






 本文介绍了编译原理的基础知识,包括高级语言、汇编语言和机器语言的特点,编译器与解释器的工作方式及优缺点,以及编译程序的各个阶段。内容涉及词法分析、语法分析、语义分析、中间代码生成和目标代码生成等,同时阐述了正规式、有限自动机与词法分析器的构建方法。
本文介绍了编译原理的基础知识,包括高级语言、汇编语言和机器语言的特点,编译器与解释器的工作方式及优缺点,以及编译程序的各个阶段。内容涉及词法分析、语法分析、语义分析、中间代码生成和目标代码生成等,同时阐述了正规式、有限自动机与词法分析器的构建方法。
编译原理基础知识点
高级语言、汇编语言与机器语言的主要特点及区别是什么?请画图表示语言之间的翻译模式。
机器语言
机器语言是用二进制代码表示的语言,是计算机唯一可以直接识别和执行的语言,它具有计算机可以直接执行、简洁、运算速度快等优点,但它的直观性差,非常容易出错,程序的检查和调试都比较困难,此外对机器的依赖型也很强。
汇编语言
汇编语言是为了解决机器语言难以理解和记忆的缺点,用易于理解和记忆的名称和符号表示机器指令中的操作码,这种用指令助记符组成的语言叫做汇编语言。机器不能直接执行用汇编语言编写的程序,它也依赖与机器的。
高级语言
高级语言为用户提供了一种既接近与自然语言,又可以使用数学表达式,还相对独立于机器的工作方式。与汇编语言一样,机器也不能直接执行用高级语言编写的程序。

编译器和解释器的工作方式有什么区别?并总结编译器与解释器的优缺点。
解释器和编译器的主要区别在于
编译器输出一个翻译完成后的可执行文件,是一个二进制数据流;解释器输出解释后运行的结果。
解释器和编译器的优缺点
解释器
优点
跨平台、启动速度快、开发效率高
缺点
执行速度慢、执行效率低
编译器
优点
执行速度快、执行效率高
缺点
平台相关性高,编译速度(启动速度)慢、开发效率低
编译程序包括那几个工作阶段?简述各个阶段的主要任务。

词法分析
词法分析器根据词法规则识别出源程序中的各个记号(token),每个记号代表一类单词(lexeme)。源程序中常见的记号可以归为几大类:关键字、标识符、字面量和特殊符号。词法分析器的输入是源程序,输出是识别的记号流。词法分析器的任务是把源文件的字符流转换成记号流。本质上它查看连续的字符然后把它们识别为“单词”。
语法分析
语法分析器根据语法规则识别出记号流中的结构(短语、句子),并构造一棵能够正确反映该结构的语法树。
语义分析
语义分析器根据语义规则对语法树中的语法单元进行静态语义检查,如果类型检查和转换等,其目的在于保证语法正确的结构在语义上也是合法的。
中间代码生成
中间代码生成器根据语义分析器的输出生成中间代码。中间代码可以有若干种形式,它们的共同特征是与具体机器无关。最常用的一种中间代码是三地址码,它的一种实现方式是四元式。三地址码的优点是便于阅读、便于优化。
中间代码优化
优化是编译器的一个重要组成部分,由于编译器将源程序翻译成中间代码的工作是机械的、按固定模式进行的,因此,生成的中间代码往往在时间和空间上有很大浪费。当需要生成高效目标代码时,就必须进行优化。
目标代码生成
目标代码生成是编译器的最后一个阶段。在生成目标代码时要考虑以下几个问题:计算机的系统结构、指令系统、寄存器的分配以及内存的组织等。编译器生成的目标程序代码可以有多种形式:汇编语言、可重定位二进制代码、内存形式。
符号表管理
符号表的作用是记录源程序中符号的必要信息,并加以合理组织,从而在编译器的各个阶段能对它们进行快速、准确的查找和操作。符号表中的某些内容甚至要保留到程序的运行阶段。
出错处理
用户编写的源程序中往往会有一些错误,可分为静态错误和动态错误两类。所谓动态错误,是指源程序中的逻辑错误,它们发生在程序运行的时候,也被称作动态语义错误,如变量取值为零时作为除数,数组元素引用时下标出界等。静态错误又可分为语法错误和静态语义错误。语法错误是指有关语言结构上的错误,如单词拼写错、表达式中缺少操作数、begin和end不匹配等。静态语义错误是指分析源程序时可以发现的语言意义上的错误,如加法的两个操作数中一个是整型变量名,而另一个是数组名等。
编译器的分析/综合模式
编译器被分为两种模式:分析、综合。
分析模式
分析模式包括词法分析、语法分析、语义分析,整个过程与具体机器无关。
综合模式
综合模式则是生成目标代码直至最后的所有过程,它与机器紧密相关。
连接这两种模式的,是中间代码。
通过一种这样的划分,我们可以使用不同的前端、后端,只要保证中间代码是相同的,编译器就照样能翻译一个程序。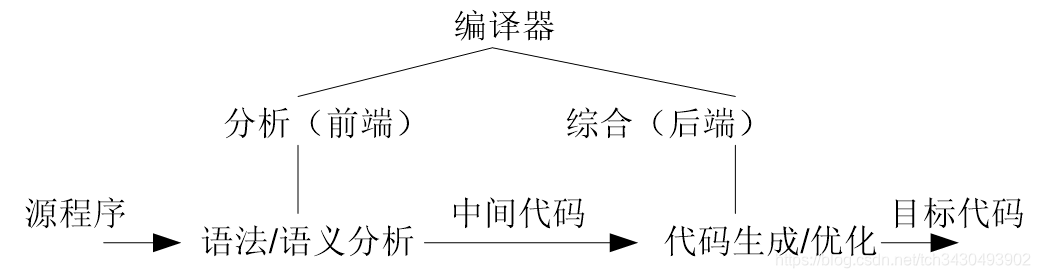
编译系统的组成部分

