







AlexNet and VGG
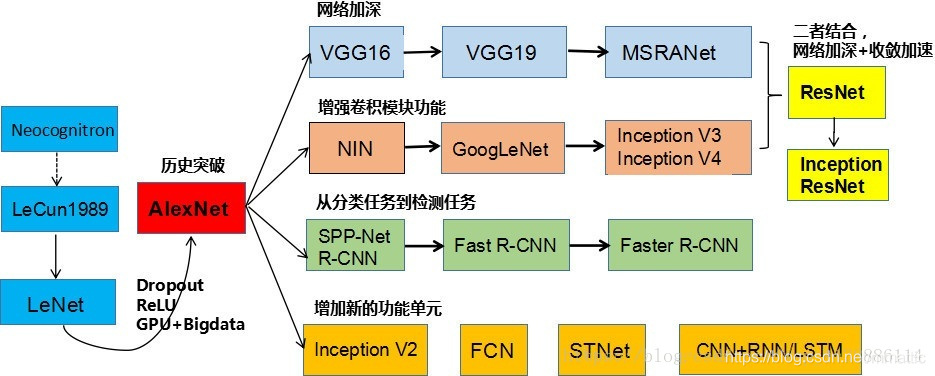
一.CNN结构演化图
二.AlexNet网络
- 论文来源:2012年Alex的论文《ImageNet Classification with Deep Convolutional Neural Networks》
- 深度学习领域经典模型之一
- 依附ImageNet大数据集合
- 通过GPU加强了高并行预算能力
- 用到了网络变深、数据增强、ReLU、Dropout等改进算法
- AlexNet拥有8层网络结构,最后一层全连接层是1000-way的softmax分类输出层。
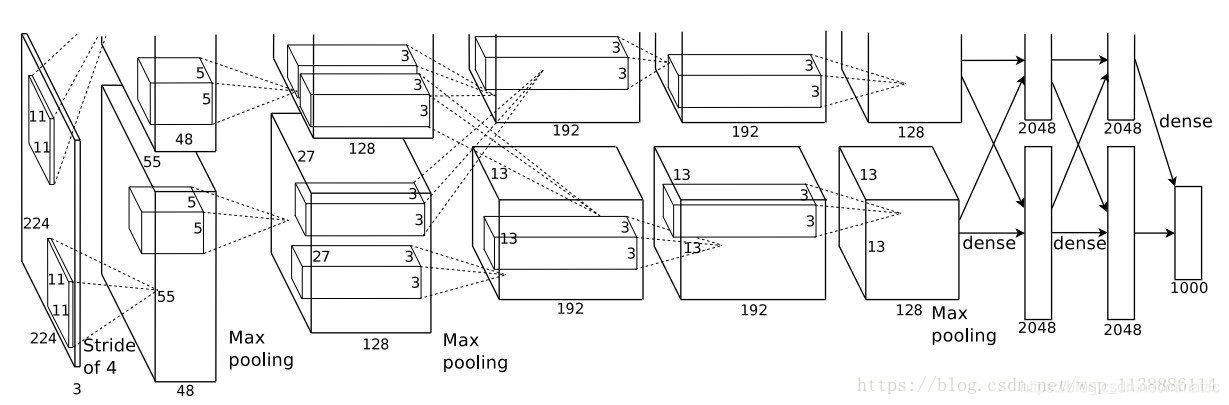
上图的网络结构使用两块GPU进行训练。一个GPU运行图上方的层,另一个运行图下方的层。两个GPU只在特定的层通信。
8层网络(5层卷积层,3层全连接层):
- conv1: 96 11x11x3 (对224x224x3的输入图像以4个像素为步长进行滤波)
- 卷积核大小:11x11 | 步长:4 | 数量:48x2 | 池化:3x3 | stride:2
- 激活函数ReLU、标准化
- 参数量:96x11x11x3 34848个参数
- 最终输出归一化后数据:27x27x48x2
- conv2: 256 5x5x48(将上层经过响应归一化和池化的输出作为输入)
- 卷积核大小:5x5 | 步长:1 | 数量:128x2 | 池化:3x3 | stride:2
- 激活函数ReLU、标准化
- 参数量:256x5x5x48 307200个参数
- 最终输出归一化后数据:13x13x128x2
- conv3: 384 3x3x256(在没有池化或者归一化层介入的情况下相互连接)
- 卷积核大小:3x3 | 步长:1 | 数量:192x2
- 激活函数ReLU
- 参数量:384x3x3x192 884736个参数
- 最终输出归一化后数据:13x13x192x2
