







关注过我的老粉,想必都知道,本渣渣是写过一些Pyhton爬虫的,虽然本渣渣代码水平跟垃圾佬捡的垃圾一样垃圾,一样菜,但是不妨碍本渣渣装比!
近期日更了一波DIY电脑文章,想必那批老粉都取关了吧?!
很久没写爬虫了,现在就水一篇,证明我还在!
写的比较渣,将就着看,写一篇少一篇?!
有什么问题可以联系加群一起探讨交流,群里大佬多哈!
案例网站:
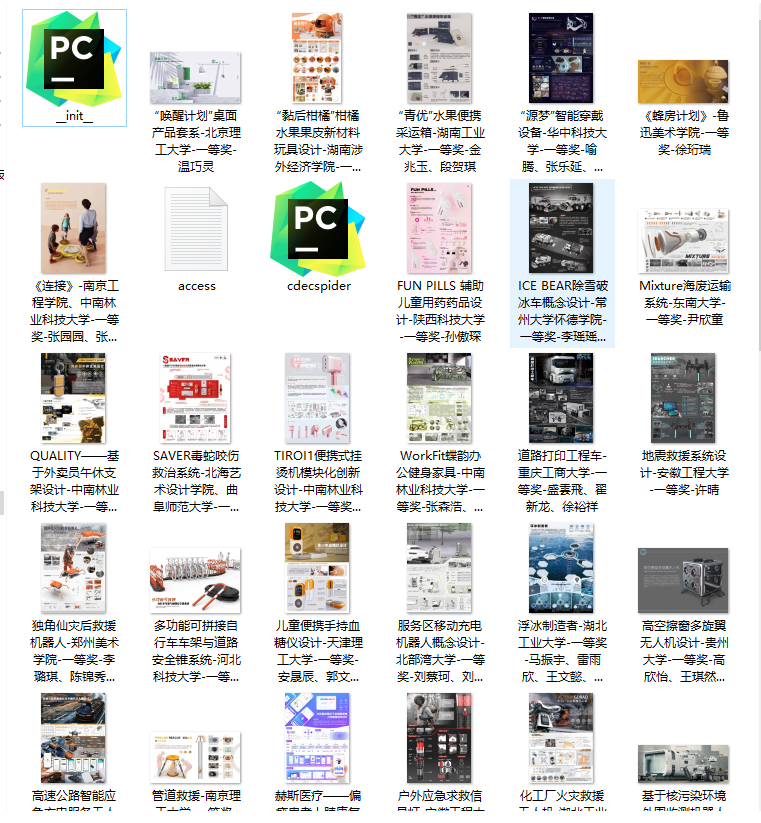
爬取效果:
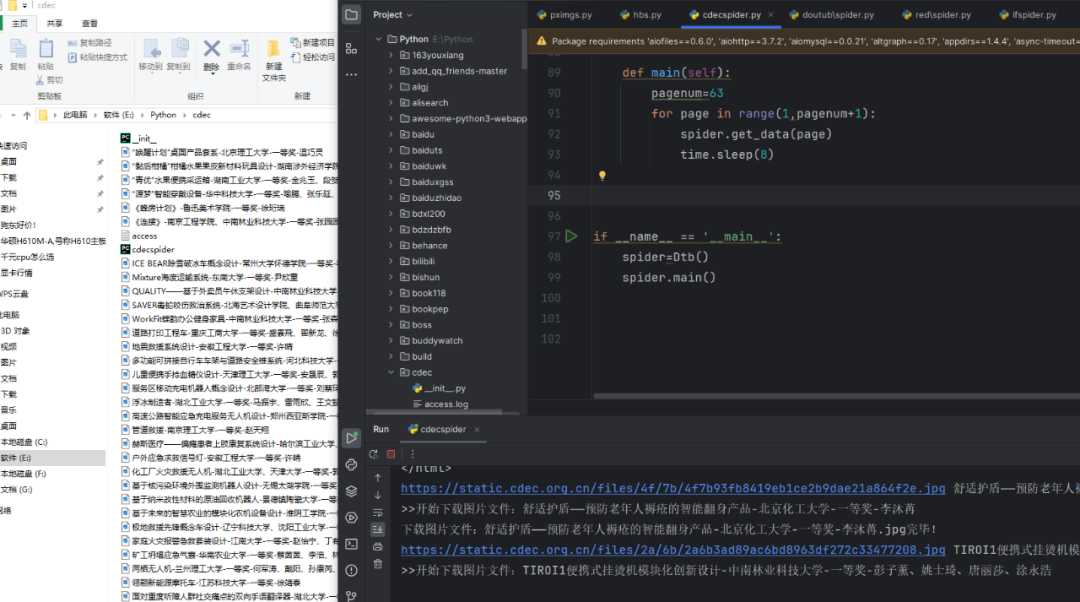
爬取日志:

关键数据获取源码:
html=response.content.decode('utf-8')
tree=etree.HTML(html)
imgs=tree.xpath('//div[@class="worksList"]/a[@class="item"]/img/@data-funlazy')
names=tree.xpath('//div[@class="worksList"]/a[@class="item"]/div[@class="info"]/div[@class="fnt_16"]/text()')
colleges=tree.xpath('//div[@class="worksList"]/a[@class="item"]/div[@class="info"]/div[@class="college fnt_16"]/text()')
awards=re.findall(r'<div class="line"></div>\n<div class="desc fnt_14">(.+?)</div>\n<div class="desc fnt_14">',html, 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