词法分析的主要任务
从左向右逐行扫描源程序的字符,识别出各个单词,确定单词的类型。将识别出的单词转换成统一的机内表示——词法单元(token)形式
token:<种别码,属性值>
| 单词类型 | 种类 | 种别码 | |
|---|---|---|---|
| 1 | 关键字 | program、if、else、then、… | 一词一码 |
| 2 | 标识符 | 变量名、数组名、记录名、过程名、… | 多词一码 |
| 3 | 常量 | 整型、浮点型、字符型、布尔型、… | 一型一码 |
| 4 | 运算符 | 算术(+ - * / ++ --) 关系( > < == != >= <=) 逻辑(& | ~) | 一词一码 或 一型一码 |
| 5 | 界限符 | ;() = {} … | 一词一码 |
模式、记号、单词
一个单词究竟是标识符、关键字,还是特殊符号,需要根据一定的构词规则来产生和识别。我们将产生和识别单词的规则称为模式,按照某个模式(规则)识别出的元素称为记号,而单词一词是指被识别的元素自身的值。
定义正规式、正规集以及有限自动机,并描述三者之间的关系。
正规式
正规式是一种表示正规集的工具,正规式是描述程序语言单词的表达式,对于字母表∑。
正规集
能用正规表达式表示的集合。
有限自动机
不确定的有限自动机(NFA):
一种数学模型
(1) 一个有限的状态集合S
(2) 一个输入符号集合∑(不包含ε)
(3) 一个转换函数move: S X (∑ U {ε}) -> P(S)
(4) 状态s0是唯一的开始状态
(5) 状态集合F是接受状态集合,S包含F
确定的有限自动机(DFA):
是NFA的特殊情况
(1) 任何状态都没有ε转换
(2) 对于任何状态s和任何输入符号a,最多只有一条标记为a的边离开,即转换函数move: S X ∑-> S可以是一个部分函数。
DFA算法和NFA算法的区别和联系
| NFA | DFA | |
|---|---|---|
| 初始状态 | 不唯一 | 唯一 |
| 弧上的标记 | 字(单字符字/ε) | 字符(串) |
| 转换关系 | 非确定 | 确定 |
对于每个NFA M都存在一个DFA M’ 使得 L(M) = L(M’)
从正规式到词法分析器的一般方法与步骤是什么?
1.用正规式对模式进行描述
2.为每个正规式构造一个NFA,它识别正规式所表示的正规集
3.将构造出的NFA转化为等价的DFA,这一过程也被称为确定化
4.优化DFA,使其状态数量最少,这一过程也被称为最小化
M’ 使得 L(M) = L(M’)
从正规式到词法分析器的一般方法与步骤是什么?
1.用正规式对模式进行描述
2.为每个正规式构造一个NFA,它识别正规式所表示的正规集
3.将构造出的NFA转化为等价的DFA,这一过程也被称为确定化
4.优化DFA,使其状态数量最少,这一过程也被称为最小化
5.根据优化后的DFA构造词法分析器


















 4111
4111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