- conv4: 384 3x3x192(在没有池化或者归一化层介入的情况下相互连接)
- 卷积核大小:3x3 | 步长:1 | 数量:192x2
- 激活函数ReLU
- 参数量:384x3x3x192 663552个参数
- 最终输出归一化后数据:13x13x192x2
- conv5: 256 3x3x192(在没有池化或者归一化层介入的情况下相互连接)
- 卷积核大小:3x3 | 步长:1 | 数量:128x2 | 池化:3x3 | stride:2
- 激活函数ReLU
- 参数量:256x3x3x192 442368个参数
- 最终输出归一化后数据:6x6x128x2
- fc6: 2048x2(两个GPU,共2048x2=4096个神经元)+ dropout
- 参数量:4096x6x6x256 37748736个参数(极大)
- 最终输出神经元点:4096个
- fc7: 2048x2(两个GPU,共2048x2=4096个神经元)+ dropout
- 参数量:4096x4096 16777216个参数
- 最终输出神经元点:4096个
- fc8: 1000个类别,softmax输出层
- 参数量:4096x1000 4096000个参数
- 最终输出分类:1000个
conv1: 96 11x11x3(卷积核个数 卷积核宽度卷积核高度厚度)
步长:核特征图中相邻神经元感受域中心之间的距离
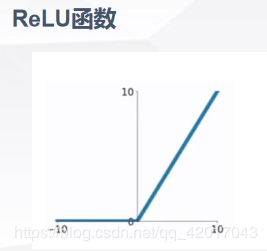
ReLU非线性激活函数:
-
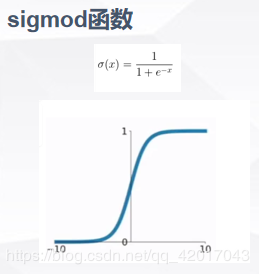
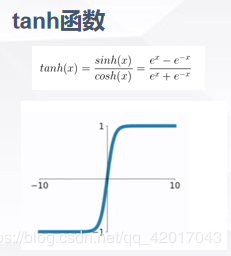
常见的激活函数:
-
-
-
-
与传统的Tanh、Logistic或者sigmoid的区别:
- 不像sigmoid函数一样要进行复杂的指数运算,缩短了训练时间,一定程度避免了梯度消失
- ReLU本质上是分段线性模型,前向计算非常简单,无需指数之类操作
