



相信不少老哥的爬虫之路都是从图片爬取开始的,之所以走上这条不归路,不就是爬几个小(美)破(女)图么,本渣渣也写过不少图片爬虫,有一篇妹子图的爬虫可谓是手把手实战教学,印象深刻,对于图片素材类爬取,不同人群有着不同的用途,就看你的初衷是什么了。
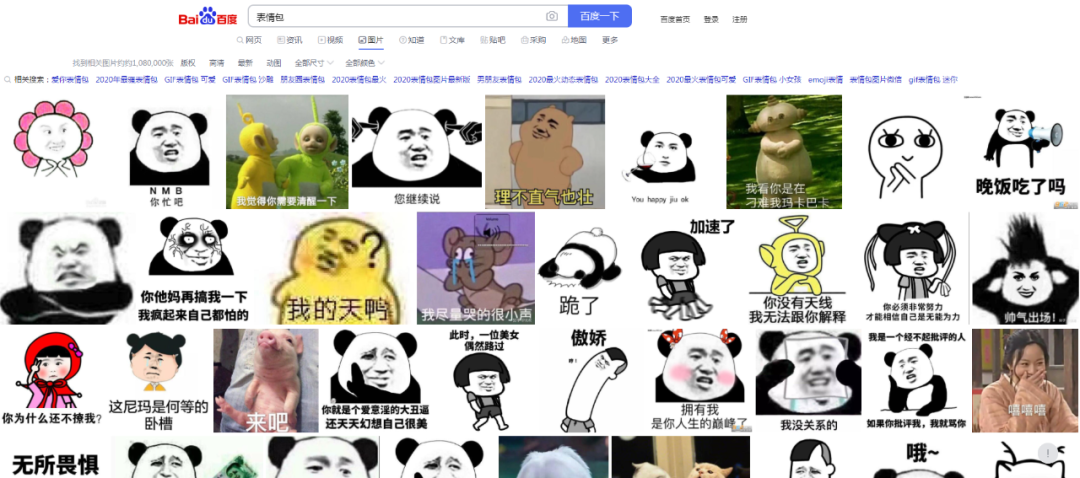
下面本渣渣带来一篇图片爬虫,某度的搜索图片爬虫,简单的使用了线程池的多线程爬取,比较简单,知晓