






每一套数据库在运行一段时间后业务基本上会趋于稳定,此时DBA可以收集关键点的数据值,通过拟合方法来计算出阈值,根据这些阈值判断I/O是否慢,进而判断是否是性能问题的潜在原因。
如何计算出合理的阈值
多项式拟合方法
多项式拟合函数是一类基本和常见的拟合函数,常用的理论是对于最小二乘法,再基于由内积运算得来的“法方程组”来确定拟合函数系数,接下来直接给出多项式函数的法方程组。
对于多项式幂函数 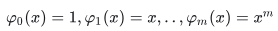 由内积运算
由内积运算 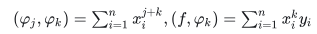 这样得到法方程如下:
这样得到法方程如下:
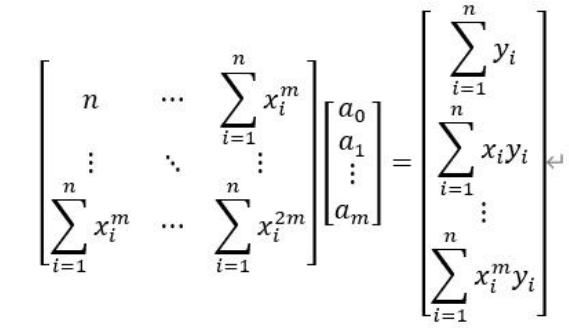
从上述矩阵表达形式我们知道,系数向量 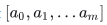 就是求得的最优系数向量。当m比较大也就是多项式拟合次数过于高时,该线性方程组往往是病态的,幂次运算过大而导致误差过大,所以一般会采用斯密特正交多项式来进行拟合修正。
就是求得的最优系数向量。当m比较大也就是多项式拟合次数过于高时,该线性方程组往往是病态的,幂次运算过大而导致误差过大,所以一般会采用斯密特正交多项式来进行拟合修正。
建立异常值检测步骤
“拟合”非常适用于大的数据集(插值一般适用于小的数据集),一般情况下,会选择3次左右的多项式来进行拟合,达到一种非线性效果,所以当应用于实际数据时进行如下步骤: 1.对数据进行多项式拟合,选择合理的多项式阶数, 2.对拟合出来的多项式曲线进行上下界的选取,一般会选择拟合出的数据集的标准差倍数,也可以是此数据集的均值倍数等等, 3.把在上下界之外的数据集作为异常值处理。
代码示例
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
plt.rcParams['font.sans-serif']=['SimHei']##中文乱码问题!
plt.rcParams['axes.unicode_minus']=False#横坐标负号显示问题!
choosedata = pd.read_csv('建模数据.csv', index_col=0)
def check_outlier(data,multi):
colls = list(data.columns)##获取数据的所有列名
for i in colls:
plt.figure(figsize=(15,8))
value = data[i]##拟合+统计法
x = [j for j in range(len(value))]
coeffs = np.polyfit(x, value, 3) ##专门求多项式估计参数的函数
p = np.poly1d(coeffs) # 一元估计参数
sigm = p(x).std()
sigm_up = p(x) + multi * sigm
sigm_down = p(x) - multi * sigm
fil_S = value[(value >= sigm_down) & (value <= sigm_up)]#条件筛选
print('\033[1;32m原数据长度:%s,经过异常排除后还剩:%s\033[0m'%(len(value),len(fil_S)))