- ReLU的偏导也很简单,反向传播梯度,无需指数或者除法之类操作
- ReLU不容易发生梯度发散问题,Tanh和Logistic激活函数在两端的时候导数容易趋近于零,多级连乘后梯度更加约等于0
- ReLU关闭了右边,从而会使得很多的隐层输出为0,即网络变得稀疏,起到了类似L1的正则化作用,可以在一定程度上缓解过拟合
-
缺点:
- ReLU神经元较脆弱,在接受非常大梯度流后,参数可能变负并造成正向传播输入都为0,造成神经元‘死亡’,因此不建议使用太大学习率
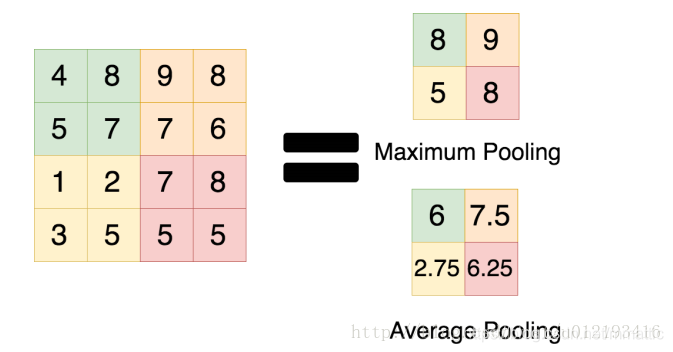
Overlap Max pooling
- 此前CNN普遍使用average pooling,得到的是模糊化的效果。
- max pooling更多的保留纹理信息。
- 让Pooling的步长(stride)小于池化核的尺寸(Kernel Size),池化层的输出之间就会有重叠和覆盖,提升了特征的丰富性。
降低过拟合( Reducing Overfitting)
- 数据增强(Data Augmentation):
- 方法1:生成平移图像和水平翻转图像。将原始的256256大小的图片随机剪裁成为224224大小的图片,并进行随机翻转。这一操作使得数据集扩大了(256-224)*(256-224)2=2048倍。而在测试时,将输入的图片以及其水平翻转在四角与正中分别裁剪下224224大小的10个子图,并将这10个大小的子图送入AlexNet,求其softmax输出层的平均。
- 方法2:改变训练图像的RGB通道的强度。使用PCA对图像的RGB通道进行降维,提取出三个通道的特征向量和特征值,然后对每个特征向量乘以一个标准差为0.1,均值为0的高斯分布的α。
- Dropout(随机忽略一部分神经元):
- 全连接层用了Dropout来做正则化。Dropout对每个节点以概率p使之失能,相当于一个集成学习的方法。
