务就是一个大的page分页查询,针对大的分页查询sql使用limit字段会全表扫描,所以建议先把所有任务分割点的主键查出来,sql通过任务的主键范围来进行查询
优化效果
(1)避免了导出数据全部加载到内存导致oom的潜在风险
(2)提高了导出接口的响应速度,在硬件条件以及测试数据不变的情况下,响应速度快了10倍
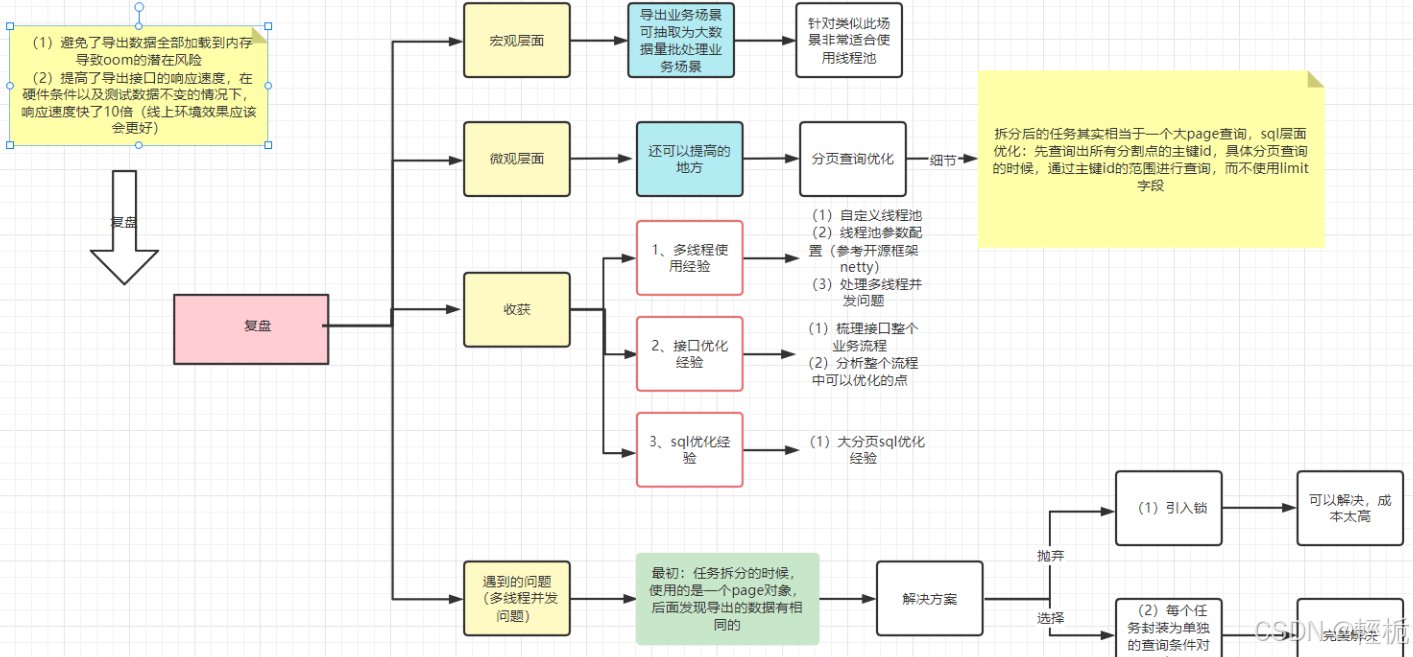
压缩工具依赖
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-compress</artifactId>
<version>1.18</version>
</dependency>
核心代码
public void export(@ApiIgnore Searchable searchable, HttpServletResponse response, String rule,@ApiIgnore@CurrentUser User user){
SearchFilter searchFilter = null;
LogController.checkUser(user,searchFilter,searchable);
if (rule!= null && rule.trim().length() > 0){
String[] s = rule.split("_");
searchable.addSort("desc".equals(s[1].toLowerCase())?Direction.DESC:Direction.ASC,s[0]);
}
final int count = loginLogService.count(searchable);
if (exportExcel == 0){
//默认1000
exportExcel = SINGLE_MAX_COUNT;
}
//1、创建压缩目录
String tmpPath = zipDir + "/" + uuidUtil.getID16();
File tmp = new File(tmpPath);
// 没有就创建
if(!tmp.exists()) tmp.mkdirs();
if (count <= exportExcel){
//没有超过单线程导出数量阈值
loginLogService.export(loginLogService.findList(searchable),1L,tmpPath);
}else {
//批处理
int flag = count%exportExcel;
final int tasks = (count/exportExcel) + (flag == 0?0:1);
CountDownLatch latch = new CountDownLatch(tasks);
List<SearchRequest> taskQueue = new ArrayList<>();
for (int i = 1; i <= tasks; i++) {
final SearchRequest searchRequest = new SearchRequest();
searchRequest.setPage(i,exportExcel);
searchRequest.addSearchFilters(searchable.getSearchFilters());
searchRequest.addSearchFilter(searchFilter);
searchRequest.addSort(searchable.getSorts());
taskQueue.add(searchRequest);
}
taskQueue.forEach(task->{
ThreadPoolFactoryUtil.getInstance().submit(()->{
loginLogService.export(loginLogService.findPageList(task).getRecords(), task.getPage().getPn(), tmpPath);
latch.countDown();
});
});
try {
latch.await();
} catch (InterruptedException e) {
throw new CustomBusinessException("批处理导出异常!");
}
taskQueue = null;
}
//打包压缩
try {
fileUtils.doCompress("登录日志.zip", tmpPath, response);
} catch (IOException e) {
throw new CustomBusinessException("打包压缩失败!");
}
//删除临时目录
FileUtils.deleteFileDictory(new File(tmpPath));
}
FileUtils工具类
package com.unionbigdata.rdc.sys.util;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.compress.archivers.ArchiveEntry;
import org.apache.commons.compress.archivers.zip.Zip64Mode;
import org.apache.commons.compress.archivers.zip.ZipArchiveEntry;
import org.apache.commons.compress.archivers.zip.ZipArchiveOutputStream;
import org.springframework.stereotype.Component;
import javax.servlet.http.HttpServletResponse;
import java.io.*;
import java.net.URLEncoder;
@Slf4j
@Component
public class FileUtils {
public void doCompress(String zipName, String tmpPath, HttpServletResponse response) throws IOException {
File files = new File(tmpPath);
//不存在或者不是文件夹(不考虑当前是文件的情况)的情况
if(!files.exists()||!files.isDirectory()){
return;
}
//设置响应头,控制浏览器下载该文件
response.reset();
response.setHeader("Content-Type","application/octet-stream");
response.setHeader("Content-Disposition",
"attachment;filename="+ URLEncoder.encode(zipName, "UTF-8"));
OutputStream out = response.getOutputStream();
File[] fileslist = files.listFiles();
ZipArchiveOutputStream zous = new ZipArchiveOutputStream(out);
zous.setUseZip64(Zip64Mode.AsNeeded);
for (File file : fileslist) {
String fileName = file.getName();
InputStream inputStream = new FileInputStream(file);
ByteArrayOutputStream baos = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int len;
while ((len = inputStream.read(buffer)) != -1) {
baos.write(buffer, 0, len);
}
if (baos != null) {
baos.flush();
}
byte[] bytes = baos.toByteArray();
//设置文件名
ArchiveEntry entry = new ZipArchiveEntry(fileName);
zous.putArchiveEntry(entry);
zous.write(bytes);
zous.closeArchiveEntry();
if (baos != null) {
baos.close();
}
inputStream.close();
}
if(zous != null) {
zous.close();
}
if (out != null) {
out.flush();
out.close();
}
}
public static void deleteFileDictory(File file) {
//文件的情况
if (file.isFile()) {
file.delete();
}
//文件夹的情况
if (file.isDirectory()) {
File[] files = file.listFiles();
for (File dfile : files) {
deleteFileDictory(dfile);
}
file.delete();
}
}
}
线程池
import org.apache.commons.lang3.StringUtils;