plt.scatter(x,value,label='原始数值')
plt.plot(p(x),'r',label='拟合曲线')
plt.plot(sigm_up,'g',label='拟合上限曲线')
plt.plot(sigm_down,'b',label='拟合下限曲线')
plt.legend(fontsize=15)
plt.tick_params(labelsize=15)
plt.show()
check_outlier(choosedata,6)
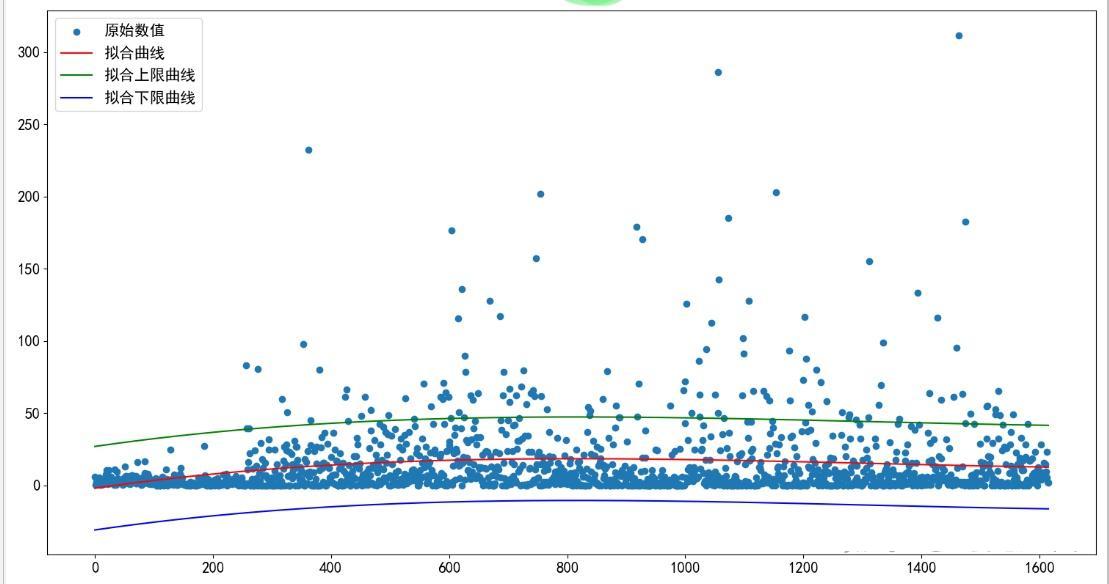
通过归纳出来的曲线图就可以估算出阈值的上下限以及baseline。
衡量IO效率
1.响应时间 以毫秒为单位测量操作完成所需的时间。 此统计信息由Oracle收集。 2.吞吐量 以每单位时间的操作次数来衡量。 这是使用操作系统工具计算的,例如 linux上的iostat。
什么是“慢”
“慢”是一个非常主观的术语,很大程度上取决于您对系统和硬件的期望。 具有企业级存储系统的用户可能期望所有 IO 请求在10 毫秒内返回,但是使用旧的 USB 1.0 接口连接的旧笔记本电脑的用户在使用外部磁盘时的期望值会有所不同。
此外,最终用户将期望 OLTP 请求和报告的响应时间一致。如果响应时间发生显著变化,这可能是由于平均 IO 响应时间发生变化,即使新旧响应时间都小于可被视为标准的合理 IO 响应时间(例如,从 3 毫秒降级到 9 毫秒可能 对应用程序性能有重大影响,但在时间超过 20 毫秒之前,IO 可能不会被视为“慢”)。 IO 响应时间变化的原因多种多样,示例可能包括从文件系统缓存迁移到没有文件系统缓存的共享磁盘,或更改系统备份计划,使 IO 流量与批处理作业重叠。
响应时间
硬件不一定以统一的方式响应每个 IO 请求,总会有高峰和低谷。因此,通常使用平均值来测量响应时间。
IO 类型
平均响应时间与IO类型直接相关
读或写
physical writes/reads Logic writes/reads
单块或多块
单块IO,顾名思义,一次只读一个。 例如,当会话等待单块 IO 时,它通常可能会等待事件"db file sequential read"以提示它正在等待该块被传送。
多块操作一次读取多个块,范围从 2 到 128 个 Oracle 块,具体取决于块大小和操作系统设置。 多块请求的大小通常限制为 1Mb。
例如,当一个会话在等待多块IO时,它通常会等待事件"db file scatter read"来表明它正在等待那些块被传递。
同步或异步
同步(阻塞)操作等待硬件完成物理 I/O 并发出操作成功或失败的信号(并在成功读取的情况下接收结果),以便对其进行适当的管理。在等待系统调用的结果时进程的执行被阻塞。
对于异步(非阻塞)操作,一旦 I/O 请求向下传递到硬件或在操作系统中排队(通常在物理 I/O 操作开始之前),系统调用将立即返回。 进程的执行不会被阻塞,因为它不需要等待系统调用的结果。 相反,它可以继续执行并稍后在可用时接收I/O 操作的结果。
响应时间的预期阈值
在担心“IO慢”之前,典型的 64 x 8k 块(总计 512kB)的多块同步读平均应该最多 20 毫秒。 较小的请求应该更快(10-20 毫秒),而对于较大的请求,经过的时间不应超过 25 毫秒。
-
异步操作应该与同步操作一样快或更快。
-
单块操作应该与多块操作一样快或更快。
