



优化注意事项:
尽量避免使用select *
在实际业务场景中,真正需要使用的只有其中一两列。写SQL语句时,有时候为了方便,直接使用select *,一次性查出表中所有列的数据。多查出来的数据,在网络传输的过程中,会增加数据传输的时间。更重要的是,select 不会走覆盖索引,会出现大量的回表操作,从而导致查询性能很低。
小表驱动大表
即用小表的数据集驱动大表的数据集。假如有order和user两张表,其中order表有10000条数据,而user表有100条数据。这时如果想查一下所有有效的用户下过的订单列表,可以使用in关键字实现:select * from order where user_id in (select id from user where status=1)。sql语句中包含了in关键字,则它会优先执行in里面的子查询语句,再执行in外面的语句。如果in里面的数据量很少,作为条件查询速度更快。
但缺点是MySQL执行子查询时,需要创建临时表,查询完毕后,需要再删除这些临时表,有一些额外的性能消耗。这时可以改成连接查询:select o. from order o inner join user u on o.user_id=u.id where u.status=1。
避免in中值太多
如果in中的值太多,会导致查询效率下降。尽量避免这种情况,或者通过其他方式优化。
有时候使用连接查询比子查询更高效。
控制join表的数量
如果join太多,MySQL在选择索引的时候会非常复杂,很容易选错索引。并且如果没有命中索引,如果实现业务场景中需要查询出另外几张表中的数据,可以在a、b、c表中冗余专门的字段,比如:在表a中冗余d_name字段,保存需要查询出的数据。
控制索引的数量
索引能够显著的提升查询性能,但索引数量并非越多越好。表新增数据时,需要同时为它创建索引,而索引是需要额外的存储空间的,而且还会有一定的性能消耗。MySQL使用的B+树的结构来保存索引的,在insert、update和delete操作时,需要更新B+树索引。如果索引过多,会消耗很多额外的性能。
提升group by的效率
很多业务场景需要使用group by关键字,它主要功能是去重和分组。通常它会跟having一起配合使用,表示分组后再根据一定的条件过滤数据。
反例:select user_id,user_name from order group by user_id having user_id<=200。这种写法性能不好,它先把所有的订单根据用户id分组之后,再去过滤用户id大于等于200的用户。
正例:select user_id,user_name from order where user_id<=200 group by user_id。使用where条件在分组前,就把多余的数据过滤掉了,这样分组时效率就会更高一些。
其实这是一种思路,不仅限于group by的优化。我们的SQL语句在做一些耗时的操作之前,应尽可能缩小数据范围,这样能提升SQL整体的性能。
索引优化
SQL优化当中,有一个非常重要的内容就是:索引优化。很多时候SQL语句走了索引和没走索引执行效率差别很大。索引优化的第一步是:检查SQL语句有没有走索引。可以使用explain命令,查看MySQL的执行计划。进而查看索引是否生效。SQL语句没有走索引排除没有建索引之外最大的可能性就是索引失效。
EXPLAIN是什么?
EXPLAIN 是 MySQL 中的一个诊断命令,用于获取查询执行计划的信息。通过使用 EXPLAIN,你可以了解 MySQL 是如何执行 SQL 查询的,包括它是如何选择表、连接顺序、使用的索引等。这对于优化查询性能非常有帮助。
这条命令将不会真正执行查询,而是返回一个描述MySQL如何执行该查询的报告。
只能解释select查询,并不会对存储过程调用和insert,update,delete或其他语句做解释
| 字段 | 含义 | 优化建议 |
|---|---|---|
| id | 查询标识符,标识查询中的每个SELECT语句。 | - |
| select_type | 查询类型,如简单查询、子查询等。 | 根据查询类型优化查询结构,减少不必要的子查询。 |
| table | 当前行描述的表名或别名。 | - |
| partitions | 查询涉及的分区信息。 | 如果使用了分区表,确保查询能够有效利用分区。 |
| type | 访问类型,影响查询速度,从好到差:system > const > eq_ref > ref > range > index > ALL。 | 尽量提高访问类型,避免使用ALL类型的全表扫描。 |
| possible_keys | MySQL可以使用但最终可能未选择的索引列表。 | 如果possible_keys为空,考虑添加索引。 |
| key | 实际使用的索引名称。 | 确保查询使用了正确的索引,提高查询效率。 |
| key_len | 使用的索引长度。 | 较短的key_len通常更好,但也要考虑索引的选择性。 |
| ref | 查找索引列上值所使用的列或常量。 | - |
| rows | 预计需要读取的行数。 | 减少rows数量,通过优化索引或查询条件。 |
| filtered | 符合查询条件的行的比例。 | 提高filtered比例,优化查询条件,使更多的行在早期被过滤掉。 |
| Extra | 额外信息,如使用临时表、文件排序等。 | 避免Using temporary和Using filesort,优化查询或索引设计。 |
