






前言
前面的文章介绍了browser-use的基本使用,今天带来的分享是使用browser-use进行一次数据爬取的实战(不过还是demo级别的)。
使用到的三个玩法分别是使用自己的浏览器、定义输出结构与注册一个行为。

实践
使用自己的浏览器
首先解决使用自己的浏览器。
代码:
from langchain_openai import ChatOpenAI
from browser_use import Agent
from browser_use.browser.browser import Browser, BrowserConfig
from dotenv import load_dotenv
import os
load_dotenv()
import asyncio
api_key = os.getenv('Silicon_Cloud_API_KEY')
base_url = os.getenv('Base_URL')
model = os.getenv('Model')
browser = Browser(
config=BrowserConfig(
# NOTE: you need to close your chrome browser - so that this can open your browser in debug mode
# d:\Learning\AI-related\browser-use-demo\.env注意:您需要关闭您的Chrome浏览器,以便此操作可以在调试模式下打开您的浏览器
chrome_instance_path=r'C:\Program Files\Google\Chrome\Application\chrome.exe',
)
)
llm = ChatOpenAI(model=model, api_key=api_key, base_url=base_url)
async def main():
agent = Agent(
task="获取https://cloud.siliconflow.cn/bills的账单信息",
llm=llm,
browser=browser,
use_vision=False,
)
result = await agent.run()
print(result)
asyncio.run(main())
将chrome_instance_path替换为你自己的浏览器路径。
为什么要使用自己的浏览器呢?
有一个好处就是你登录过的保存信息的网站就可以直接登录不用验证了。
就比如我想查看我硅基流动的账单一样,如果不用自己的浏览器还要进行登录操作,用自己的浏览器如果保存信息了就不用再登了。
模型我选择的是:Qwen/Qwen2.5-72B-Instruct。
查看效果:
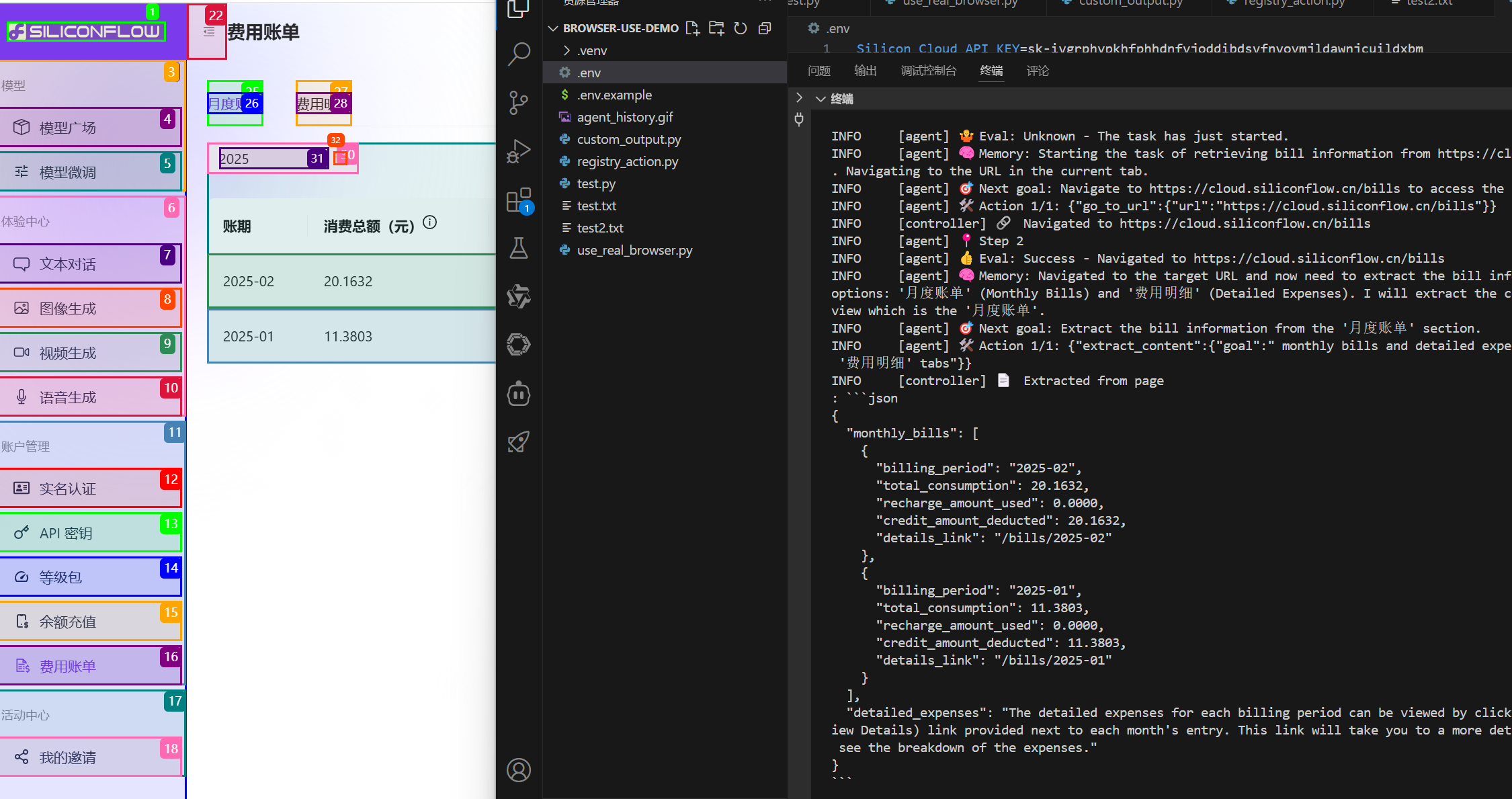
准确获取到了我们想要的数据。
定义自定义输出
其次,我们来定义自定义输出。
代码:
from langchain_openai import ChatOpenAI
from browser_use import Agent
from browser_use.browser.browser import Browser, BrowserConfig
from dotenv import load_dotenv
import os
from pydantic import BaseModel
import asyncio
from typing import List