-
'log file parallel write', 'control file write' 和 'direct path writes' 等待时间不应超过 15 毫秒。
数据文件写入不像读取那样容易测量。DBWR 批量异步写入块('db file parallel write'),目前没有标准来评判响应时间。
其他等待事件和统计信息用于判断 DBWR (多块或单块,或者没有 IO slave)清理脏块是否足够快。 作为一项原则,比上述时间更长的问题更应该调查,在与之前的时间比较时,应该注意到任何更糟的变化。
响应时间因系统而异。 例如,以下可被视为可以接受的平均值: 10 ms 的多块同步读 5 ms 的单块同步读 3 ms 的 'log file parallel write' 基于这样的前提,多块 IO 可能比单块 IO 需要更多的 IO 子系统工作,所以建议重做日志要放到没有其他并发活动的最快磁盘上。
IO 等待异常值(短暂间歇性 IO 延迟)
即使平均 IO 等待时间可能完全在接受的范围内,性能中的"hiccups" 也可能是由于一些 IO 等待异常值导致的。 在 12c 中,以下视图包含与耗时较长的 I/O 对应的条目(500 ms以上)。 在 11g 中,AWR 报告的Wait Event Histogram部分可能有助于确定是否有 IO 花费的时间超过平均时间。 超过 500 ms的日志写入等待也会写入 LGWR 跟踪文件
识别 IO 响应时间
Oracle 将 IO 操作的响应时间记录为特定等待事件和统计信息中的"Elapsed Time"。"Response time"和"Elapsed time"在此上下文中是同义词并可互换的术语。 下面列出了一些常见的等待事件及其通常可接受的等待时间(并非详尽列表)(包括带有 SSD 的 SAN 存储系统)
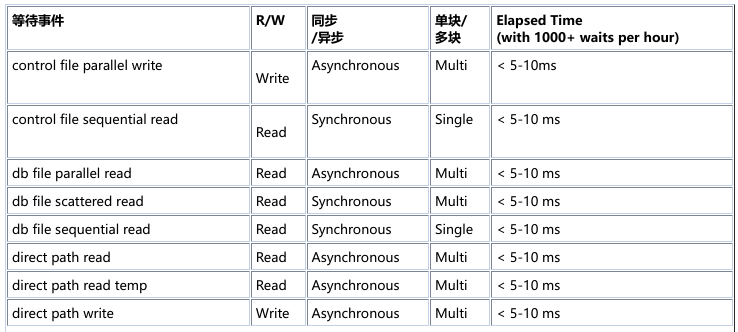

Oracle 中识别响应时间的来源
10046 Trace File
级别 8 或 12的10046 跟踪将包括等待事件。 在 ela 字段中可以看到Elapsed Time。 从 9i 开始,该值以微秒为单位指定。 在8i 和之前的时间是 1/100 秒(10 毫秒)。
WAIT #5: nam='cell single block physical read' ela= 672 cellhash#=2520626383
diskhash#=1377492511 bytes=16384 obj#=63 tim=1280416903276618
672 microseconds = 0.672 ms
WAIT #5: nam='db file sequential read' ela= 1018 file#=2 block#=558091 blocks=1 obj#=0
tim=10191852599110
1018 microseconds => 1.018 ms
System State Dump
等待信息会包含在System State中的每个进程的详细信息中。进程可能正在等待:"waiting for",或者等待已经完成当前在ONCPU : "waited for" / "last wait for"。
-