import javax.validation.constraints.NotNull;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadFactory;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
public class ThreadPoolFactoryUtil {
private volatile static ThreadPoolExecutor instance;
private final static int threadCounts = Runtime.getRuntime().availableProcessors();
private final static int threadTasks = 200;
private ThreadPoolFactoryUtil(){}
public static ThreadPoolExecutor getInstance(){
if (instance == null){
synchronized (ThreadPoolFactoryUtil.class){
if (instance == null){
instance = new ThreadPoolExecutor(threadCounts, threadCounts, 1, TimeUnit.MINUTES, new LinkedBlockingQueue<>(threadTasks),new MyThreadFactory("批处理导出"));
}
}
}
return instance;
}
public static void close(){
if (instance == null )
return;
instance.shutdown();
}
static class MyThreadFactory implements ThreadFactory{
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
MyThreadFactory(String name) {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = (StringUtils.isBlank(name)?"pool-":name+"-") +
poolNumber.getAndIncrement() +
"-thread-";
}
@Override
public Thread newThread(@NotNull Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}
}
# 线程池关闭
//注册jvm钩子函数,关闭线程池资源
Runtime.getRuntime().addShutdownHook(new Thread(ThreadPoolFactoryUtil::close));
需要迁移数据,导出数据,批量处理数据,(游标查询会比select查询更快fetchsize)
常规查询:一次性读取 500w 数据到 JVM 内存中,或者分页读取
流式查询:每次读取一条加载到 JVM 内存进行业务处理
游标查询:和流式一样,通过 fetchSize 参数,控制一次读取多少条数据
常规查询:默认情况下,完整的检索结果集会将其存储在内存中。在大多数情况下,这是最有效的操作方式,更易于实现。假设单表 500w 数据量,一般不会一次性加载到内存中,而是采用分页的方式。
@Test
# 为了监控JVM,所以没有采用分页,一次性将数据载入内存中
public void generalQuery() throws Exception {
// 1核2G:查询一百条记录:47ms
// 1核2G:查询一千条记录:2050 ms
// 1核2G:查询一万条记录:26589 ms
// 1核2G:查询五万条记录:135966 ms
String sql = "select * from wh_b_inventory limit 10000";
ps = conn.prepareStatement(sql);
ResultSet rs = ps.executeQuery(sql);
int count = 0;
while (rs.next()) {
count++;
}
System.out.println(count);
}JVM监控
将内存调小-Xms70m -Xmx70m
整个查询过程中,堆内存占用逐步增长,并且最终导致OOM:
java.lang.OutOfMemoryError: GC overhead limit exceeded
1、频繁触发GC
2、存在OOM隐患
流式查询需要注意的是:必须先读取(或关闭)结果集中的所有行,然后才能对连接发出任何其他查询,否则将引发异常,其 查询会独占连接。从测试结果来看,流式查询并没有提升查询的速度
@Test
public void streamQuery() throws Exception {
// 1核2G:查询一百条记录:138ms
// 1核2G:查询一千条记录:2304 ms
// 1核2G:查询一万条记录:26536 ms
// 1核2G:查询五万条记录:135931 ms
String sql = "select * from wh_b_inventory limit 50000";
statement = conn.createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
statement.setFetchSize(Integer.MIN_VALUE);
ResultSet rs = statement.executeQuery(sql);
int count = 0;
while (rs.next()) {
count++;
}
System.out.println(count);
}JVM监控
将堆内存调小-Xms70m -Xmx70m,发现即使堆内存只有70m,却依然没有发生OOM
游标查询:在数据库连接信息里拼接参数 useCursorFetch=true,其次设置 Statement 每次读取数据数量,比如一次读取 1000
从测试结果来看,游标查询在一定程度缩短了查询速度
@Test
public void cursorQuery() throws Exception {
Class.forName("com.mysql.jdbc.Driver");
// 注意这里需要拼接参数,否则就是普通查询
conn = DriverManager.getConnection("jdbc:mysql://101.34.50.82:3306/mysql-demo?useCursorFetch=true", "root", "123456");
start = System.currentTimeMillis();
// 1核2G:查询一百条记录:52 ms
// 1核2G:查询一千条记录:1095 ms
// 1核2G:查询一万条记录:17432 ms
// 1核2G:查询五万条记录:90244 ms
String sql = "select * from wh_b_inventory limit 50000";
((JDBC4Connection) conn).setUseCursorFetch(true);
statement = conn.createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
statement.setFetchSize(1000);
ResultSet rs = statement.executeQuery(sql);
int count = 0;
while (rs.next()) {
count++;
}
System.out.println(count);
}JVM监控
将堆内存调小-Xms70m -Xmx70m,发现在单线程情况下,游标查询和流式查询一样,都能很好的规避OOM,并且游标查询能够优化查询速度。
RowData
ResultSet.next() 的逻辑是实现类 ResultSetImpl 每次都从 RowData 获取下一行的数据。RowData 是一个接口,实现逻辑图为:
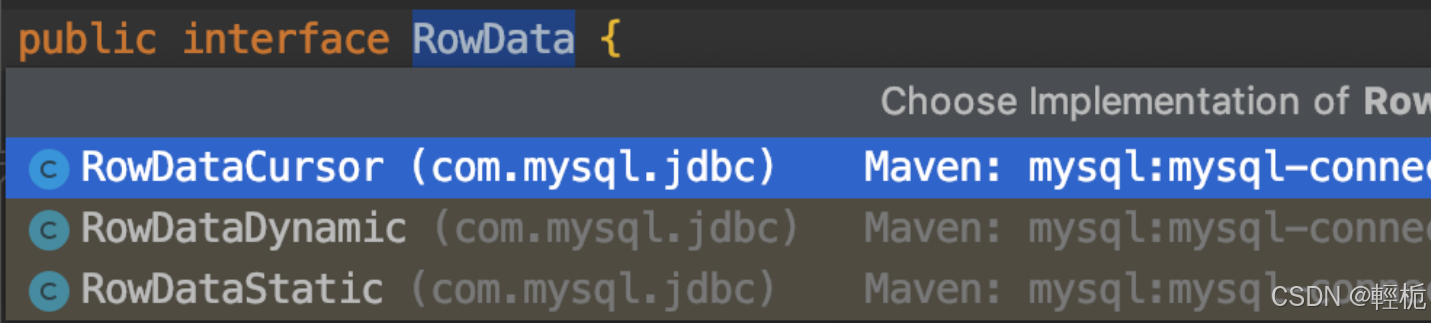
1、 RowDataStatic
默认情况下 ResultSet 会使用 RowDataStatic 实例,在生成 RowDataStatic 对象时就会把 ResultSet 中所有记录读到内存里,之后通过 next() 再一条条从内存中读
2、RowDataDynamic
当采用流式处理时,ResultSet 使用的是 RowDataDynamic 对象,而这个对象 next() 每次调用都会发起 IO 读取单行数据
3、RowDataCursor
RowDataCursor 的调用为批处理,然后进行内部缓存,流程如下:
首先会查看自己内部缓冲区是否有数据没有返回,如果有则返回下一行
如果都读取完毕,向 MySQL Server 触发一个新的请求读取 fetchSize 数量结果
并将返回结果缓冲到内部缓冲区,然后返回第一行数据
总结来说就是:
默认的 RowDataStatic 读取全部数据到客户端内存中,也就是 JVM;
RowDataDynamic 每次 IO 调用读取一条数据;
RowDataCursor 一次读取 fetchSize 行,消费完成再发起请求调用。
JDBC 通信原理
JDBC 与 MySQL 服务端的交互是通过 Socket 完成的,对应到网络编程,可以把 MySQL 当作一个 SocketServer,因此一个完整的请求链路应该是:
JDBC 客户端 -> 客户端 Socket -> MySQL -> 检索数据返回 -> MySQL 内核 Socket Buffer -> 网络 -> 客户端 Socket Buffer -> JDBC 客户端
1、generalQuery 普通查询
普通查询会将当次查询到的所有数据加载到JVM,然后再进行处理。
如果查询数据量过大,会不断经历 GC,然后就是内存溢出
2、streamQuery 流式查询
服务端准备好从第一条数据开始返回时,向缓冲区怼入数据,这些数据通过TCP链路,怼入客户端机器的内核缓冲区,JDBC会的inputStream.read()方法会被唤醒去读取数据,唯一的区别是开启了stream读取的时候,每次只是从内核中读取一个package大小的数据,只是返回一行数据,如果1个package无法组装1行数据,会再读1个package。
3、cursorQuery 游标查询
当开启游标的时候,服务端返回数据的时候,就会按照fetchSize的大小返回数据了,而客户端接收数据的时候每次都会把换缓冲区数据全部读取干净,假如数据有1亿数据,将FetchSize设置成1000的话,会进行10万次来回通信;
由于MySQL方不知道客户端什么时候将数据消费完,而自身的对应表可能会有DML写入操作,此时MySQL需要建立一个临时空间来存放需要拿走的数据。
因此对于当你启用useCursorFetch读取大表的时候会看到MySQL上的几个现象:
1.IOPS飙升
2.磁盘空间飙升
3.客户端JDBC发起SQL后,长时间等待SQL响应数据,这段时间就是服务端在准备数据
4.在数据准备完成后,开始传输数据的阶段,网络响应开始飙升,IOPS由“读写”转变为“读取”。
IOPS (Input/Output Per Second):磁盘每秒的读写次数
5.CPU和内存会有一定比例的上升
Impala数据类型:
bigint boolean char decimal double float int smallint string timestamp varchar array(可变数量的有序元素) map(可变数量的键值对) struct(单个项目的多个字段)
Metastore(元数据、元存储):用MySQL或者postgresql数据库存储表定义和列信息这些元数据。当表定义或元数据更新时,其他impala后台需要检索最新元数据更新其源数据缓存,然后对相关表发出新查询。
note:Hive对于元数据的更新无法被impala感知,但是impala对源数据修改可以被hive感知;
Impala同步hive元数据:invalidated metadata # 这样impala就可识别到hive中数据的变化
| hive | impala | 长度 |
| Tinyint | Tinyint | 1byte有符号整数 |
| smallint | smallint | 2byte有符号整数 |
| int | int | 4byte有符号整数 |
| bigint | bigint | 8byte有符号整数 |
| boolean | boolean | 布尔类型true or flase |
| float | float | 单精度浮点数 |
| double | double | 双精度浮点数 |
| string | string | 字符系列 |
| timestamp | timestamp | 事件类型 |
| binary | 不支持 | 字节数组 |
外部shell:
Impala-shell -h 调用使用帮助信息
Impala-shell -i hadoop103:连接到其他主机
Impala-shell -q ‘select * from table’; 不进入sql命令行使用sql语句会返回查询结果
Impala-shell -f file.sql执行文件里面的查询sql语句,文件里面的sql语句用;分割
Impala-shell -f file.sql -o file.txt 将查询结果输出到指定文件中,保留格式(有框)
Cat file.txt 查看当前文件有格式形式的内容
Impala-shell -f file.sql -B -o file.txt 将查询结果输出到指定文件中,不需要格式,只保留结果
Impala-shell -f file.sql -B --print header -o file.txt 将查询结果输出到指定文件中,不需要格式,保留结果和表头
Impala-shell -f file.sql -B --output_delimiter=’;’ -o file.txt 将查询结果输出到指定文件中,不需要格式,只保留结果,结果中不再以默认的tab分割,以;分割
优化sql语句时候使用执行计划
Impala-shell -p 查看每条sql语句底层执行计划
Impala-shell --quiet 减少输出的query部分,显示结果为主,不显示查询语句,查询提交部分
Impala-shell -v 显示版本号
Impala-shell -r 在hive中添加了元数据,impala无法感知,需要进行刷新(全局刷新),不到万不得已不要用
Impala-shell -c -f file.sql 如果sql文件中有错误,-c会跳过错误的sql继续执行,并把错误语句记录下来
vim file.sql 创建/查看并编辑要运行的sql文件
:wq保存退出编辑,慎用 :q仅退出
rm path/file.sql删除创建的sql文件echo $LANG -- Linux下检查当前终端语言
export =en_US.UTF-8 or zh_CN.UTF-8 -- 转换成其他形式
locale -- 检查服务器字符集设置
export LANG = en_US.UTF-8 export LC_ALL = en_US.UTF-8 --设置字符集显示
-- 虚拟机下无法直接拖文件粘贴,需要先copy再paste内部shell:
compute优化时使用,查看sql语句执行的时间,计算效率
describe table;展示表结构
explain select * from table; 显示执行计划
profile select * from table; 详细的执行计划,只打印最后一条的执行计划
hive 中dfs 读取当前路径
!读取本地路径
Shell hadoop fs -ls 显示当前路径
Shell <shell>不退出impala shell执行外部shell命令
use database;
version;会同时显示inpala-shell 和sever的版本
connect hadoop103; 连接其他hadoop
history;打印所有历史输入命令
set/unset设置属性
show tables;
在hive中插入Insert into student values(2,’qw’);
但是在impala中无法感知select仍然是原来记录;
Invalidate metadata;全量刷新元数据(慎用,等同Impala-shell -r)
Refresh tablename;增量刷新元数据库;快很多DDL:
创建database:
create database if not exists database_name comment ‘’ location hdfs path;不支持with DBPROPERTIE...语法;
查询:
show database;
show database like ‘%im%’;
desc databases database_name;删除:
drop database db_name; -- 前提是删除库中不能有任何数据
drop database db_name cascade; -- 不管有没有数据都删除
-- 当db_name被use时,无法删除
--impala不支持alter db_name语法;创建表:
内部表:
create table student(
Id int, name string, birth timestamp
)
row format delimited fields terminated by ‘\t’
lines terminated by '\n';外部表:
create external table t1(
id string,name string,age int
)
row fromat delimited fields terminated by ‘,’
lines terminated by '\n'
Location ‘/user/impala/t1’;-- 创建t2;
Insert overwrite table t2 select * from t1;
Alter table old_db_name rename to new_db_name;分区表:
create table student_par(
Id int, name string
) partitioned by (age int) --分区表字段
row format delimited
fields terminated by ‘\t’
lines terminated by '\n'
location ‘./tmp/databases_name/table_name’;默认不指定的情况下Impala创建的是内部表, Impala负责管理表和它关联的底层的数据文件。当删除impala内部表的时候, Impala会自动的删除该内部表对应的物理数据文件。如果指定 EXTERNAL子句, Impala将创建一张外部表。外部表对应的数据文件并非由Impa创建与管理。外部表创建语句只是将Impala的表定义指向已存在的数据文件,此时数据文件已经存在hdfs上。当我们删除外部表时, Impala不会删除外部表对应的物理数据文件。一般建外部表,偶尔需要用到临时变量时候建内部表.
