




目录
前言
哈喽,各位小伙伴大家好!上期我们讲了C++的内存管理。今天我们来讲解C++模版和STL库。
1泛型编程
如何实现一个通用的交换函数呢?
如果我们想实现三种类型的交换函数就需要这样写代码。
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}
void Swap(double& left, double& right)
{
double temp = left;
left = right;
right = temp;
}
void Swap(char& left, char& right)
{
char temp = left;
left = right;
right = temp;
}
使用函数重载虽然可以实现,但是有一下几个不好的地方:
重载的函数仅仅是类型不同,代码复用率比较低,只要有新类型出现时,就需要用户自己增
加对应的函数
代码的可维护性比较低,一个出错可能所有的重载均出错 。
那能否告诉编译器一个模子,让编译器根据不同的类型利用该模子来生成代码呢?
这几个函数的逻辑都是一样的。只是类型不同。就像这些铸件一样模版样子都一样,只是浇筑材料不一样。
如果在C++中,也能够存在这样一个模具,通过给这个模具中填充不同材料(类型),来获得不同
材料的铸件(即生成具体类型的代码),那将会节省许多头发。巧的是前人早已将树栽好,我们只
需在此乘凉。
泛型编程:编写与类型无关的通用代码,是代码复用的一种手段。模板是泛型编程的基础。
2.函数模版
2.1 概念
函数模板代表了一个函数家族,该函数模板与类型无关,在使用时被参数化,根据实参类型产生
函数的特定类型版本。
2.2 格式
template<typename T1, typename T2,......,typename Tn>
返回值类型 函数名(参数列表){}
template<typename T>
void Swap( T& left, T& right)
{
T temp = left;
left = right;
right = temp;
}注意:typename是用来定义模板参数关键字,也可以使用class(切记:不能使用struct代替
class)
2.3. 原理
函数模板是一个蓝图,它本身并不是函数,是编译器用使用方式产生特定具体类型函数的模具。
所以其实模板就是将本来应该我们做的重复的事情交给了编译器
下面我们写一个数据交换的模版
#include <iostream>
using namespace std;
template<class T>
void Swap(T& a, T& b)
{
T tmp = a;
a = b;
b = tmp;
}那么如果我们在主函数调用函数模版时,编译器会帮我们自动生成对应的数据类型,原理如下:
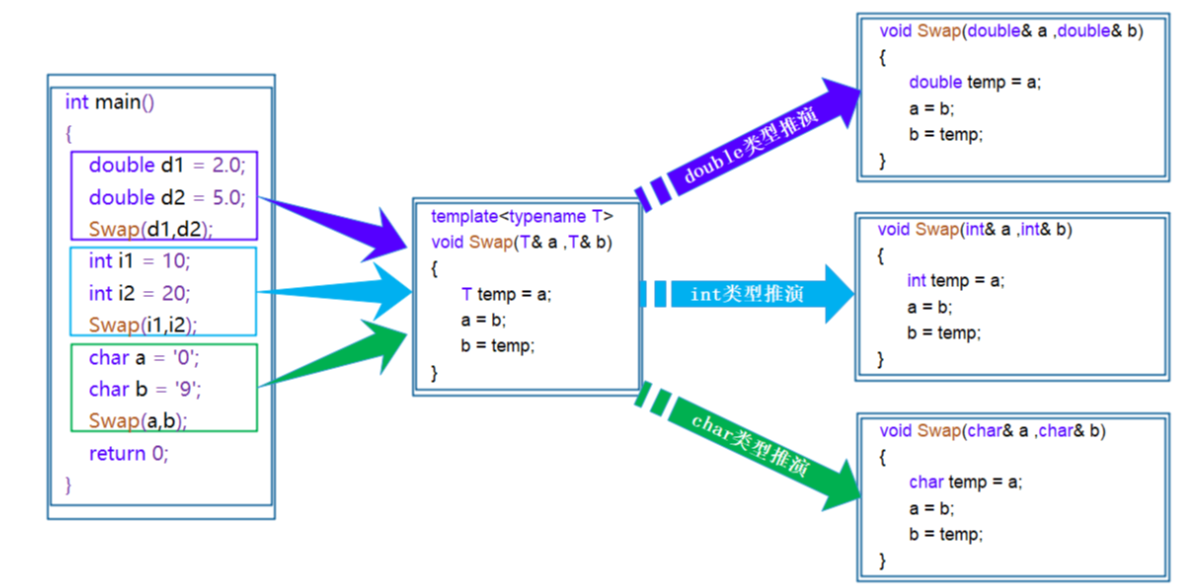
在编译器编译阶段,对于模板函数的使用,编译器需要根据传入的实参类型来推演生成对应
类型的函数以供调用。比如:当用double类型使用函数模板时,编译器通过对实参类型的推演,
将T确定为double类型,然后产生一份专门处理double类型的代码,对于字符类型也是如此.