了接口数据的调用就可以简单的实现,只需要输入查询关键词及页码即可以获取到想要的图片数据,同时也打包了一下exe脚本工具,供各位大表哥们看着玩!
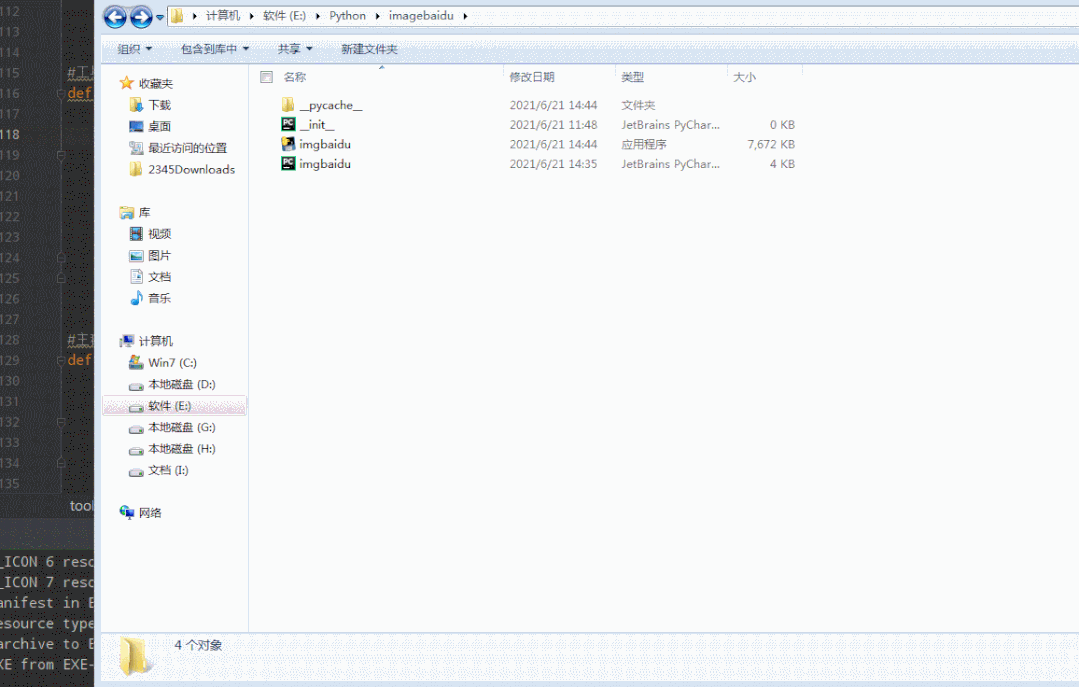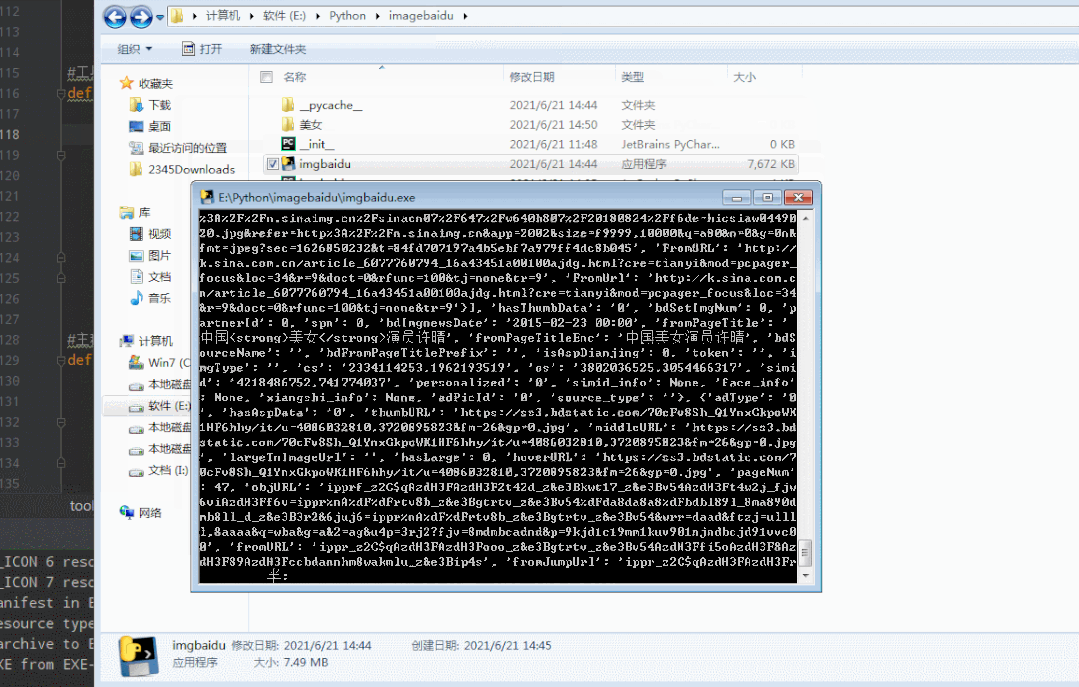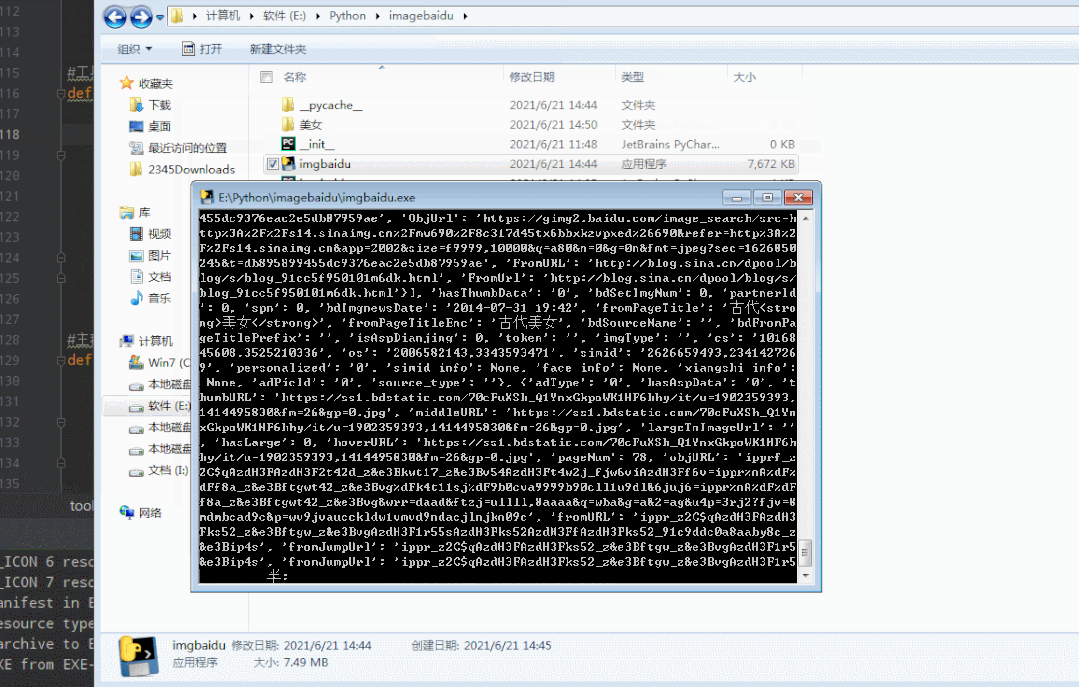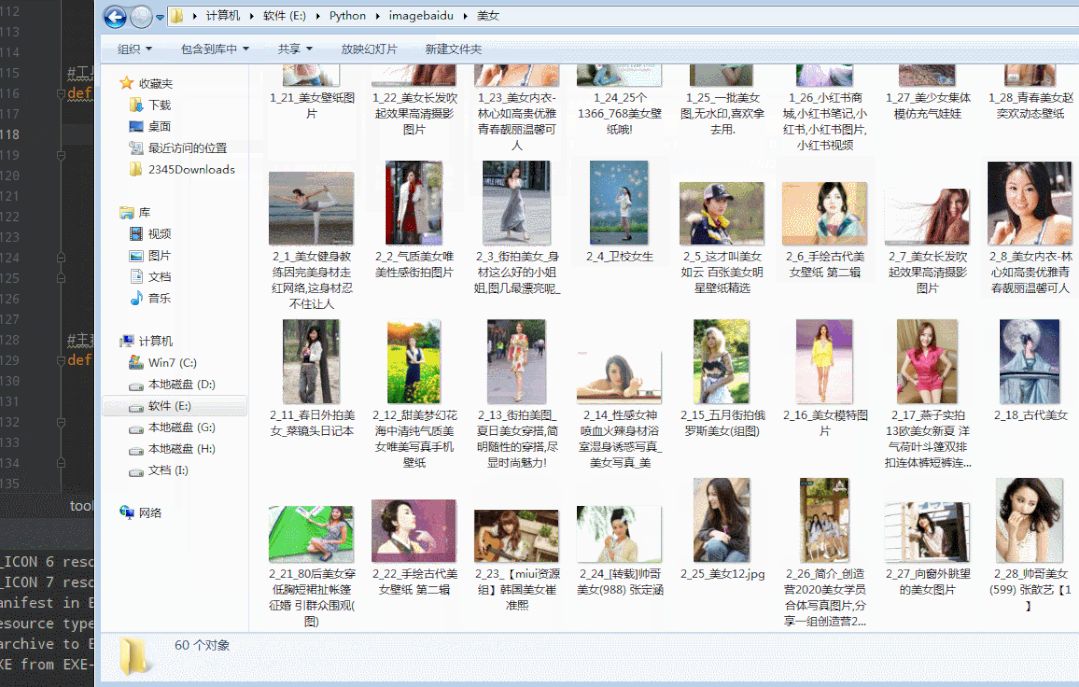
