




运行效果
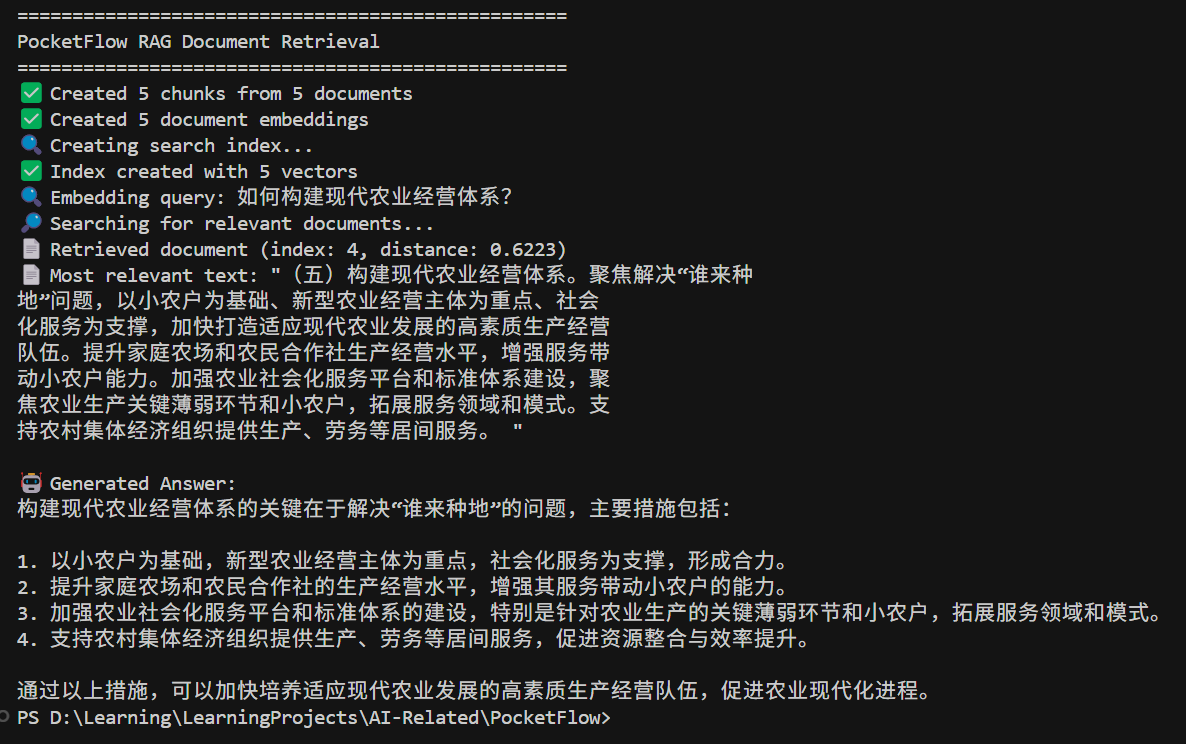
例子地址:https://github.com/The-Pocket/PocketFlow/tree/main/cookbook/pocketflow-rag
什么是RAG(用PocketFlow作者通俗的话来理解)
想象RAG就像在AI回答问题之前给了它一个个人的研究图书馆员。以下是这个魔法如何发生的:
文档收集:你把你的文档(公司手册、文章、书籍)提供给系统,就像书被添加到图书馆一样。
切片:系统将这些文档分解成易于消化的小块——就像图书馆员将书籍按章节和部分划分,而不是处理整本书。
嵌入:每个小块被转换成一种特殊的数字格式(向量),能够捕捉其含义——类似于创建能够理解概念而不仅仅是关键词的详细索引卡。
索引:这些向量被组织在一个可搜索的数据库中——就像一个理解不同主题间关系的神奇卡片目录。
检索:当你提问时,系统会查阅其索引,找到与你的查询最相关的片段。
生成:AI利用你的问题和这些有用的参考,生成一个比仅依赖其预先训练的知识更优秀的回答。
结果?AI不会编造信息或提供过时的信息,而是基于你的特定文档来构建其回答,提供准确、相关且符合你信息的回应。
在这个例子中作者使用了两个工作流,一个是offline工作流一个是online工作流:
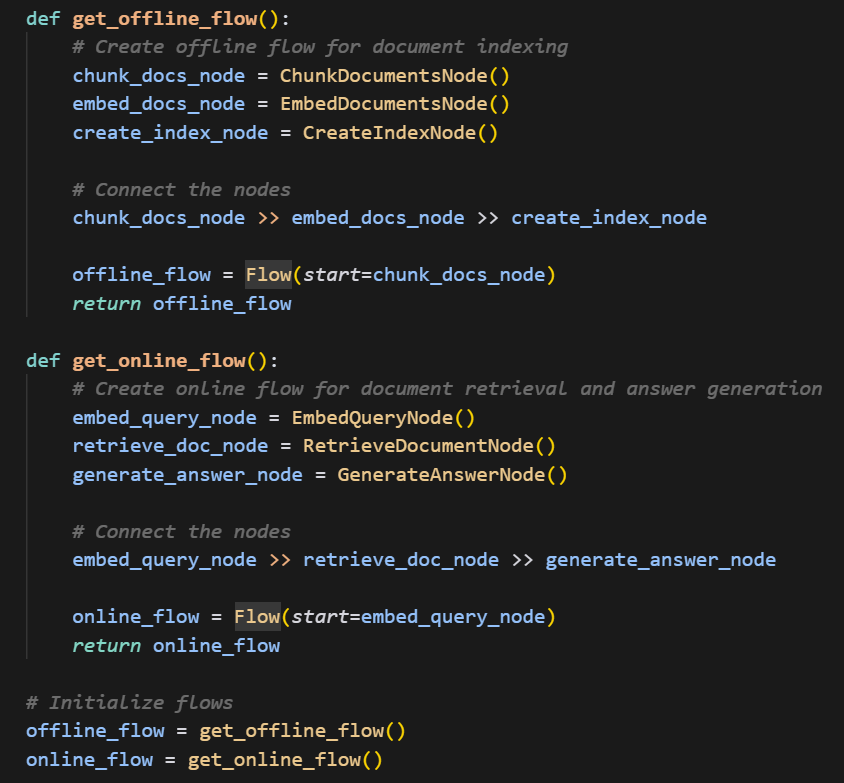
offline工作流包含切片、嵌入与创建索引节点。
online工作流包含询问嵌入、检索文档与生成回答节点。
认识一下切片(用PocketFlow作者通俗的话来理解)
切块:将文档分成易于管理的小部分
在我们的RAG系统能够有效工作之前,我们需要将文档分解成更小、更易于消化的部分。
想象一下切块就像为客人准备饭食——你不会未经切片就直接上整只火鸡!
为什么分块很重要?
分块的大小直接影响你的RAG系统的质量:
分块过大:系统检索到过多的无关信息(就像提供整只火鸡)
分块过小:你失去了重要的上下文(就像只提供单一的豌豆)
恰到好处的分块:系统能够准确找到所需信息(完美的分量!)
有一些实用的分块方法
1、固定大小分块:简单但不完美
def fixed_size_chunk(text, chunk_size=50):
chunks = []
for i in range(0, len(text), chunk_size):
chunks.append(text[i:i+chunk_size])
return chunks
这段代码会逐次处理文本中的50个字符。
让我们看看它在示例段落上是如何工作的:
Input Text:
The quick brown fox jumps over the lazy dog. Artificial intelligence has revolutionized many industries. Today's weather is sunny with a chance of rain. Many researchers work on RAG systems to improve information retrieval.
Output Chunks:
Chunk 1: "The quick brown fox jumps over the lazy dog. Arti"
Chunk 2: "ficial intelligence has revolutionized many indus"
Chunk 3: "tries. Today's weather is sunny with a chance of "
Chunk 4: "rain. Many researchers work on RAG systems to imp"
Chunk 5: "rove information retrieval."
注意问题了吗?单词 “Artificial” 被拆分在第1块和第2块之间。“Industries” 被拆分在第2块和第3块之间。这使得我们的系统难以正确理解内容。
2、句子级别的切分:尊重自然边界
一种更智能的方法是按完整的句子进行切分:
import nltk # Natural Language Toolkit library
def sentence_based_chunk(text, max_sentences=1)
sentences = 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 855
855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