2.4函数模版的实例化
用不同类型的参数使用函数模板时,称为函数模板的实例化。模板参数实例化分为:隐式实例化
和显式实例化。
1. 隐式实例化:让编译器根据实参推演模板参数的实际类型
如果我们写了下面这段代码:
#include <iostream>
using namespace std;
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
int main()
{
int a1 = 10, a2 = 20;
double d1 = 10.0, d2 = 20.0;
Add(a1, d1);
}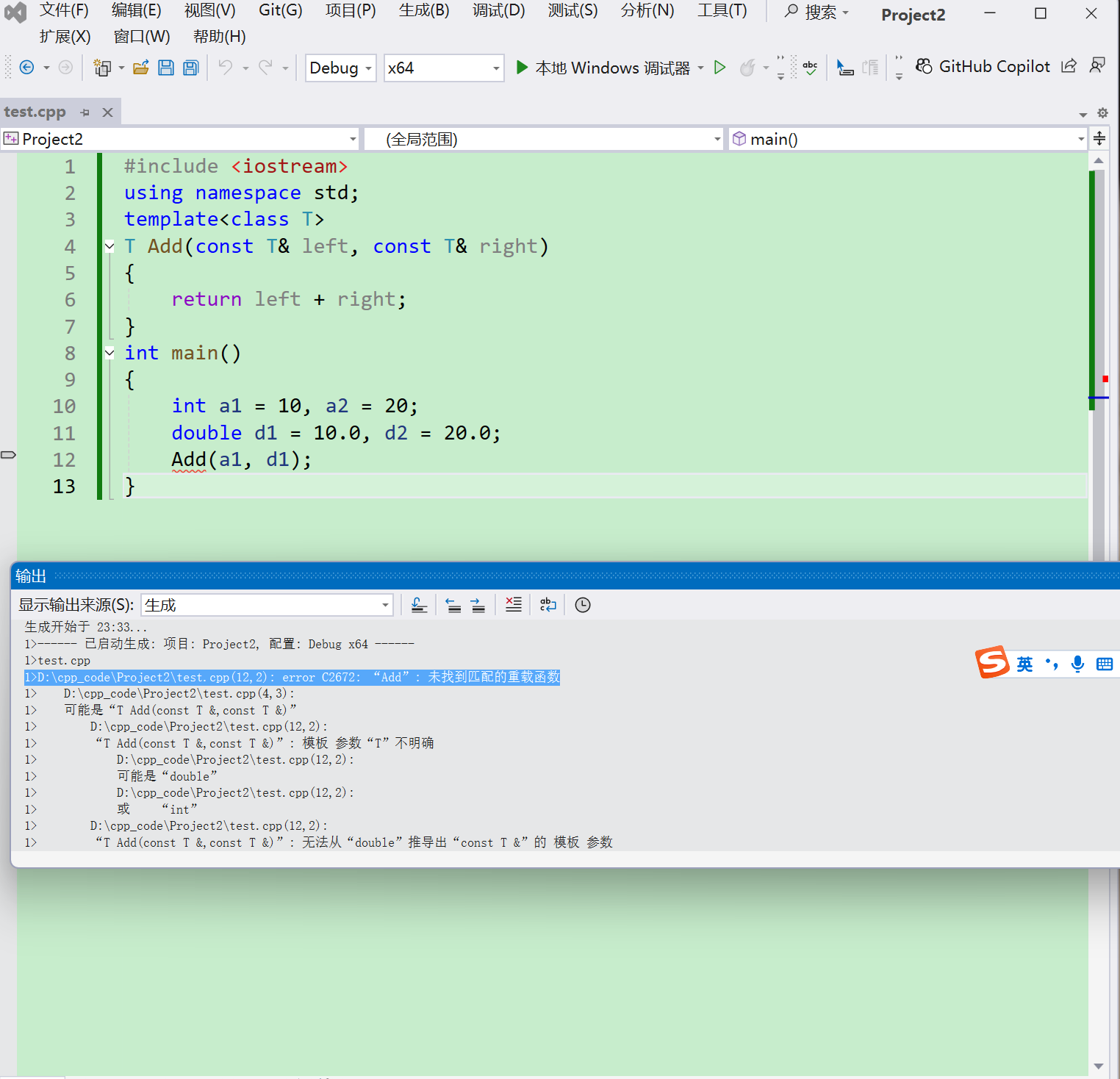
我们会发现,编译代码时会出现问题,通过编译,因为在编译期间,当编译器看到该实例化时,需要推演其实参类型
通过实参a1将T推演为int,通过实参d1将T推演为double类型,但模板参数列表中只有
一个T,
编译器无法确定此处到底该将T确定为int 或者 double类型而报错
此时有两种处理方式:1. 用户自己来强制转化 2. 使用显式实例化
如果是方式一,我们只需要改成下面编译就不会出现问题
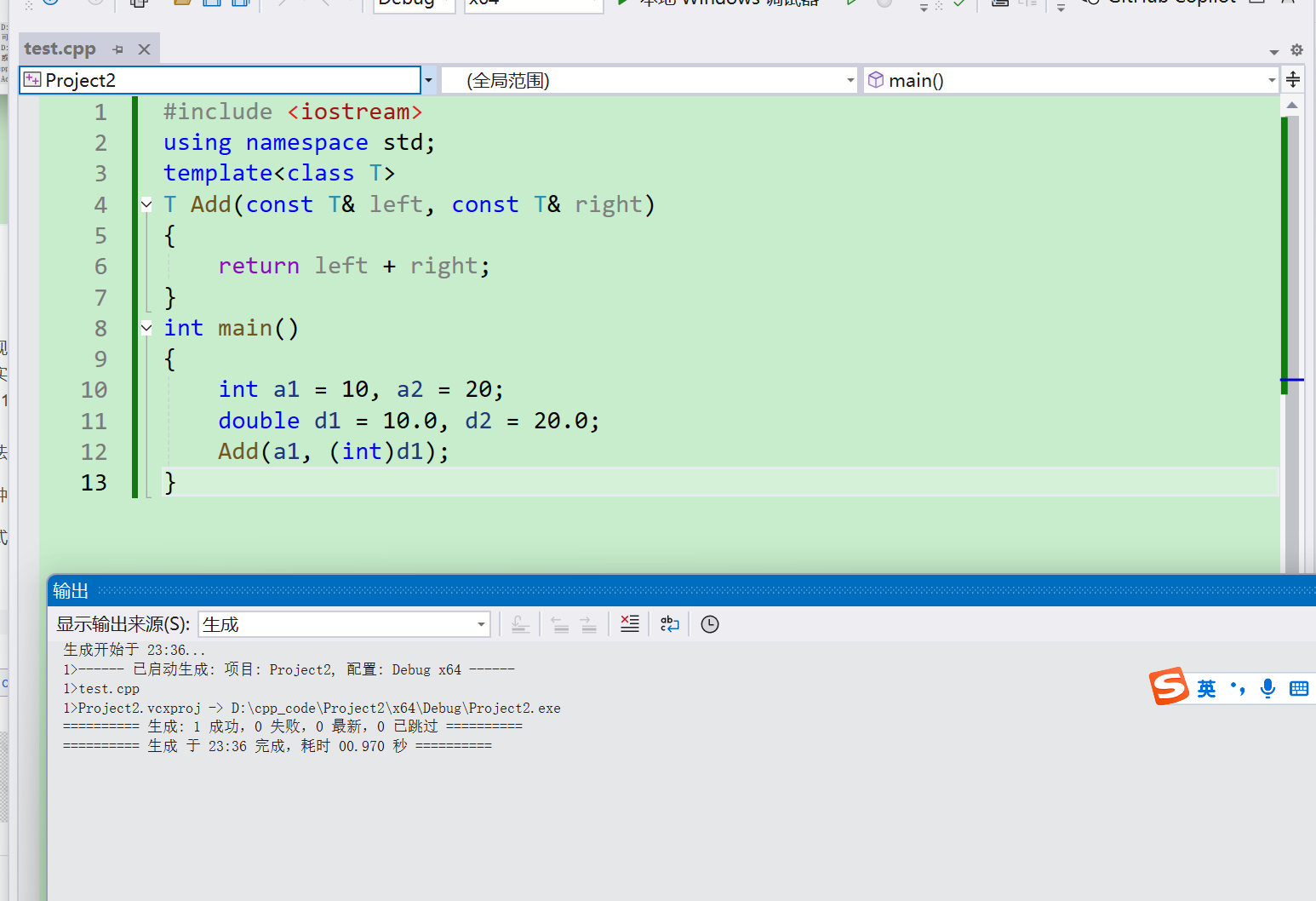
注意:在模板中,编译器一般不会进行类型转换操作
2. 显式实例化:在函数名后的<>中指定模板参数的实际类型
那么我们只需要将上面的代码稍微修改即可
#include <iostream>
using namespace std;
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
int main(void)
{
int a = 10;
double b = 20.0;
Add<int>(a, b);
return 0;
}如果类型不匹配,编译器会尝试进行隐式类型转换,如果无法转换成功编译器将会报错。