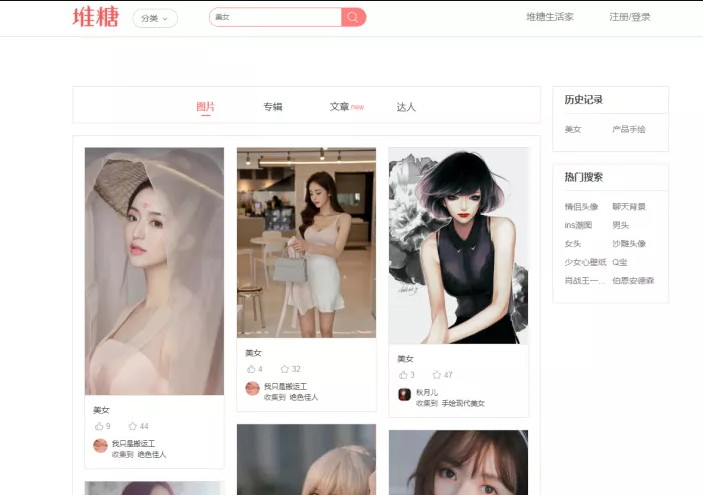
exe工具助手运行效果,文末可获取工具
爬取图片的初衷肯定是用于网站配图,毕竟本渣渣乡下狗,跟不上城里人的营养节奏,营养快线没钱买啊,每瓶喝完必须添盖!
不过此类图片的使用需要注意规避版权,同时也需要注意过滤掉有水印的图片,当然如果你想要用于网站上,避免图片版权纠纷的话,最好还是上可共享,无版权的图片吧!