- 对每个神经元设置一个keep_prob(训练设0.5,测试设1.0并输出乘0.5-关闭dropout并保证测试与训练输出均值相近),随机删除一部分神经元(输出置0),使其不参与网络的正向和反向传播。因为每次都是随机抽取,因此可以有效避免过拟合。 - 重叠池化(Overlapping Pooling):
- CNNs中的池化层归纳了同一个核特征图中的相邻神经元组的输出
- 如果令S=Z,将会得到CNNs通常采用的局部池化。若令S<Z,则得到重叠池
- LRN(Local Response Normalization) 局部响应均值
- 局部归一的动机:生物学中有个概念叫做侧抑制,是指被激活的神经元抑制相邻神经元,归一化的目的是“抑制”,局部相应归一化就是借鉴侧抑制来实现局部抑制。
- LRN利用相邻feature map做特征显著化降低错误率,公式如下图
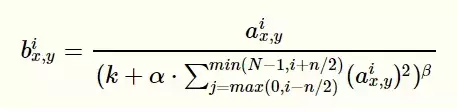
- 由于LRN层的作用不大暂不做具体深入
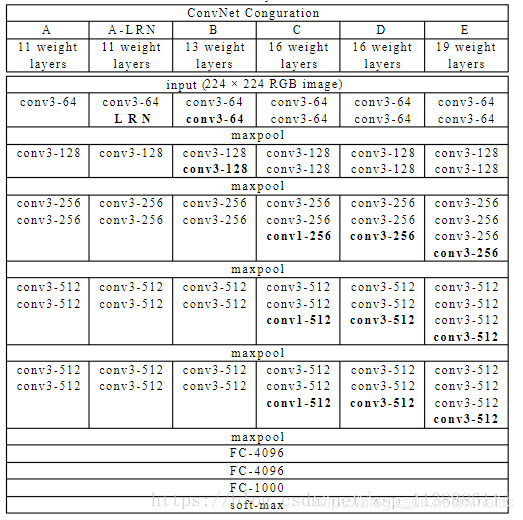
三.VGG网络
- VGG 网络是由conv、pool、fc、softmax层组成,层数上更深特征图更宽。
- 小卷积核:网络的结构非常一致,从头到尾全部使用的是3x3的卷积和2x2的汇聚(极少用了1x1)。
- 1x1卷积核:降维,增加非线性性(ReLU的效果)
- 3x3卷积核:多个卷积核叠加,增加空间感受野,减少参数
- 小池化核:相比AlexNet的3x3的池化核,VGG全部为2x2的池化核
- 耗费较多计算资源,特别是第一个全连接层
- VGG最大的贡献是证明了卷积神经网络的深度增加和小卷积核的使用对网络的最终分类识别效果有很大的作用。
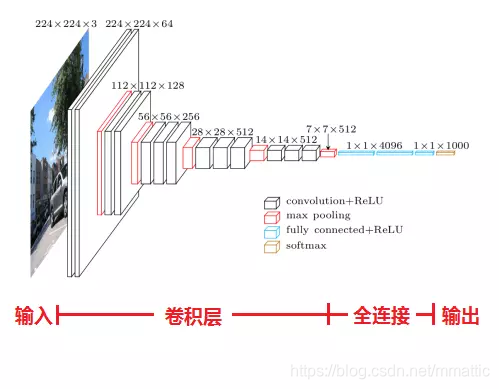
- 小卷积核:
- 卷积不仅涉及到计算量(卷积核尺寸小的计算量小,由下图可知),还影响到感受野。
- 感受野:
- 可用两层33的卷积层替代55卷积,效果相当。而3个3x3卷积的堆叠获取到的感受野相当于一个7x7的卷积。
