




 本文介绍如何使用TensorFlow实现线性拟合,通过构建神经网络模型预测数据。利用numpy生成模拟数据,并添加噪声使其更接近真实情况。通过定义隐藏层和输出层,采用ReLU激活函数和梯度下降优化器,最小化损失函数,实现数据预测。
本文介绍如何使用TensorFlow实现线性拟合,通过构建神经网络模型预测数据。利用numpy生成模拟数据,并添加噪声使其更接近真实情况。通过定义隐藏层和输出层,采用ReLU激活函数和梯度下降优化器,最小化损失函数,实现数据预测。
使用线性拟合数据
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
def add_layer(inputs,in_size,out_size,activation_fuction=None):
Weights = tf.Variable(tf.random_normal([in_size,out_size]))
biases = tf.Variable(tf.zeros([1,out_size]) +0.1)
Wx_plus_b = tf.matmul(inputs,Weights) + biases
if activation_fuction is None:
outputs = Wx_plus_b
else:
outputs = activation_fuction(Wx_plus_b)
return outputs
#区间[-1,1],300个维度,第一个逗号之前为行的范围(没有值说明,默认所有行)
# np.newaxis按列切分
x_data = np.linspace(-1,1,300)[:,np.newaxis]
#生成噪点,使数据更真实
#前俩个参数表示范围,后一个参数表示矩阵形状,normal表示正态分布
noise = np.random.normal(0,0.05,x_data.shape)
y_data = np.square(x_data) -0.5 + noise
xs = tf.placeholder(tf.float32,[None,1])
ys = tf.placeholder(tf.float32,[None,1])
#l1为隐藏层
l1 = add_layer(xs,1,10,activation_fuction=tf.nn.relu)
predition = add_layer(l1,10,1,activation_fuction=None)
#reducition_indices;通过加法缩小矩阵成一维,0:把列压缩成一条,1:把行压缩成一条
loss = tf.reduce_mean(tf.reduce_sum(tf.square(y_data
-predition),reduction_indices=[1]))
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
#创建图片框
fig = plt.figure()
#创建一个子图,前两个参数为长宽的比例,第三个参数为位置
ax = fig.add_subplot(1,1,1)
#数据以点的形式在图像上显示
ax.scatter(x_data,y_data)
plt.ion()#动态的生成图像python3.5之后
plt.show()
for i in range(1000):
#采用placehold去小批量的数据训练,而非全部
sess.run(train_step,feed_dict={xs:x_data,ys:y_data})
if i % 50 == 0:
#print(sess.run(loss,feed_dict={xs:x_data,ys:y_data }))
try:
ax.lines.remove(lines[0])
except Exception:
pass
predition_value = sess.run(predition,feed_dict={xs:x_data})
#绘制线,参数1:横轴数据(),参数2:纵轴数据(),r:表示红色,lw:线的宽度
lines = ax.plot(x_data,predition_value,'r',lw=5)
plt.pause(0.1)
plt.pause(0)
效果图
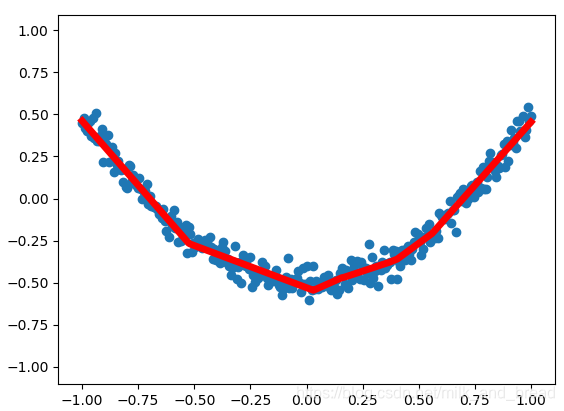
总结
-
输入输出定义:
- 数据量大的话,采用分批次,输入输出数据使用tf.placeholder定义(类似于占位符),并且还可以规定数据矩阵的形状
-
神经网络设置:
-
创建隐藏层函数:执行W * X + b,作为输入,采用激活函数,作为本层结果的输出
-
每一层结构相似,激活函数不同。
-
第一个隐藏层,激活函数使用Relu,结果输入到第二层,第二层不使用激活函数,得到结果predition
-
损失函数(评估实际与预测的差距):方差取平均
1n∑i=1n(y−predition)2 \frac{1}{n} \sum_{i=1}^n (y-predition)^2 n1i=1∑n(y−predition)2 -
优化器,梯度下降的方法,使损失函数最小,学习率为0.1
-
-
创建会话(运行前准备工作):
- 初始化所有定义的变量(必须):init = tf.initialize_all_variables()
- 创建会话 sess = tf.Session()
- 执行初始化sess.run(init)
-
训练的流程(运行)
- 创建一个for循环,执行训练sess.run(train_step,feed_dict={xs:x_data,ys:y_data})
- 查看计算图中的loss值仍然使用sess.run(loss,feed_dict={xs:x_data,ys:y_data }))
- 注意:必须放入同一个会话中。
- pycharm 中要想动态显示图像变化:
file->settings->tools->python Scientic->去除勾选项


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