添加数据:
分区表:
不会自动创建分区,先建分区再加载数据
Alter table student_par add partition (age=21);
load data inpath ‘/student.txt’ into table student_par partition (age=21);or 到 hdfs中先建分区
hdfs dfs -mkdir -p /external_table_name/partition_par
hdfs dfs -put data.dat /external_table_name/partition_par插入数据时会自动创建分区
Insert into table student_par partition (age=21) select * from stu;如果没有分区,load data 导入数据时不会自动创建分区
不支持直接load data inpth...
内部表:
准备数据文件data.dat 字段分隔符用制表符
将数据文件上传至hdfs: hdfs dfs -put data.dat /
进入impala-shell
>load data inpath ‘./data.dat’ into table table_name;外部表:
hdfs: hdfs dfs -put data.dat / external_table_namedesc table_name; -- 查看表信息
show create table table_name; -- 查看建表语句
desc formatted table_name; -- 确定是否是内外部表
show partitions external_partition_table; -- 查看分区
Secelt * from student_par where age = ‘1’; -- 查询分区下数据
alter table student add partition(age=22); -- 增加多个分区
alter table student drop partition(age=21); -- 删除分区
show partitions student; -- 查看分区Hive导入数据方式:
insert load put import location
Hadoop fs -mkdir -p/user/impala/table # 创建HDFS存放数据的路径
Hadoop fs -put user.csv/user/impala/table # 上传csv文件到table表中DML:
不支持insert overwrite ... 、imprt、export导出数据
一般用impala -o 数据量特别大不要用-B
Impala-shell -f file.sql -B --output_delimiter=’\t’ -o file.txt
impala-shell -q 'select * from dwd.grade1_cust_base_info LIMIT 1;' -- print 1 recordimpala不支持 cluster by(分区并排序) distribute by(分区) sort by
支持order by(排序) group by(分组)
不支持分桶表(抽样,针对file级别)
不支持collect_set(col)(行变量)、explode(col)函数
支持开窗函数:
Select name, orderdate , cost sum(cost) over (partition by month(orderdate)) from business;SELECT
referencing.name AS ReferencingObject,
referencing.type_desc AS ReferencingType,
referenced.name AS ReferencedObject,
referenced.type_desc AS ReferencedType
FROM
sys.sql_expression_dependencies AS dependencies
JOIN
sys.objects AS referencing ON dependencies.referencing_id = referencing.object_id
JOIN
sys.objects AS referenced ON dependencies.referenced_id = referenced.object_id
WHERE
referenced.name = 'BHYXYZB'; -- select dependence of table
or
WHERE
referencing.name = 'EXEC_EAST_BHYXYZB'
AND referencing.type = 'P'; -- select dependence table of procedure
SELECT ROUTINE_NAME FROM DataCenter.INFORMATION_SCHEMA.ROUTINES
WHERE ROUTINE_TYPE = 'PROCEDURE' AND ROUTINE_NAME NOT LIKE '%BKP%'
order by ROUTINE_NAME; -- select specific procedure-- LOOP循环是一种编程结构,用于重复执行一段代码,直到满足某个条件。
-- 循环可以用于执行重复的操作,但在 SQL Server 中,通常不用于遍历结果集,因为 SQL Server 的查询是基于集合的,循环往往会导致性能问题。
-- 在 SQL Server 中,不能直接使用LOOP来遍历查询结果集,因为 SQL Server 的 SQL 语言是基于集合的,而不是逐行处理的。可用WHILE循环,但这需要结合游标来使用。
-- 游标遍历所有存储过程
-- 游标是一种数据库对象,用于逐行处理查询结果集。它允许你在结果集中逐行移动,并对每一行执行操作。
-- 适合用于需要逐行处理的情况,比如需要对每一行进行复杂的操作,或者在处理结果集时需要保持状态。
-- 游标的性能通常较低,因为它们会在后台维护状态,并且逐行处理数据。
-- sql-sever
DECLARE ProcCursor CURSOR FOR
SELECT ROUTINE_NAME
FROM DataCenter.INFORMATION_SCHEMA.ROUTINES
WHERE ROUTINE_TYPE = 'PROCEDURE'
AND ROUTINE_NAME NOT LIKE '%BKP%'
ORDER BY ROUTINE_NAME;
OPEN ProcCursor;
FETCH NEXT FROM ProcCursor INTO @ProcName;
WHILE @@FETCH_STATUS = 0
BEGIN
-- define SQL
SET @SQL = '
INSERT INTO #Dependencies (ReferencingObject, ReferencingType, ReferencedObject, ReferencedType)
SELECT
referencing.name AS ReferencingObject,
referencing.type_desc AS ReferencingType,
referenced.name AS ReferencedObject,
referenced.type_desc AS ReferencedType
FROM
sys.sql_expression_dependencies AS dependencies
JOIN
sys.objects AS referencing ON dependencies.referencing_id = referencing.object_id
JOIN
sys.objects AS referenced ON dependencies.referenced_id = referenced.object_id
WHERE
referencing.name = ''' + @ProcName + '''
AND referencing.type = ''P'';';
-- exec SQL
EXEC sp_executesql @SQL;
FETCH NEXT FROM ProcCursor INTO @ProcName;
END
CLOSE ProcCursor;
DEALLOCATE ProcCursor;
SELECT * FROM #Dependencies;
DROP TABLE #Dependencies;-- powershell -- export data to local
# define connect str
$connectionString = "Server=YourServerName;Database=YourDatabase;Integrated Security=True;"
$query = "SELECT * FROM #Dependencies"
# use SqlConnection and SqlCommand
$connection = New-Object System.Data.SqlClient.SqlConnection($connectionString)
$command = New-Object System.Data.SqlClient.SqlCommand($query, $connection)
$connection.Open()
$reader = $command.ExecuteReader()
$table = New-Object System.Data.DataTable
$table.Load($reader)
$table | Export-Csv -Path "C:\path\to\your\file.csv" -NoTypeInformation
$connection.Close();函数:
1. 字符串函数
- SUBSTR(string, start, length): 提取子字符串;
SUBSTR函数。SUBSTR函数用于从字符串中提取子字符串 - string:要提取子字符串的原始字符串。
- start:从哪个位置开始提取。注意,Impala 中的起始位置是从 1 开始,而不是从 0 开始。
- length(可选):要提取的字符数。如果省略,则提取从
start开始到字符串末尾的所有字符。 -
substring(string a,int start,[int len]):返回从指定点开始的字符串部分,可选地指定最大长度
-
translate(string input,string from,string to):将字符串中的一些字符替换为其他字符;注:不能替换字符串,from字符串与to字符串一一对应,再替换 input字符串中所有对应字符
--截取字符串'hello world',从第6位开始
select substr('hello world',6) as substr;--world
--截取字符串'hello world',从第6位开始,长度为3
select substr('hello world',6,3) as substr; --wo