写业务逻辑较为复杂的SQL,经常会碰到多表查询、表数据量大查不动的情况。通常会在数据量大的表建立索引,方便后续能更快的查询。但是可能效果还是不尽人意,这就要优化SQL了。
优化步骤
如果SQL没有按照预定的执行速度执行,可以用EXPLAIN命令诊断这条语句是怎么执行的。
优化示例:
待优化示例:
WITH filtered_sd AS (
SELECT sd.* FROM vap_video_status_day sd
LEFT JOIN bas_road_segment_info rs ON sd.road_segment_id = rs.road_segment_id
LEFT JOIN bas_road_info ri ON rs.road_id = ri.road_id
LEFT JOIN bas_device_info B ON B.device_id = sd.camera_id
WHERE DATE_FORMAT( sd.stat_time, '%Y-%m-%d' ) ='2025-01-05'
ORDER BY sd.stat_time DESC
)
SELECT fsd.*, ri.road_full_name, B.stake_id, B.special_5 AS special5,
B.device_code as deviceCode,B.special_14 as positionType,
GROUP_CONCAT(detail.status ORDER BY detail.recording_time) AS status_list
FROM filtered_sd fsd
LEFT JOIN bas_road_segment_info rs ON fsd.road_segment_id = rs.road_segment_id
LEFT JOIN bas_road_info ri ON rs.road_id = ri.road_id
LEFT JOIN bas_device_info B ON B.device_id = fsd.camera_id
LEFT JOIN
(
SELECT device_id, status, recording_time
FROM vap_video_status_detail
WHERE DATE_FORMAT(recording_time, '%Y-%m-%d') = '2025-01-05'
AND device_id IN (SELECT camera_id FROM filtered_sd)
) detail ON detail.device_id = fsd.camera_id
GROUP BY fsd.id
ORDER BY fsd.stat_time DESC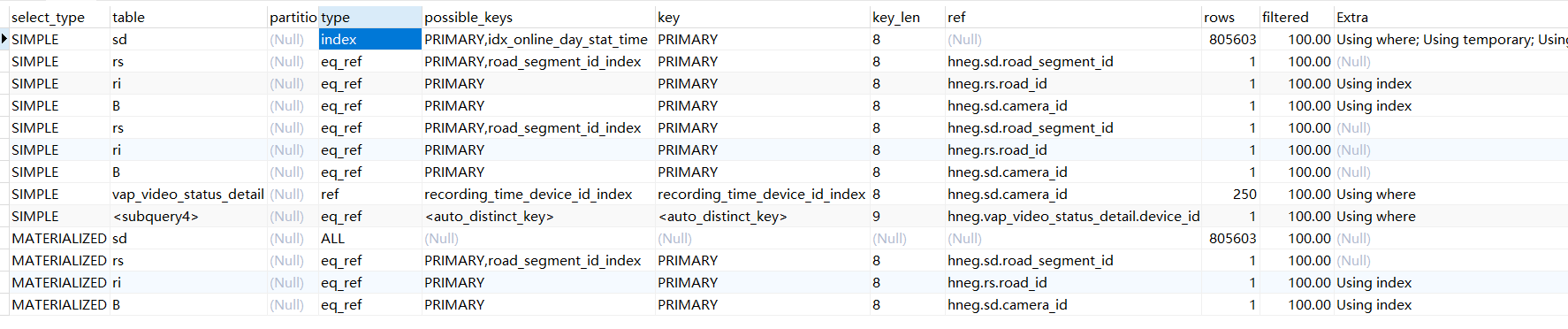
优化示例:
WITH filtered_sd AS (
SELECT
device_id,
GROUP_CONCAT(`status` ORDER BY recording_time SEPARATOR ',') AS status_concat
FROM
vap_video_status_detail
WHERE
recording_time >= '2025-01-05 00:00:00'
AND recording_time < '2025-01-06 00:00:00'
GROUP BY
device_id
)
SELECT
sd.*,
ri.road_full_name,
B.stake_id,
B.special_5 AS special5,
B.device_code AS deviceCode,
B.special_14 AS positionType,
detail.status_concat
FROM
vap_video_status_day sd
LEFT JOIN bas_road_segment_info rs ON sd.road_segment_id = rs.road_segment_id
LEFT JOIN bas_road_info ri ON rs.road_id = ri.road_id
LEFT JOIN bas_device_info B ON B.device_id = sd.camera_id
LEFT JOIN filtered_sd detail ON detail.device_id = sd.camera_id
WHERE
sd.stat_time >= '2025-01-05 00:00:00'
AND sd.stat_time < '2025-01-06 00:00:00'
ORDER BY
sd.stat_time DESC;
优化思路
- 避免函数操作:移除
DATE_FORMAT等列值转换函数,改为直接比较时间范围,确保索引可用。 - 减少子查询嵌套:将子查询改写为 CTE(Common Table Expression),提前过滤和聚合数据。
- 优化 JOIN 顺序:通过预聚合减少 JOIN 操作的数据量。
- 利用索引:确保时间字段和连接字段的索引被正确使用。
- 消除不必要的分组:调整
GROUP BY逻辑,减少计算开销。

















 1170
1170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