比如推荐下面这个:
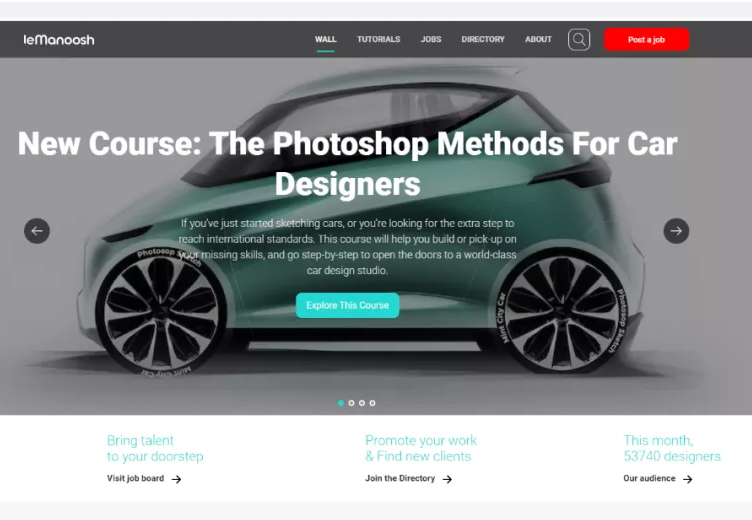
获取素材图无忧,Pixabay图库网Python多线程采集下载
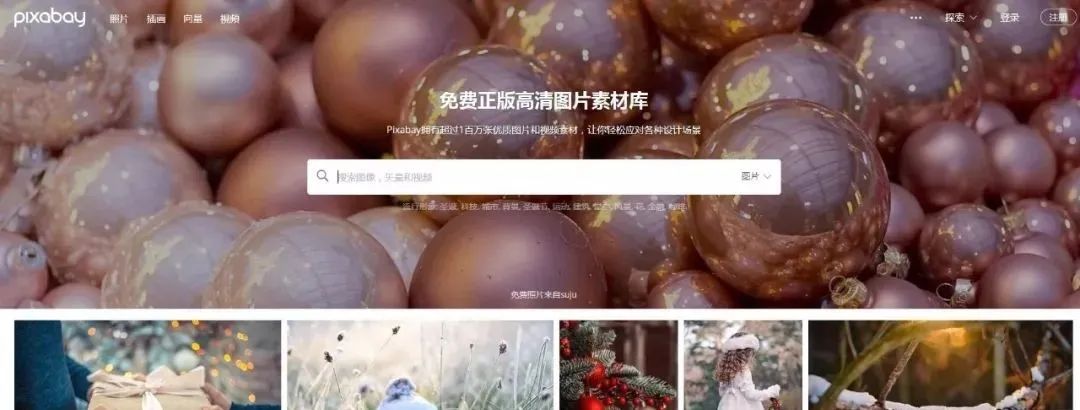
获取图片数据关键源码
#获取图片数据
def get_imglist(word,page,path):
print(f">> 正在爬取第 {page} 页图片数据..")
img_data=[]
url="https://image.baidu.com/search/acjson?"
headers = {
"User-Agent": UserAgent().random,
"X-Requested-With": "XMLHttpRequest"
}
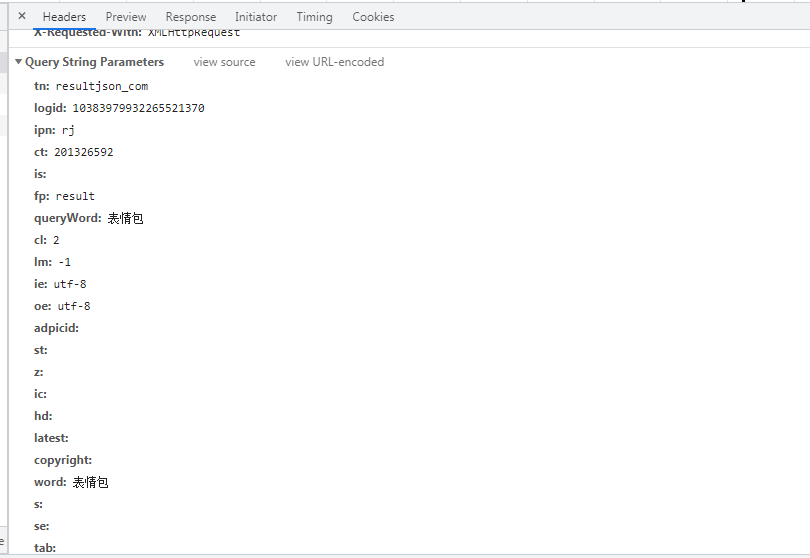
params={
"tn": "resultjson_com",
"logid": "10383979932265521370",
"ipn": "rj",
"ct": "201326592",
"is": "",
"fp": "result",
"queryWord": word,
"cl": "2",
"lm": "-1",
"ie": "utf-8",
"oe": "utf-8",
"adpicid": "",
"st": "",
"z": "",
"ic": "",
"hd": "",
"latest": "",
"copyright": "",
"word": word,
"s": "",
"se": "",
"tab": "",
"width": "",
"height": "",
"face": "",
"istype": "",
"q": "",
"nc": "1",
"fr": "",
"expermode:": "",
"nojc": "",
"pn": 30*page,
"rn": "30",
"gsm": "1e",
"1624245957244": "",
}
response=requests.get(url=url,params=params,headers=headers,timeout=5)
time.sleep(2)
json_data=response.json()
print(json_data)
data_lists=json_data['data']
print(data_lists)
i=1
for data_list in data_lists:
if data_list:
title=data_list['fromPageTitleEnc']
print(title)
title=get_title(title)
title=f'{page}_{i}_{title}'
thumbURL=data_list['thumbURL']
print(thumbURL)
imgdata=title,thumbURL,path
img_data.append(imgdata)
i=i+1
return img_data
经常撸某度的话,应该比较熟悉,其参数比较繁多,各种记录数据,爬取图片数据除了关键词的参数之外,就是页码数需要注意了,"pn": 30*page 就是页码数,30个数据一页!