--截取字符串'hello world',从第6位开始
select substring('hello world',6) as substring; --world
--截取字符串'hello world',从第6位开始,长度为3
select substring('hello world',6,3) as substring; --wo
--将'world'替换为'cauchy',只能匹配到相同长度,即'cauch',且拆分为w->c,o->a,r->u,l->c,d->h
select translate('hello world','world','cauchy') as translate; --hecca cauch
--替换字符串中所有属于'world'的字符为'abcde'
select translate('hello world','world','abcde') as translate;--heddb abcdestart如果是负数,Impala 将从字符串的末尾开始计算。- 如果
start超出了字符串的长度,将返回一个空字符串。 length如果指定的长度超过了剩余字符串的长度,Impala 将只返回可用的字符。
- LENGTH(string): 返回字符串长度,忽略尾部空格 char_length(string a) = character_length(string a) = length
- CONCAT(string1, string2, ...): 连接字符串
-
concat_ws(string sep,string a,string b…) 拼接多个字符串,由指定分隔符分割
SELECT CONCAT('Hello', ' ', 'World');
-- 结果:Hello World
select concat_ws('-','hello','world') as concat_ws; --hello-world-
LOWER(string): 转换为小写
-
lcase(string a)返回全部为小写字符的字符串
select lower('Hello World') as lower;--hello world
select lcase('Hello World') as lcase;--hello world-
UPPER(string): 转换为大写 = ucase(string a)
-
initcap(string str)将字符串首字符大写并返回
select initcap('abc') as initcap;--Abc
instr(string str,string substr) 返回较长字符串中第一次出现子字符串的位置(从1开始)
select instr('abcdefg','bcd') as instr;--2
- REVERSE(string a): 反转字符串
- TRIM(string): 移除两端空格
-
btrim(string a)去除字符串之前和之后的任意个数的空格;
btrim(string a,string chars_to_trim)去掉左右两边指定的字符,去除第一个字符串之前和 之后的任何包含在第二个字符串中出现任意次数的字符
select btrim(' hello ') as btrim;--hello
select trim(' hello world ') as trim;--hello world
select btrim('xy hello zyzzxx','xyz') as btrim; --hello
select btrim('xyhelxyzlozyzzxx','xyz') as btrim; --helxyzlo- LTRIM(string): 移除左侧空格
- LTRIM(string,str_to_trim): 移除左侧指定字符
- RTRIM(string): 移除右侧空格
- RTRIM(string,str_to_trim): 移除右侧指定字符
select ltrim(' hello ') as ltrim;--hello___
select rtrim(' hello ') as rtrim;-- hello- REPLACE(string, search, replace): 替换子字符串
SELECT REPLACE('Impala is fast', 'fast', 'quick');
-- 结果:Impala is quick- REGEXP_REPLACE(string, pattern, replace): 使用正则表达式替换子字符串;替换字符串与正则表达式匹配项为新字符串并返回
SELECT REGEXP_REPLACE('Impala 123', '\\d+', '456');
-- 结果:Impala 456
--将字符串中任意的字符'b'替换为'xyz'
select regexp_replace('aaabbbaaa','b+','xyz');--aaaxyzaaa
--将字符串中任意的非数字字符替换为''(空)
select regexp_replace('123-456-789','[^[:digit:]]','');--123456789split_part(string source,string delimiter,bigint n)以delimiter字符串作为拆分项,取第n个字符串返回
--以','为分隔符拆分'x,y,z'并返回第1个字符串
select split_part('x,y,z',',',1);--x
--以','为分隔符拆分'x,y,z'并返回第2个字符串
select split_part('x,y,z',',',2);--y
--以','为分隔符拆分'x,y,z'并返回第3个字符串
select split_part('x,y,z',',',3);--z- REGEXP_EXTRACT(string, pattern, index): 使用正则表达式提取子字符串
regexp_extract(string subject,string pattern,int index)返回通过正则表达式提取的字符串,
用\字符进行转义,所以\d需要\d,也可以采用[[:digit:]]
SELECT REGEXP_EXTRACT('Impala 123', '\\d+', 0);
-- 结果:123
select regexp_extract('abcdef123ghi456jkl','.*?(\\d+)',0);----匹配任意字符以数字结尾,返回匹配的整个字符串
--abcdef123ghi456
select regexp_extract('abcdef123ghi456jkl','.*?(\\d+)',1);----匹配任意字符以数字结尾,只返回匹配的第一个值
--456
select regexp_extract('AbcdBCdefGHI','.*?([[:lower:]]+)',0);--匹配任意字符以小写字母结尾,返回匹配的整个字符串
--AbcdBCdef
select regexp_extract('AbcdBCdefGHI','.*?([[:lower:]]+)',1);----匹配任意字符以小写字母结尾,只返回匹配的第一个值
--defregexp_like(string source,string pattern,[string options])
返回true或者false,表示字符串是否包含正则表达式的值
options参数:
- c: 区分大小写匹配(默认)
- i:不区分大小写
- m:多行匹配
- n:换行符匹配
--判断字符'foo'是否包含'f'
select regexp_like('foo','f');--true
--判断字符'foo'是否包含'F'
select regexp_like('foo','F');--false
--判断字符'foo'是否包含'f',设置参数不区分大小写
select regexp_like('foo','F','i');--true
- ASCII(string): 只返回第一个字符的 ASCII 码
- char(int)返回ASCII 码数值对应的字母
- CHAR_LENGTH(string): 返回字符数
- SPACE(n): 返回 n 个空格字符串
- FIND_IN_SET(string, set): 查找某个字符串在一个以逗号为分隔符的列表中第一次出现的位置(以1为起点),如果查询不到或查询字符串中出现’,’(逗号),返回则为0
SELECT FIND_IN_SET('b', 'a,b,c,d');
-- 结果:2
select find_in_set(',','a,b,c,d,e,f,g') as find_in_set;-- 0字符加密:
select base64encode('hello world') as encoded; --base64encode(string str)
select base64decode('aGVsbG8gd29ybGQ=') as decoded; --base64decode(string str)select chr(97) as chr; --chr(int character_code) 返回数值ascii码对应的字符
locate(string substr,string str,[int pos])返回字符串中第一次出现子字符串的位置(从1开始),可指定位置
instr(string str, string substr, bigint position)查询数组中指定字符串开始位置
select locate('bc','abcdefgabc') as locate; --2
select locate('bc','abcdefgabc',3) as locate;--9lpad(string str,int len,string pad)返回更改了长度的第一个字符串,如果小于长度,则用pad字符串在左边补齐,如果大于长度,则从左边截取对应长度字符串返回
select lpad('hello world',7,'/') as lpad;--hello w
select lpad('hello world',13,'/') as lpad;--//hello worldrpad(string str,int len,string pad)返回更改了长度的第一个字符串,如果小于长度,则用pad字符串在右边补齐,如果大于长度,则从左边截取对应长度字符串返回
select rpad('hello world',7,'/') as rpad;--hello w
select rpad('hello world',13,'/') as rpad;--hello world//strleft(string a,int num_chars)截取字符串,返回左边的n个字符
strright(string a,int num_chars)截取字符串,返回右边的n个字符
--从左边截取字符串'hello world',返回长度为4的字符串
select strleft('hello world',4) as strleft;--hell
--从右边截取字符串'hello world',返回长度为4的字符串