from browser_use import ActionResult, Agent, Controller
load_dotenv()
api_key = os.getenv('Silicon_Cloud_API_KEY')
base_url = os.getenv('Base_URL')
model = os.getenv('Model')
browser = Browser(
config=BrowserConfig(
# NOTE: you need to close your chrome browser - so that this can open your browser in debug mode
# d:\Learning\AI-related\browser-use-demo\.env注意:您需要关闭您的Chrome浏览器,以便此操作可以在调试模式下打开您的浏览器
chrome_instance_path=r'C:\Program Files\Google\Chrome\Application\chrome.exe',
)
)
class Bill(BaseModel):
account_period: str
total_consumption : float
controller = Controller(output_model=Bill)
llm = ChatOpenAI(model=model, api_key=api_key, base_url=base_url)
async def main():
agent = Agent(
task="""
获取https://cloud.siliconflow.cn/bills的账单信息。
""",
llm=llm,
controller=controller,
browser=browser,
use_vision=False,
)
result = await agent.run()
print(result)
asyncio.run(main())
效果:
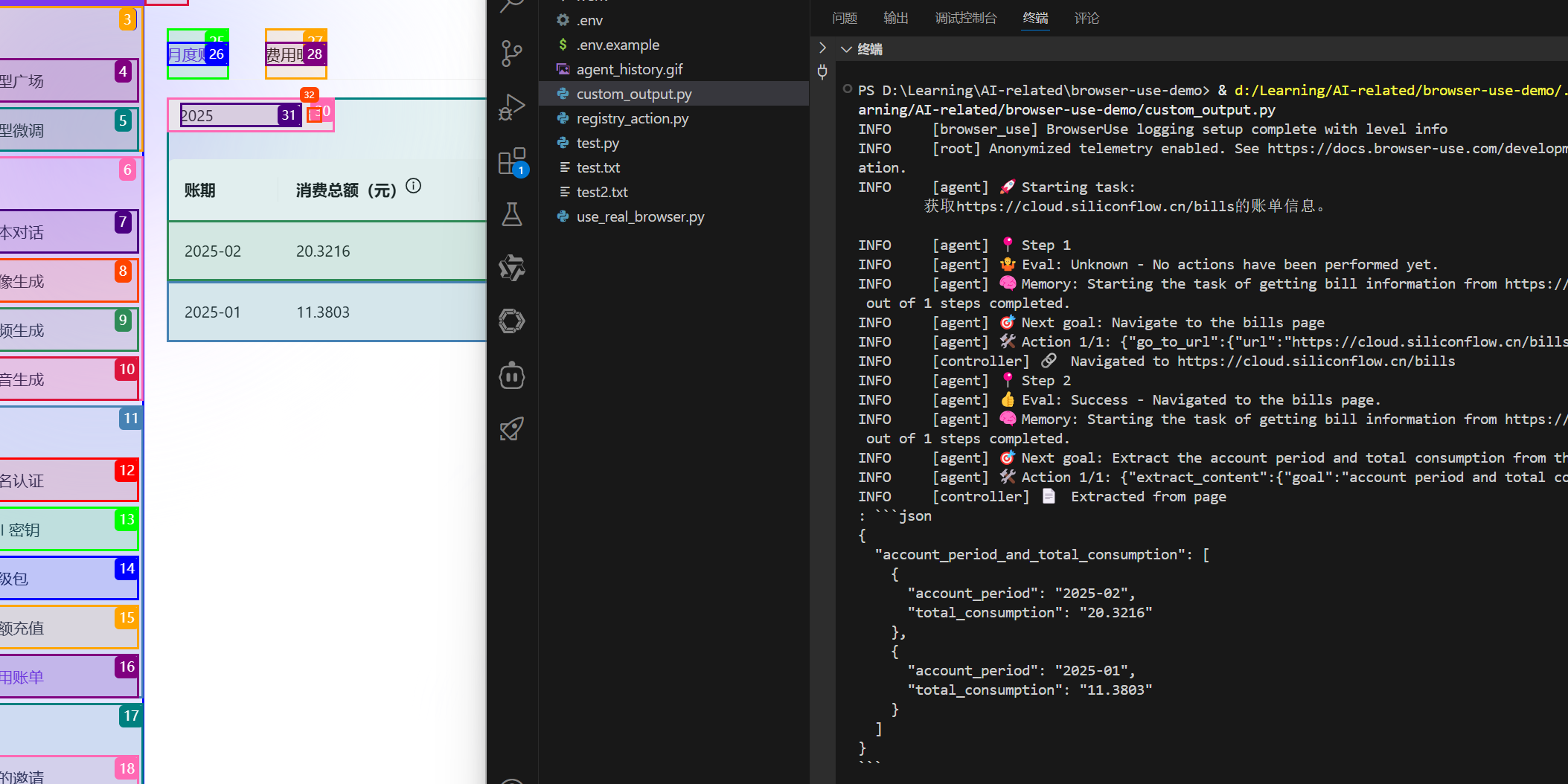
使用到了自己定义的数据结构。
注册一个行为
比如我想把结果保存到一个文件中。
代码:
from langchain_openai import ChatOpenAI
from browser_use import Agent, Controller
from browser_use.browser.browser import Browser, BrowserConfig
from browser_use.agent.views import ActionResult
from dotenv import load_dotenv
import os
load_dotenv()
import asyncio
api_key = os.getenv('Silicon_Cloud_API_KEY')
base_url = os.getenv('Base_URL')
model = os.getenv('Model')
browser = Browser(
config=BrowserConfig(
# NOTE: you need to close your chrome browser - so that this can open your browser in debug mode
# d:\Learning\AI-related\browser-use-demo\.env注意:您需要关闭您的Chrome浏览器,以便此操作可以在调试模式下打开您的浏览器
chrome_instance_path=r'C:\Program Files\Google\Chrome\Application\chrome.exe',