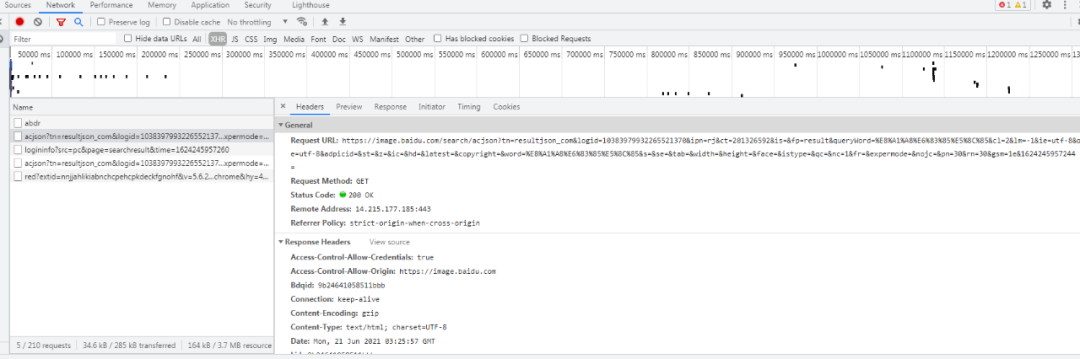
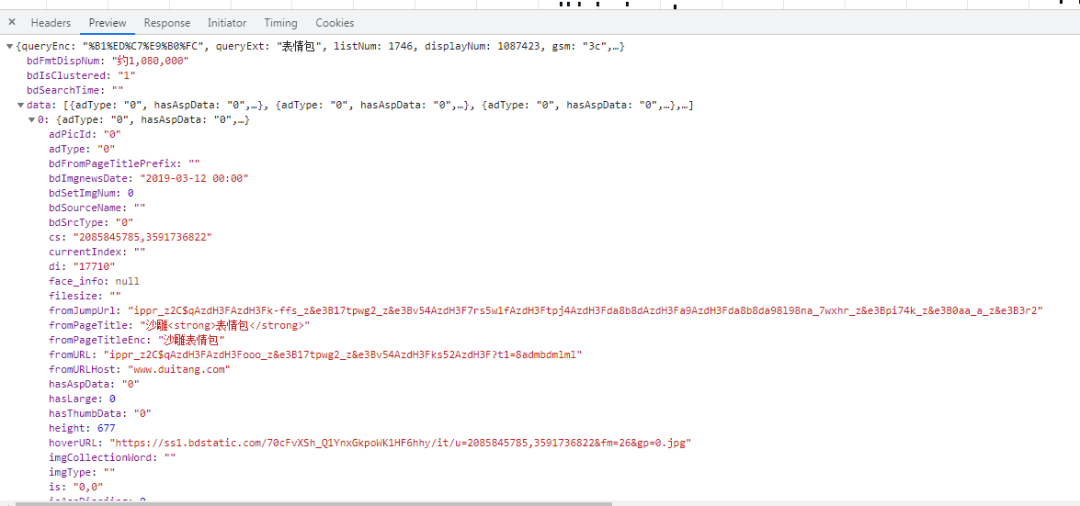
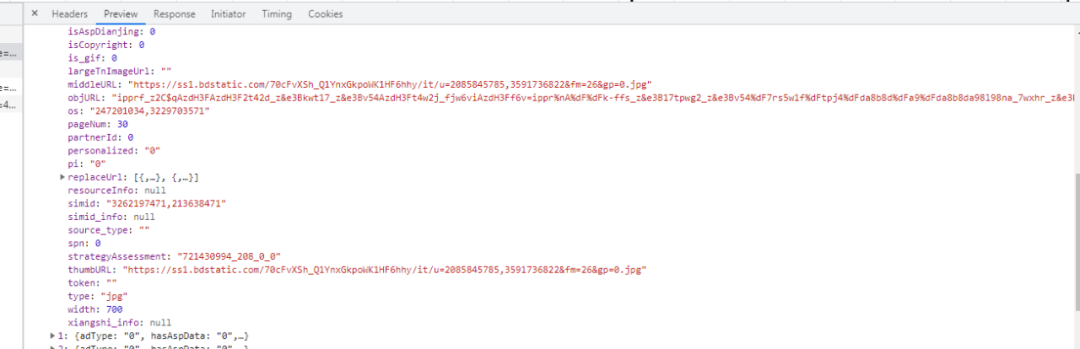
浏览器抓包数据参考
线程池多线程源码
#多线程下载图片
def Thread_down_img(img_data):
try:
# 开4个 worker,没有参数时默认是 cpu 的核心数
pool = ThreadPool()
results = pool.map(dowm_img,img_data)
pool.close()
pool.join()
except:
print("Error: unable to start thread")
print("多线程下载图片完成!")