select strright('hello world',4) as strright;--orld2. 数学函数
- ABS(number): 返回绝对值
- CEIL(number) / CEILING(number): 向上取整
- FLOOR(number): 向下取整
- ROUND(number, scale): 四舍五入
- RAND(): 返回一个随机数
- SQRT(number): 返回平方根
- POW(number, power) / POWER(number, power): 幂运算
- EXP(number): 返回 e 的 number 次幂
- LN(number): 返回自然对数
- LOG10(number): 返回以 10 为底的对数
- SIGN(number): 返回数的符号
- TRUNC(number, scale): 用于截断数字的小数位的函数
SELECT TRUNC(123.4567, 2); -- 保留小数点后的位数
-- 结果:123.45
SELECT TRUNC(123.4567, 0); -- 截断到整数部分
-- 结果:123
SELECT TRUNC(123.4567, -1); -- 负 scale 的情况
-- 结果:120
3. 日期和时间函数
- NOW(): 返回当前时间戳
- CURRENT_DATE / CURRENT_TIMESTAMP: 返回当前日期或时间戳
- YEAR(timestamp): 返回年份
- MONTH(timestamp): 返回月份
- DAY(timestamp): 返回日期
- HOUR(timestamp): 返回小时
- MINUTE(timestamp): 返回分钟
- SECOND(timestamp): 返回秒
SELECT SECOND('2024-11-10 14:30:45'); -- 从时间戳中提取秒
-- 结果:45
SELECT SECOND(NOW()); - 提取当前时间的秒数
-- 结果:取决于当前的时间
SELECT event_time, SECOND(event_time) AS event_seconds
FROM events; -- event_seconds 列将显示每个事件时间的秒数
-- SECOND 函数返回的值是一个整数,范围从 0 到 59。
- DATE_ADD(timestamp, days): 加天数
- DATE_SUB(timestamp, days): 减天数
- DATEDIFF(timestamp1, timestamp2): 返回两个日期间的天数
SELECT DATEDIFF('2024-11-10', '2024-11-01');
-- 结果:9
- DATE_PART(part, timestamp): 返回指定部分的值
SELECT DATE_PART('hour', '2024-11-10 14:30:45'); -- 提取小时
-- 结果:14
SELECT DATE_PART('dow', '2024-11-10 14:30:45'); -- 提取星期几(dow)0 表示周日,6 表示周六
-- 结果:0
- UNIX_TIMESTAMP(): 返回 Unix 时间戳
- FROM_UNIXTIME(unix_timestamp): 从 Unix 时间戳转换为日期
- TO_DATE(timestamp): 返回日期部分
SELECT TO_DATE('2024-11-10 14:30:45'); -- 返回日期部分
-- 结果:2024-11-10
- TRUNC(timestamp, unit): 按单位截断日期
SELECT TRUNC('2024-11-10 14:30:45', 'month'); -- 截断到月份
-- 结果:2024-11-01 00:00:00
SELECT TRUNC('2024-11-10 14:30:45', 'week'); -- 截断到周
-- 结果:2024-11-03 00:00:00
SELECT TRUNC('2024-11-10 14:30:45', 'day'); -- 截断到日
-- 结果:2024-11-10 00:00:00
4. 聚合函数
- COUNT(expr): 计数
- SUM(expr): 求和
- AVG(expr): 平均值
- MIN(expr): 最小值
- MAX(expr): 最大值
- STDDEV(expr): 标准差
- VAR_SAMP(expr): 方差(样本)
- VAR_POP(expr): 方差(总体)
- APPROX_COUNT_DISTINCT(expr): 近似唯一值计数
5. 条件函数
- IF(condition, true_value, false_value): 条件判断
SELECT
name,
IF(score >= 90, 'A',
IF(score >= 80, 'B',
IF(score >= 70, 'C', 'D'))) AS grade
FROM students;
SELECT
COUNT(IF(is_active = 1, 1, NULL)) AS active_users,
COUNT(IF(is_active = 0, 1, NULL)) AS inactive_users
FROM users;
- CASE WHEN condition THEN result [WHEN ...] ELSE result END: 多条件判断
SELECT
product_category,
COUNT(CASE WHEN sales > 1000 THEN 1 END) AS high_sales_count,
COUNT(CASE WHEN sales <= 1000 THEN 1 END) AS low_sales_count
FROM sales
GROUP BY product_category;
SELECT
customer_id,
order_amount,
CASE
WHEN order_amount > 5000 THEN 'High Value'
WHEN order_amount BETWEEN 1000 AND 5000 THEN 'Medium Value'
WHEN order_amount < 1000 THEN 'Low Value'
ELSE 'No Value'
END AS order_value_category
FROM orders;
- NULLIF(expr1, expr2): 如果两值相等返回 NULL
- COALESCE(expr1, expr2, ...): 返回第一个非空值
- ISNULL(expr) / IS NOT NULL(expr): 判断是否为空
6. 类型转换函数
- CAST(expr AS type): 类型转换,例如
CAST('123' AS INT) - CONVERT(expr, type): 数据类型转换(与 CAST 类似)
7. 哈希函数
- MD5(string): 返回字符串的 MD5 哈希
- SHA1(string): 返回字符串的 SHA1 哈希
SELECT
COUNT(*) AS user_count,
SHA1(CONCAT(username, 'salt')) AS hashed_username
FROM users
GROUP BY username; -- 根据用户名生成一个带有盐值(如 salt)的 SHA-1 哈希,这对密码存储等应用很有用,以增加哈希的复杂性。
8. 窗口函数
<window_function>(expression) OVER ([PARTITION BY <partition_expression>] [ORDER BY <order_expression>] [window_frame_specification])
--window_function: 可以是聚合函数(如 SUM、AVG)、排名函数(如 ROW_NUMBER、RANK)、或其他窗口专用函数。
--PARTITION BY: 可选的分区依据,用于将数据按某些列分组。
--ORDER BY: 可选的排序依据。
--window_frame_specification: 定义窗口框架,比如指定累积的范围。- ROW_NUMBER(): 行号
SELECT
salesperson_id,
order_id,
order_date,
ROW_NUMBER() OVER (PARTITION BY salesperson_id ORDER BY order_date) AS order_rank
FROM sales;
-- ROW_NUMBER() 函数根据 salesperson_id 进行分区,并按照 order_date 排序,为每个销售人员的订单分配一个独立的序号。- RANK(): 排名
- DENSE_RANK(): 连续排名
SELECT
salesperson_id,
month,
sales_amount,
RANK() OVER (PARTITION BY month ORDER BY sales_amount DESC) AS sales_rank,
DENSE_RANK() OVER (PARTITION BY month ORDER BY sales_amount DESC) AS dense_sales_rank
FROM monthly_sales;
-- 对销售人员的月销售额进行排名
-- 根据 sales_amount 排名,但 RANK() 会跳过重复排名的位置,而 DENSE_RANK() 则不会。- NTILE(n): 将分区划分为 n 份
SELECT
salesperson_id,
sales_date,
sales_amount,
AVG(sales_amount) OVER (PARTITION BY salesperson_id ORDER BY sales_date ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS moving_avg_sales
FROM daily_sales;
-- 用 AVG() 和窗口框架来计算为期 3 天的移动平均销售额,包含当前行及之前两行的平均值- LEAD(expr, offset): 获取后 n 行的值
- LAG(expr, offset): 获取前 n 行的值
SELECT
salesperson_id,
order_date,
sales_amount,
LAG(sales_amount, 1) OVER (PARTITION BY salesperson_id ORDER BY order_date) AS previous_sales,
LEAD(sales_amount, 1) OVER (PARTITION BY salesperson_id ORDER BY order_date) AS next_sales
FROM sales;
-- 用 LAG() 和 LEAD() 来访问前一行和后一行的值9. 其他杂项函数
- UUID(): 生成唯一标识符
- VERSION(): 返回 Impala 版本信息
10. 位操作函数
Impala 也支持一些位操作函数,通常用于对整数进行低级处理:
- BITAND(expr1, expr2): 位与操作