)
)
controller = Controller()
@controller.registry.action('保存结果到指定文件')
def save_to_file(text: str,file_path: str):
with open(file_path, 'w') as f:
f.write(text)
return ActionResult(extracted_content=text)
llm = ChatOpenAI(model=model, api_key=api_key, base_url=base_url)
async def main():
agent = Agent(
task="获取https://cloud.siliconflow.cn/bills的账单信息,并将结果保存到test3.txt。",
llm=llm,
controller=controller,
browser=browser,
use_vision=False,
)
result = await agent.run()
print(result)
asyncio.run(main())
效果:
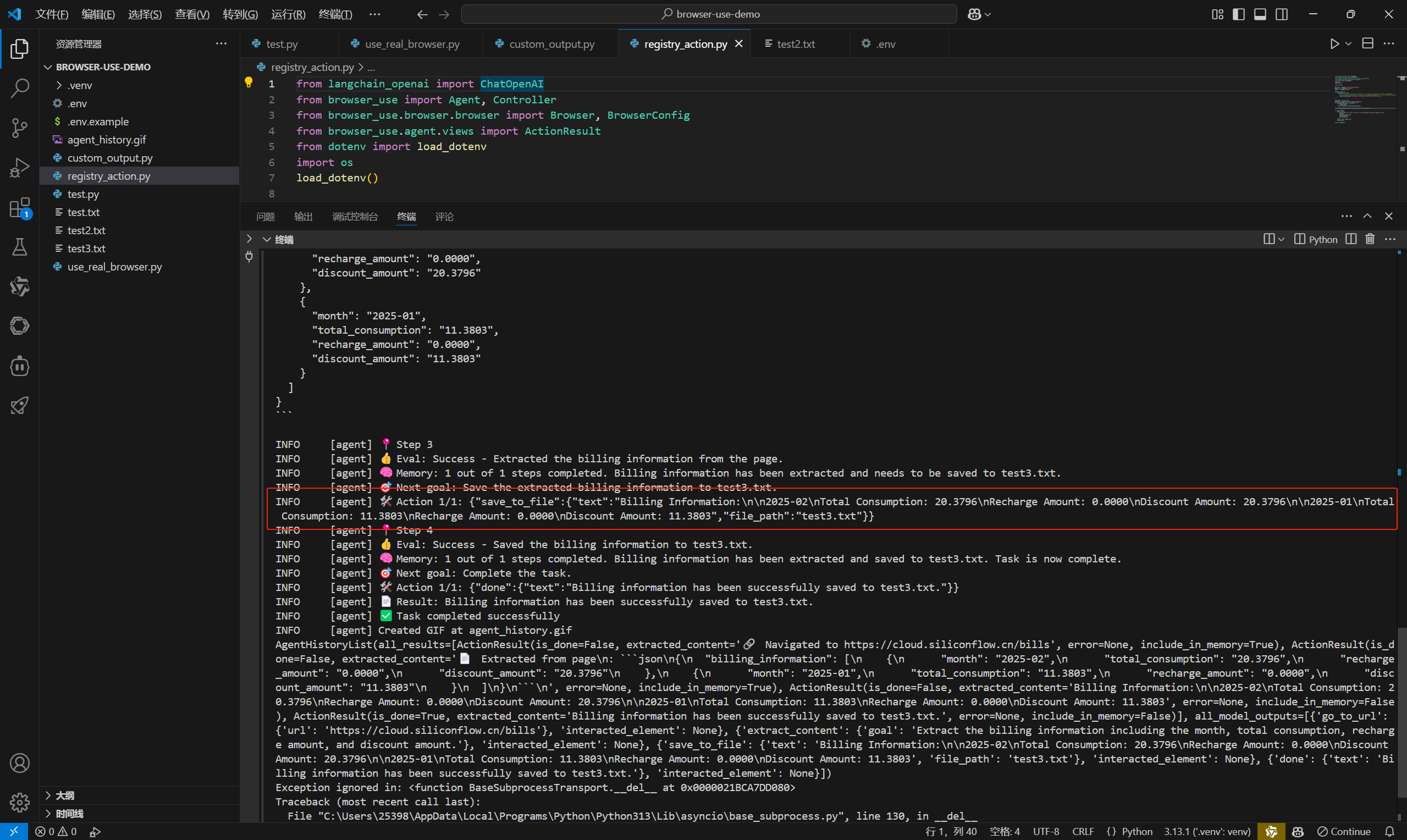
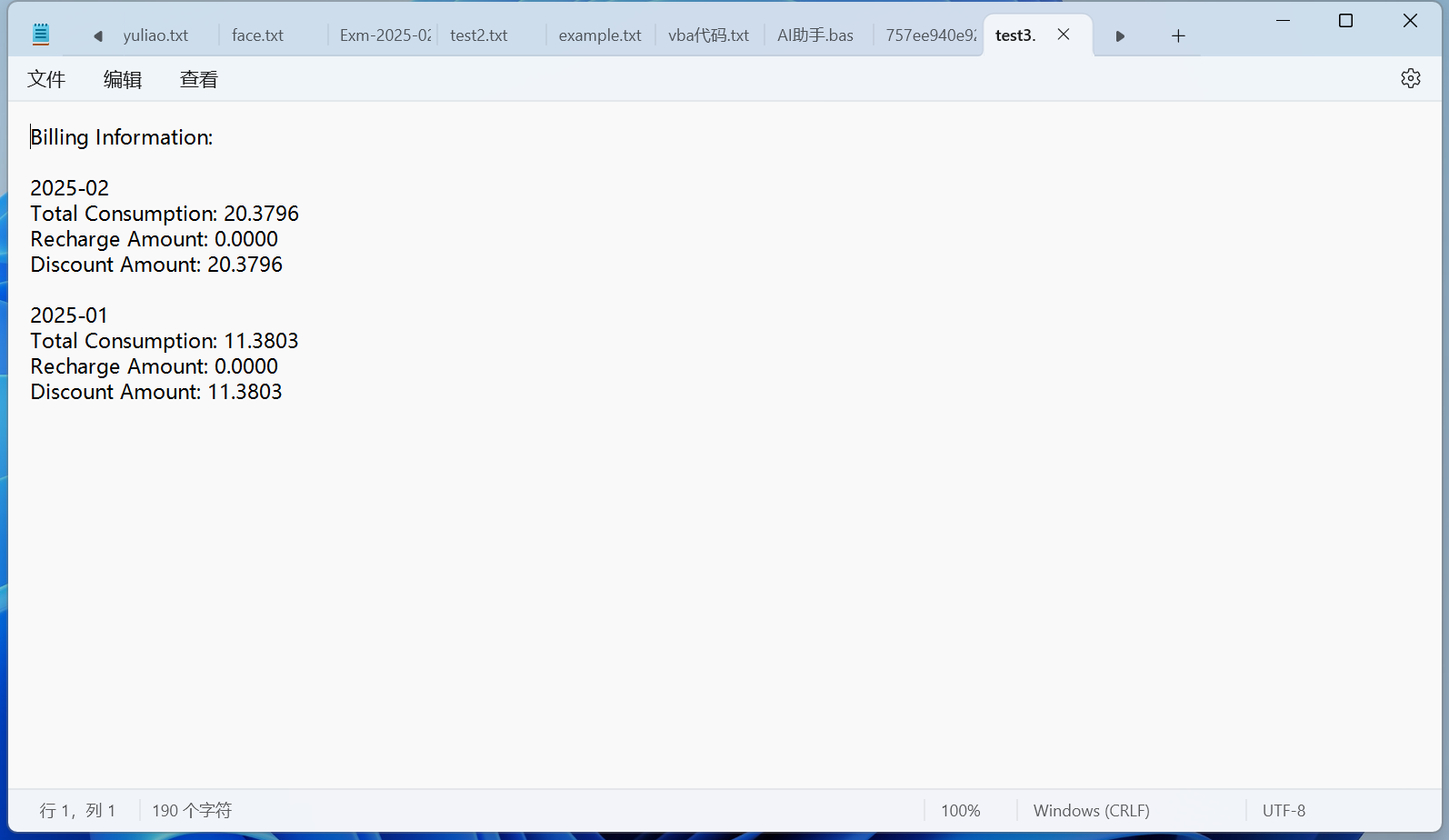
最后
以上就是使用browser-use进行一次数据爬取的实战记录,更多玩法可由读者自行探索。


















 1961
1961




 到【灌水乐园】发言
到【灌水乐园】发言