2.5模版的参数匹配机制
1. 一个非模板函数可以和一个同名的函数模板同时存在,而且该函数模板还可以被实例化为这
个非模板函数
// 专门处理int的加法函数
int Add(int left, int right)
{
return left + right;
}
// 通用加法函数
template<class T>
T Add(T left, T right)
{
return left + right;
}
int main()
{
Add(1, 2); // 与非模板函数匹配,编译器不需要特化
Add<int>(1, 2); // 调用编译器特化的Add版本
}2. 对于非模板函数和同名函数模板,如果其他条件都相同,在调动时会优先调用非模板函数而
不会从该模板产生出一个实例。如果模板可以产生一个具有更好匹配的函数, 那么将选择模
板
// 专门处理int的加法函数
int Add(int left, int right)
{
return left + right;
}
// 通用加法函数
template<class T1, class T2>
T1 Add(T1 left, T2 right)
{
return left + right;
}
void Test()
{
Add(1, 2); // 与非函数模板类型完全匹配,不需要函数模板实例化
Add(1, 2.0); // 模板函数可以生成更加匹配的版本,编译器根据实参生成更加匹配的Add函数
}3. 模板函数不允许自动类型转换,但普通函数可以进行自动类型转换
3.类模版
3.1 类模板的定义格式
template<class T1, class T2, ..., class Tn> class 类模板名 { // 类内成员定义 };
我们根据类模版格式写一个简单的类模版
template<typename T>
class Stack
{
public:
Stack(size_t capacity = 4)
{
_array = new T[capacity];
_capacity = capacity;
_size = 0;
}
void Push(const T& data);
private:
T* _array;
size_t _capacity;
size_t _size;
};注意:模版不建议声明和定义分离到两个文件.h 和.cpp,会出现链接错误
原因如下:
在 C++程序的构建过程中,源代码需要经过 预处理、编译、汇编和链接 四个主要阶段,最终生成可执行文件。首先是预处理,这个过程包括头文件展开,宏替换,条件编译,去掉注释等,以Linux环境为例,.h文件在这个过程后变成了.i文件,然后是编译,这个过程就是检查语法,生成汇编代码,从.i文件变成.s文件,接下来就是汇编,将汇编代码转化成二进制机器码,从.s文件变成.o文件,最后是链接,就是将目标文件合并在一起生成可执行程序,并且把需要的函数地址等链接上,出现链接错误的具体是出现在编译阶段,当编译器处理 main.cpp(或其他使用模板的源文件)时:它看到了模板的声明(在 .h 文件中),但看不到定义(在 .cpp 文件中)。由于模板是编译时实例化的,编译器无法为 MyTemplate<int> 生成实际的机器码(因为定义不可见)。编译器会假设链接器稍后能找到这些代码,因此不会报错,但是真到链接时候时,编译器找不到模板的具体实现在哪里
3.2 类模板的实例化
类模板实例化与函数模板实例化不同,类模板实例化需要在类模板名字后跟<>,然后将实例化的
类型放在<>中即可,类模板名字不是真正的类,而实例化的结果才是真正的类。
// Stack是类名,Stack<int>才是类型
Stack<int> st1; // int
Stack<double> st2; // double4.STL简介
4.1 什么是STL