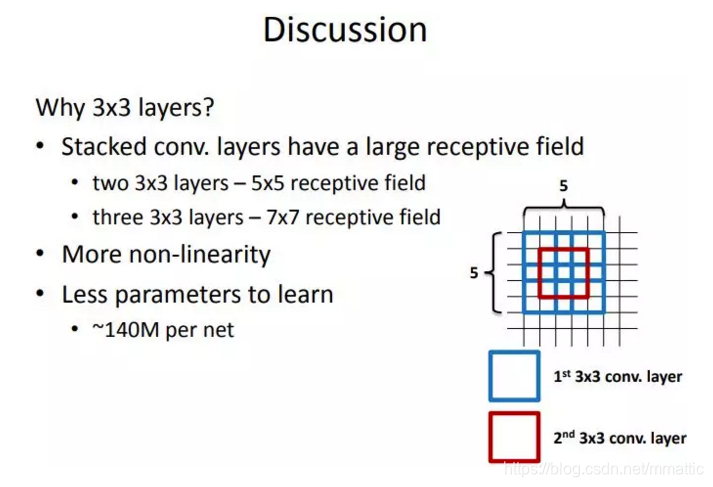
- 可用两层33的卷积层替代55卷积,效果相当。而3个3x3卷积的堆叠获取到的感受野相当于一个7x7的卷积。
- 全连接卷积:
- VGG的作者把训练阶段的全连接替换为卷积是参考了OverFeat的工作,OverFeat将全连接换成卷积后,带来可以处理任意分辨率(在整张图)上计算卷积,而无需对原图resize的优势。
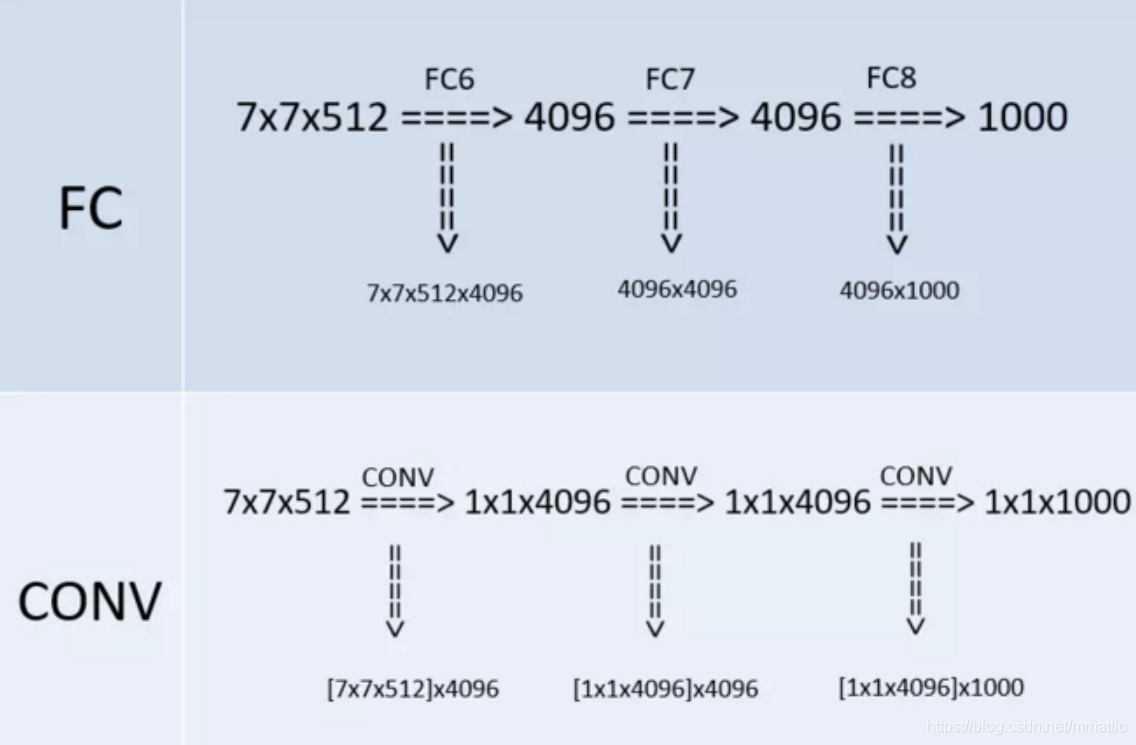
- 1x1卷积:
- VGG在最后三个阶段用1x1卷积核是为了在维度上继承全连接
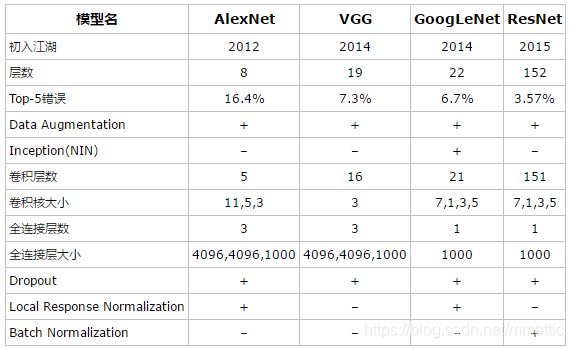
- AlexNet 和 VGGNet的对比图:
四.pytorch搭建卷积神经网络及训练
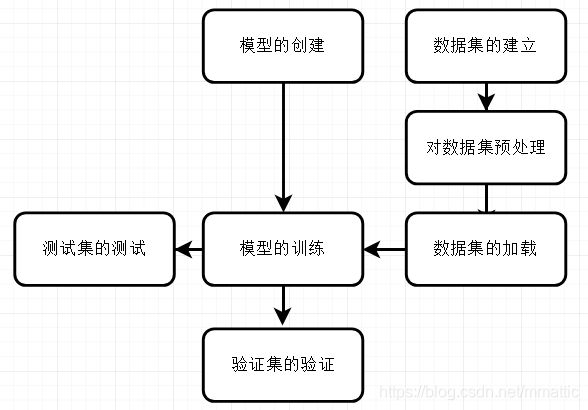
- 模型的创建:
在torchvision.models已有模型上做修改,如采用与训练模型,需修改最后分类类别,修改全连接层的最后一层
#vgg16
model.classifier = nn.Sequential(nn.Linear(25088, 4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 2))
#Alexnet
alexnet_model.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, 2),
)
#如采用预训练模型,需修改
for index, parma in enumerate(model.classifier.parameters( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3130
3130

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