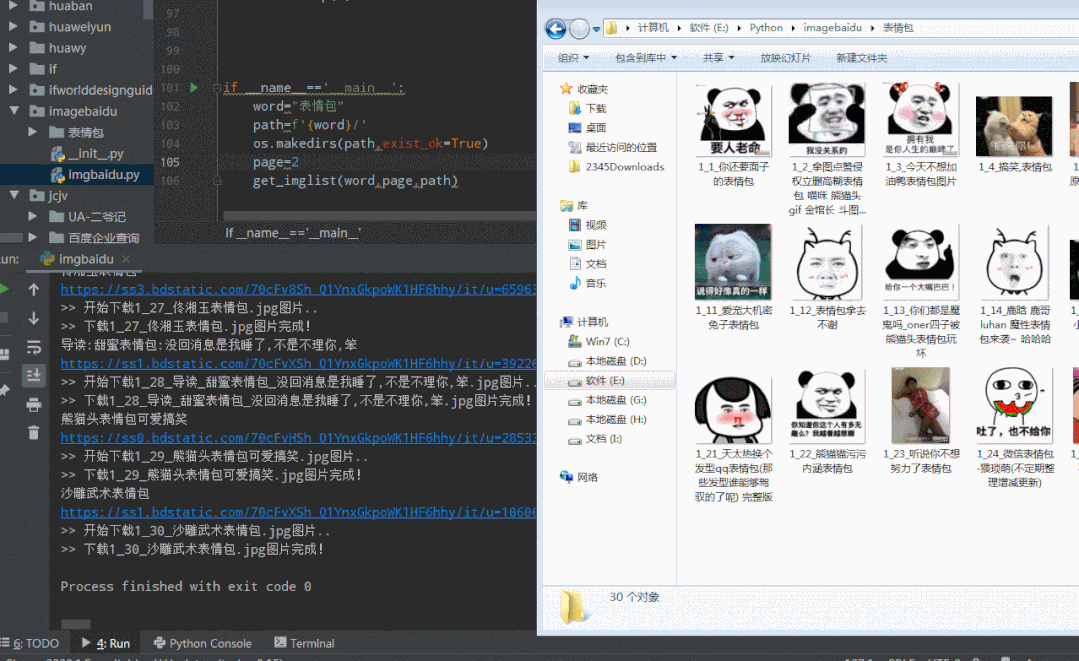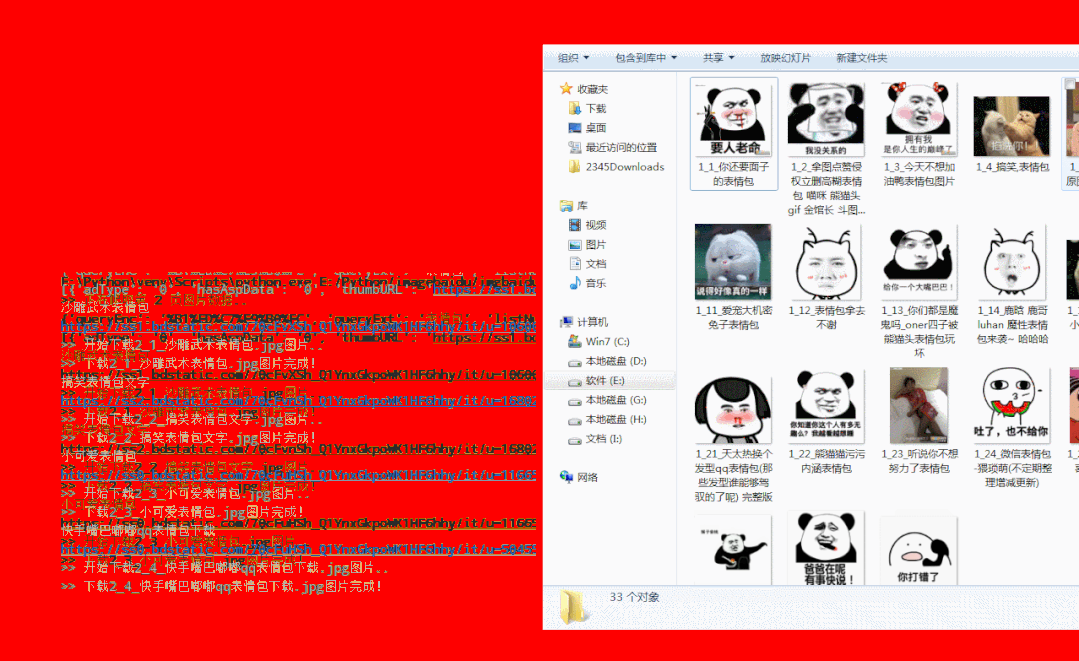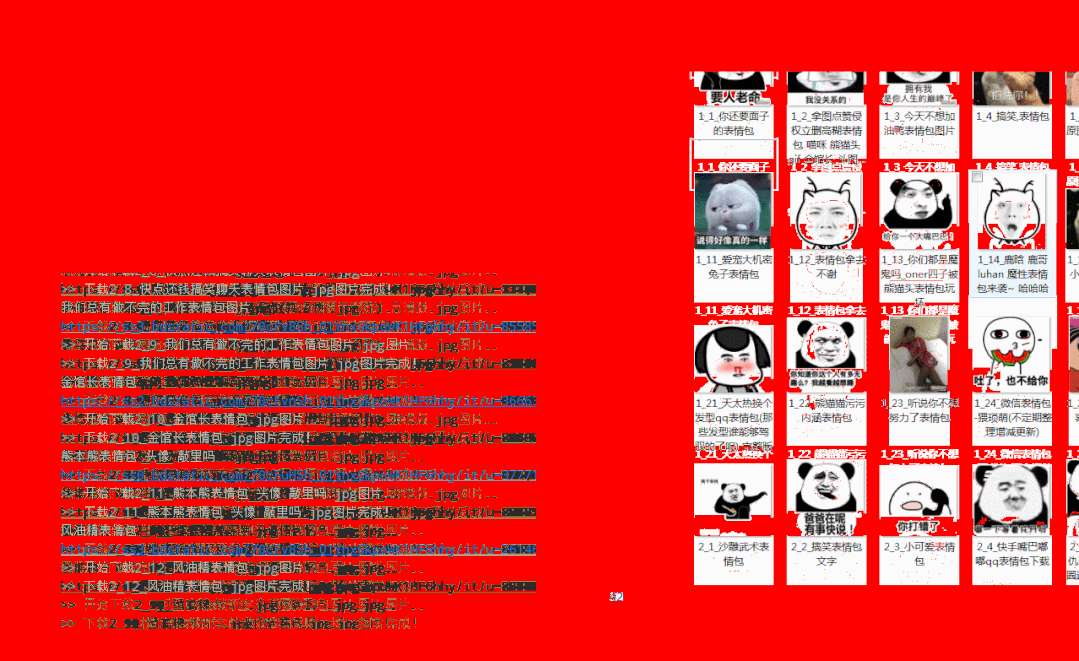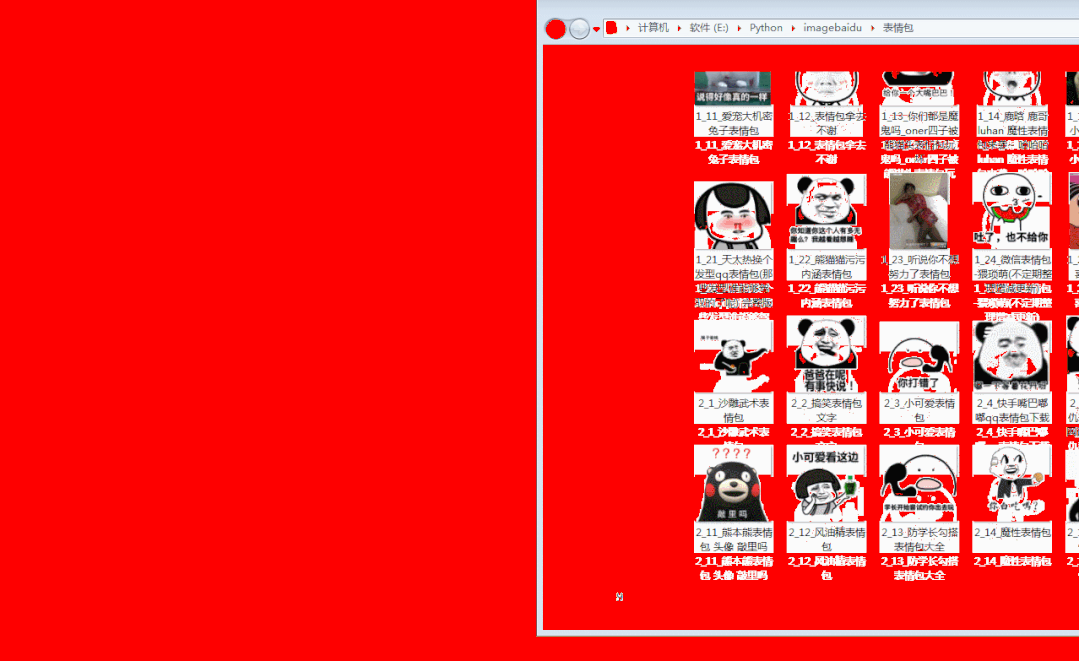
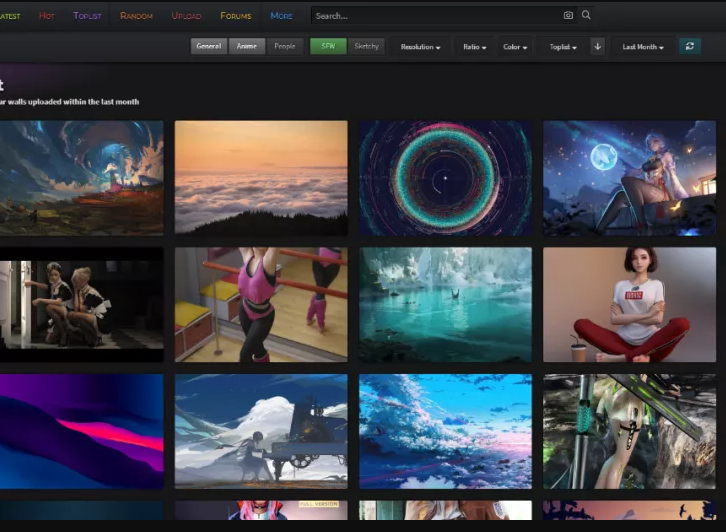
图片爬取运行效果