"waiting for" 这意味着该进程当前处于等待状态。 在 11g 之前,要查看的字段是"seconds since wait started",它显示了发生这个等待事件的时间从 11gR1 开始,要查看的字段是"total",即此次等待所用的总时间。 如果一个进程被标记等待在IO关联的操作,并且"seconds since wait started" > 0 则很可能意味着 IO"丢失",并且会话可以被视为 Hang。(因为我们之前提到平均可接受的等待时间为 5-10 毫秒,所以任何持续时间 > 1 秒的 IO 等待都值得关注) -
"last wait for" 通常是在 11g 之前的版本出现,表示已经不处于等待的进程 (例如 ON CPU)。它记录最后一次发生的等待,等待时间显示在"wait_time"字段中。(在 11g 中之后,"last wait for"被"not in wait"代替)
last wait for 'db file sequential read' blocking sess=0x0 seq=100 wait_time=2264 seconds
since wait started=0
file#=45, block#=17a57, blocks=1
2264 microseconds => 2.264 ms
-
"waited for" 表示会话不再等待。其在11gR1之后的systemstate trace中开始被使用。要确认的字段是"total",表示等待的总时间。
0: waited for 'db file sequential read' file#=9, block#=46526, blocks=1
wait_id=179 seq_num=180 snap_id=1
wait times: snap=0.007039 sec, exc=0.007039 sec, total=0.007039 sec
wait times: max=infinite
wait counts: calls=0 os=0
0.007039 sec => 7.039 ms
AWR 报告
前台和后台的等待事件
报告分别显示前台和后台操作等待的详细说明部分。 以下是此类部分的示例:
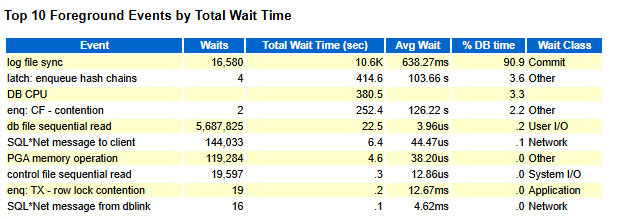
在报告中,平均响应时间显示在Avg wait (ms)列(平均读取时间,以毫秒为单位)。
表空间 IO 统计
报告的表空间部分还从表空间的角度提供了有用的信息:
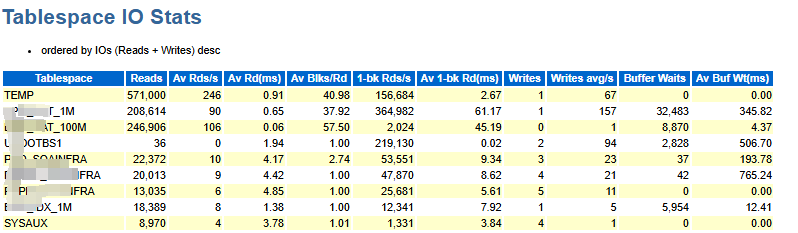
同样,读取响应时间由 Av Rd (ms) 列(平均读取时间,以毫秒为单位)表示。
等待事件的直方图
The Wait event histogram 部分提供等待事件的时间分布构成的平均值等一些有用信息。它可以显示是否是许多接近的平均值组成,或是被一些非常大或非常小的值所扭曲:
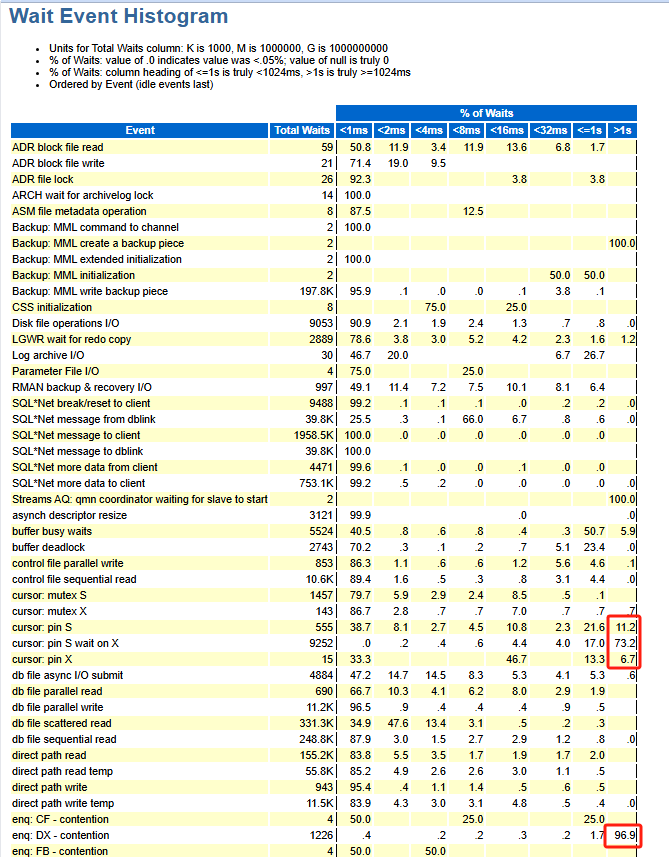
显示在每个特定时间的存储桶中,等待事件发生的百分比。 例如,"<16ms"下表示的等待时间大于"8ms"但小于"16ms"。
只要最大百分比的等待时间在 <1 ms到 <16 ms之间,那么 IO 性能通常是可以接受的。>1s的等待事件就需要关注一下。
本文由 mdnice 多平台发布


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