STL(standard template libaray-标准模板库):是C++标准库的重要组成部分,不仅是一个可复用的
组件库,而且是一个包罗数据结构与算法的软件框架。学了STL后大家就会发现C++对比C的优势了
4.2 STL的版本
原始版本
Alexander Stepanov、Meng Lee 在惠普实验室完成的原始版本,本着开源精神,他们声明允许
任何人任意运用、拷贝、修改、传播、商业使用这些代码,无需付费。唯一的条件就是也需要向原
始版本一样做开源使用。 HP 版本--所有STL实现版本的始祖。
P. J. 版本
由P. J. Plauger开发,继承自HP版本,被Windows Visual C++采用,不能公开或修改,缺陷:可读
性比较低,符号命名比较怪异。
RW版本
由Rouge Wage公司开发,继承自HP版本,被C+ + Builder 采用,不能公开或修改,可读性一
般。
SGI版本
由Silicon Graphics Computer Systems,Inc公司开发,继承自HP版 本。被GCC(Linux)采用,可
移植性好,可公开、修改甚至贩卖,从命名风格和编程 风格上看,阅读性非常高。
4.3 STL的六大组件
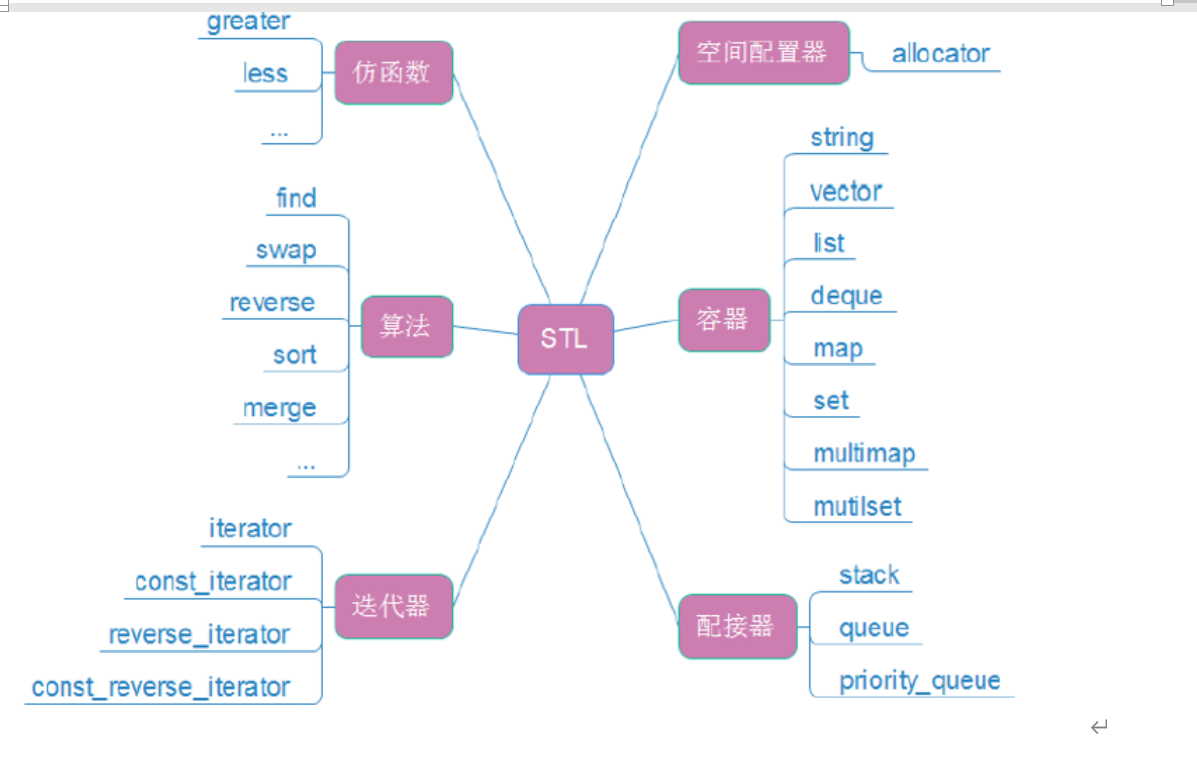
4.4 STL的重要性
| 开发效率 | 提供现成的数据结构和算法,减少重复劳动。 |
| 高性能 | 底层优化,算法复杂度明确(如 O(1)、O(log n))。 |
| 安全性 | RAII 管理资源,避免内存泄漏;边界检查减少崩溃风险。 |
| 可移植性 | 所有标准 C++ 编译器支持,代码跨平台运行。 |
| 扩展性 | 支持自定义分配器、适配器,与现代 C++ 特性(如 Lambda)无缝结合 |

















 537
537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