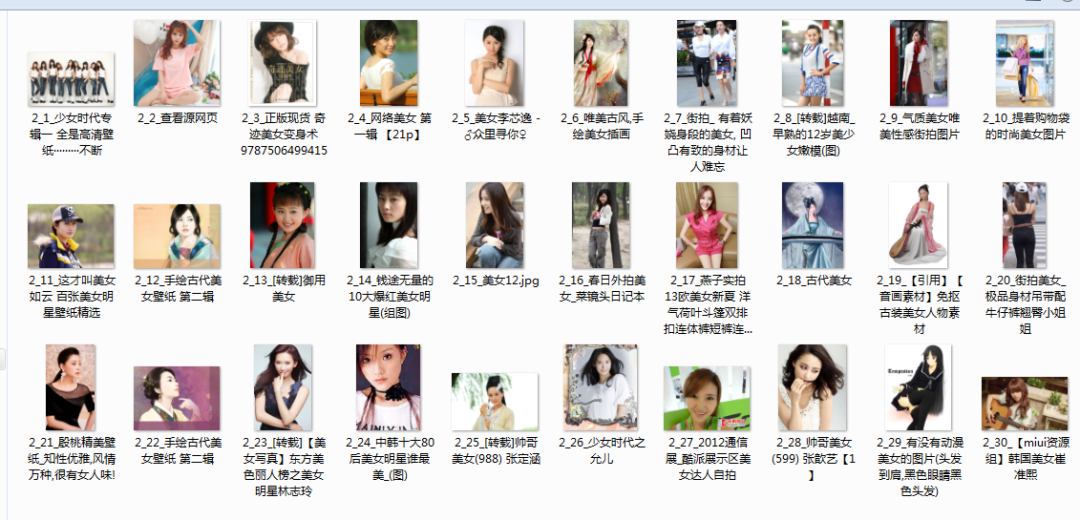
完整爬虫源码及exe工具获取
长按二维码关注公众号

后台回复:某度图片爬虫

推荐阅读


·················END·················
你好,我是二大爷,
革命老区外出进城务工人员,
互联网非早期非专业站长,
喜好python,写作,阅读,英语
不入流程序,自媒体,seo . . .
公众号不挣钱,交个网友。
读者交流群已建立,找到我备注 “交流”,即可获得加入我们~
听说点 “在看” 的都变得更好看呐~
关注关注二大爷呗~给你分享python,写作,阅读的内容噢~
扫一扫下方二维码即可关注我噢~

关注我的都变秃了
说错了,都变强了!
不信你试试

扫码关注最新动态
公众号ID:eryeji

















 3324
3324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