- BITOR(expr1, expr2): 位或操作
- BITXOR(expr1, expr2): 位异或操作
- BITNOT(expr): 位非操作
输入的 expr1 和 expr2 必须是整数类型
SELECT BITXOR(5, 3) AS result;
5 的二进制: 0101
3 的二进制: 0011
位异或结果: 0110(即十进制的 6)SELECT
col1,
col2,
BITXOR(col1, col2) AS bitwise_xor
FROM example_table; -- 表 example_table 包含两个整数字段 col1 和 col2,用 BITXOR 来计算它们的位异或:返回每一行的 col1 和 col2 的位异或结果
- SHIFTLEFT(expr, n): 左移操作,将二进制数左移
n位 - SHIFTRIGHT(expr, n): 右移操作,将二进制数右移
n位
11. JSON 处理函数
在处理 JSON 数据时,Impala 提供了一些 JSON 函数:
- JSON_GET_INT(json_string, json_path): 从 JSON 字符串中获取整数值
- JSON_GET_STRING(json_string, json_path): 从 JSON 字符串中获取字符串值
- JSON_GET_FLOAT(json_string, json_path): 从 JSON 字符串中获取浮点值
12. 高级统计函数
Impala 还支持一些高级统计函数,用于数据分析和科学计算:
- CORR(expr1, expr2): 计算两个列之间的相关系数
- COVAR_SAMP(expr1, expr2): 样本协方差
- COVAR_POP(expr1, expr2): 总体协方差
13. 集合函数
集合函数用于在分组的基础上进行复杂的聚合分析:
- ARRAY_AGG(expr): 将每组的值聚合成数组
- MAP_AGG(key_expr, value_expr): 将每组的键值对聚合成 Map
- MAP_FROM_ARRAYS(keys_expr, values_expr): 将两个数组(键和值)合并为 Map
14. 高级数据类型处理函数
Impala 支持 ARRAY 和 MAP 数据类型的处理函数,这些函数主要用于处理复杂数据结构:
- ARRAY_CONTAINS(array, value): 检查数组中是否包含指定值
- MAP_KEYS(map): 返回 Map 中的所有键
- MAP_VALUES(map): 返回 Map 中的所有值
select max(salary) from customers group by age having max(salary) > 20000; -- having子句
支持order by group by limit offset
-- 一般来说select查询的resultset中的行从0开始。使用offset子句可以决定从哪里考虑输出。 例如如果选择偏移为0,结果将像往常一样,如果选择偏移为5,结果从第五行开始
select * from customers order by id limit 4 offset 5; -- 从具有偏移5的行开始从客户表获取四个记录
-- Union子句组合两个查询的结果
query1 union query2;
select * from customers order by id limit 3 union select * from employee order by id limit 3;
-- 创建视图
CREATE VIEW IF NOT EXISTS customers_view AS select name, age from customers;
-- 删除视图
DROP VIEW database_name.view_name;
-- 可以添加、删除或修改现有表中的列,也可以重命名它们
alter TABLE my_db.customers RENAME TO my_db.users类业务代码:
CREATE procedure [dbo].[table_name](@p_date varchar(10) ) AS
BEGIN
--定义宿主变量
declare @MAX_VERSION INT;
DECLARE @c_date varchar(8);
DECLARE @c_date1 varchar(8);
declare @v_date DATETIME;
declare @v_date1 DATETIME;
declare @v_date2 DATETIME;
declare @v_date3 DATETIME;
declare @v_date_EDRAFT DATETIME;
declare @v_dateFITAS DATETIME;
declare @v_dateFITAS2 DATETIME;
declare @MaxDate DATETIME;
set @c_date =REPLACE(@p_date,'-','');
set @v_date = convert(DATETIME, @p_date); --包含日期和时间的值,时间部分为零
set @v_date1 = dateadd(Day,-1,@v_date); -- 在 @v_date 的基础上减去 1 天,得到前一天的日期
--PRINT @v_date1;
SET @c_date1= CONVERT(VARCHAR,@v_date1,112) -- 将 @v_date1 变量(DATETIME 类型)转换为特定格式的字符串(VARCHAR 类型),格式为 YYYYMMDD
--PRINT @c_date1;
set @v_date2 = CONVERT(DATETIME,SUBSTRING(@p_date,1,8)+'01') -- 提取前8个字符(年-月)与01拼接转换成日期格式,带时间
--set @v_date2 = CONVERT(DATETIME,'2024-01-01')
SET @v_date3=dateadd(Day,-1,@v_date2);
SET @v_date_EDRAFT=(SELECT MAX(DT_DATE) FROM table_name1)
SET @v_dateFITAS=dbo.table_name2(dateadd(dd,1,@p_date))
SET @v_dateFITAS2=dbo.table_name2(dateadd(dd,-1,@v_date2))
set @MaxDate=(select MAX(DT_DATE) from table_name3)
DELETE FROM table_name WHERE CJRQ=@c_date
insert into table_name
select
REPLACE(NEWID(),'-',''), -- format: 8F3B3F58-4E48-4D9C-8F76-7D3F2A8D502B
'80j00000000',
'',
BADD.Branch_ID,
'',
case when BADD.APROVEDATE>='2023-01-01' then '83102230' else '30477230' end
+CONVERT(VARCHAR,case when convert(int,CIF.SegmentCode) = '0' then '99' else convert(int,CIF1.SegmentCode) end),
'',
BADD.REFNO,
'Sales agreement',
'CNY',
BADD.BILLAMT,
0,
BADD.BILLAMT,
convert(varchar(8),BADD.APROVEDATE,112),
convert(varchar(8),BADD.DueDate,112),
BADD.CIFNO,
CIF.CustomerChineseName,
'CHN',
'',
'CHN',
*****,
0,
'正常',
'',
BADD.BillNo,
@c_date,
'toValidate',
'',
''
FROM dbo.table_name4 BADD
LEFT JOIN table_name5 B ON BADD.TXBUSS=B.REFNO AND BADD.DT_DATE=B.DT_DATE
LEFT JOIN (SELECT * FROM table_name6 WHERE DT_DATE=@v_date) CIF ON CIF.CIFNO=BADD.CIFNO
LEFT JOIN (SELECT * FROM table_name6 WHERE DT_DATE=@v_date) CIF1 ON CIF1.CIFNO=B.CIFNO
WHERE BADD.DT_DATE=@v_date AND BADD.BILLAMT>0
AND SETSTDDSBKNME NOT LIKE '%**%'
-------------------------------------------- impala
-- 定义输入变量 假设输入的日期格式为 'YYYY-MM-DD'
SET @p_date = '2024-01-01';
-- 转换日期格式
SET @c_date = REPLACE(@p_date, '-', '');
SET @v_date = CAST(@p_date AS TIMESTAMP);
SET @v_date1 = DATE_SUB(@v_date, 1);
SET @c_date1 = DATE_FORMAT(@v_date1, 'yyyyMMdd');
SET @v_date2 = DATE_FORMAT(CONCAT(SUBSTR(@p_date, 1, 8), '01'), 'yyyy-MM-dd');
SET @v_date3 = DATE_SUB(@v_date2, 1);
SET @v_date_EDRAFT = (SELECT MAX(DT_DATE) FROM table_name1);
SET @v_dateFITAS = table_name2(DATE_ADD(@p_date, 1));
SET @v_dateFITAS2 = table_name2(DATE_SUB(@v_date2, 1));
SET @MaxDate = (SELECT MAX(DT_DATE) FROM table_name3);
-- 删除指定日期的数据
DELETE FROM table_name WHERE CJRQ = @c_date;
-- 插入新数据
INSERT INTO table_name
SELECT
REGEXP_REPLACE(UUID(), '-', ''), --生成唯一 id
'80j00000000',
'',
BADD.Branch_ID,
'',
CASE
WHEN BADD.APROVEDATE >= '2023-01-01' THEN '83102230'
ELSE '30477230'
END ||
CASE
WHEN CAST(CIF.SegmentCode AS INT) = 0 THEN '99'
ELSE CAST(CIF1.SegmentCode AS VARCHAR)
END,
...
FROM
table_name4 BADD
LEFT JOIN
table_name5 B ON BADD.TXBUSS = B.REFNO AND BADD.DT_DATE = B.DT_DATE
LEFT JOIN
(SELECT * FROM table_name6 WHERE DT_DATE = @v_date) CIF ON CIF.CIFNO = BADD.CIFNO
LEFT JOIN
(SELECT * FROM table_name6 WHERE DT_DATE = @v_date) CIF1 ON CIF1.CIFNO = B.CIFNO
WHERE
BADD.DT_DATE = @v_date AND
BADD.BILLAMT > 0 AND
SETSTDDSBKNME NOT LIKE '%**%';
impala模拟update操作:
1、 使用Apache Kudu存储引擎实现更新
CREATE TABLE table ( id INT PRIMARY KEY, name STRING, age INT )
STORED AS KUDU;
UPDATE example_table SET age = 30 WHERE id = 1; 2、用INSERT OVERWRITE模拟更新
CREATE TABLE sales_data AS SELECT id, name, age FROM sales_data;
INSERT OVERWRITE TABLE sales_data SELECT id, name, age + 1
AS age FROM sales_data; 将某一分区或整张表进行数据更新。
INSERT OVERWRITE 是全表或分区级别的操作,适合在大批量更新或分区重写的场景中使用。
这种方式不支持部分行更新,因为它会覆盖整个表或指定的分区,适合批量“更新”需求。
3、使用临时表和分区覆盖模拟更新
对分区表进行部分更新时,可以通过创建临时表、筛选需要的数据并覆盖原始分区数据来实现更新效果。
CREATE TABLE tmp_table AS
SELECT id, name, age + 1 AS age
FROM sales_data
WHERE age > 25;删除目标分区数据:在更新的表中删除将被更新的分区或数据行。通过分区方式将目标行替换。 插入更新的数据:将临时表数据插入原表相应的分区中。
INSERT INTO TABLE sales_data PARTITION(partition_column = value)
SELECT * FROM tmp_table; 删除临时表:操作完成后删除临时表以节省空间。
这种方法适合在分区表上进行部分更新的操作。 更新的表最好使用增量分区导入,以减少数据扫描量。
3.1理解分区表和分区操作
分区表是指根据某个字段(通常是日期或类别等)将数据划分为多个“分区”的表。每个分区的数据可以独立管理。Impala支持对分区进行操作,例如插入数据、覆盖数据和删除数据。 在Impala中,删除目标分区数据并不意味着我们可以直接删除分区中的某些行,而是通过替换整个分区的数据来实现“更新”效果。
3.2如何删除并替换分区数据,实现这一点的步骤是:
通过查询数据,生成新的数据集,其中包含更新后的数据(通常是通过临时表或者查询生成的数据)。 使用INSERT OVERWRITE命令,将新的数据写入目标分区。这样会覆盖原有分区的数据。
假设有一个分区表 sales_data,该表按 year 和 month 分区,且表结构如下:
CREATE TABLE sales_data (
id INT,
name STRING,
age INT
)
PARTITIONED BY (year INT, month INT)
STORED AS PARQUET;
表数据为:
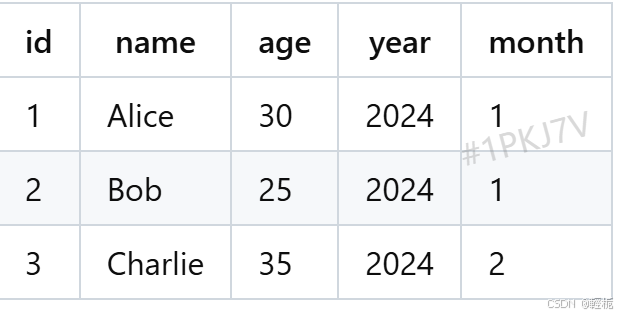
假设现在希望更新 2024 年 1 月的某些记录,比如将所有 age 大于 25 的记录的 age 增加 1。
创建临时表并生成更新后的数据
可以通过查询操作,生成包含更新数据的临时表。例如,更新 sales_data 中 2024 年 1 月的数据:
CREATE TABLE tmp_sales_data AS
SELECT id, name, age + 1 AS age, year, month
FROM sales_data
WHERE year = 2024 AND month = 1 AND age > 25;
临时表 tmp_sales_data 将包含更新后的数据,数据如下:
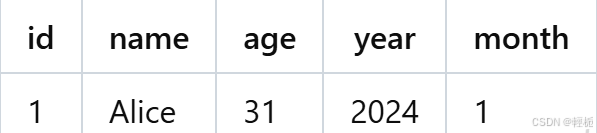
覆盖目标分区的数据
下一步是将 tmp_sales_data 中的数据覆盖到原表 sales_data 的指定分区中(在这里是 year=2024 和 month=1 分区)。使用 INSERT OVERWRITE 来执行这个操作。它会替换掉 sales_data 表中 2024 年 1 月的原有数据,更新后插入新的数据。
INSERT OVERWRITE TABLE sales_data PARTITION(year = 2024, month = 1)
SELECT id, name, age, year, month
FROM tmp_sales_data;
此时,sales_data 中 2024 年 1 月的记录已经被 tmp_sales_data 中的数据所替代,更新完成。
清理临时表
操作完成后,为了节省存储空间,可以删除临时表 tmp_sales_data:
DROP TABLE tmp_sales_data;通过 INSERT OVERWRITE 操作,Impala 会删除并覆盖目标分区的数据,实际上并没有直接删除某一分区的数据行,而是通过将分区的数据全部替换来实现更新。这是Impala操作分区表时的一种常见做法,适用于需要批量更新的场景。
4、使用左连接方式更新原表中特定数据LEFT JOIN
CREATE TABLE temp_updates AS
SELECT e.id, e.salary * 1.10 AS new_salary
FROM employees e
LEFT JOIN departments d ON e.department_id = d.id
WHERE d.budget > 100000; # 创建临时表或者分区表
UPDATE employees
SET salary = (SELECT new_salary FROM temp_updates WHERE temp_updates.id = employees.id)
WHERE id IN (SELECT id FROM temp_updates); # 更新原表
DROP TABLE temp_updates; # 删除临时表
5、impala实现for/while循环操作
1. 使用存储过程
虽然 Impala 本身并不支持存储过程,但一些数据仓库解决方案(例如 Hive)可能会提供此功能。如果使用 Hive,可以编写存储过程来实现复杂的逻辑和循环。
2. 使用外部编程语言
如果确实需要循环的逻辑,通常推荐使用外部编程语言(如 Python、Java 或 Scala)来控制数据流和逻辑,并通过 Impala 的 JDBC/ODBC 接口或命令行工具执行 SQL 查询
import pyodbc
# 连接到 Impala
conn = pyodbc.connect('DSN=YourDataSourceName;UID=YourUsername;PWD=YourPassword')
cursor = conn.cursor()
for i in range(10): # 这里是一个简单的 for 循环
# 执行 Impala 查询
query = f"INSERT INTO your_table (column1) VALUES ({i})"
cursor.execute(query)
# 提交更改
conn.commit()
# 关闭连接
cursor.close()
conn.close()
3. 使用临时表和批处理
如果你的逻辑可以通过一系列的 SQL 查询实现,你可以使用临时表来存储中间结果,然后逐步处理数据。例如,使用多条 INSERT 语句来模拟循环操作。虽然这不是传统意义上的循环,但可以达到类似的效果。
4. 使用 CTE(公共表表达式)
对于某些类型的数据处理,可以使用 CTE 来实现递归查询,从而模拟循环的效果。请注意,Impala 的 CTE 可能不支持递归,但在某些情况下可以帮助处理分层数据。
5. 编写.sh脚本
将.sh脚本放在linux目录下,.sh里面构建循环逻辑,会调用特定的计算过程如:
-- linux/test.sh
... # 加工处理逻辑1
loop/while/for
set spe_date ;
impala-shell -f ./EXEC_EAST_NBFHZ.sql --var=v_dtdate=spe_date;
... # 加工处理逻辑2
















 811
811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









