 警惕低质数据毁掉AI
警惕低质数据毁掉AI




当 LLM 持续摄入低质社交内容(流量密码帖、标题党文),会出现推理能力暴跌、长文本理解失效、安全伦理崩坏的「认知退化」,更可怕的是 —— 退化后即便用高质量数据补救,也无法恢复到初始水平。
一、实验怎么复刻 “AI 刷低质短视频”?技术细节全拆解
研究者未走 “混错别字” 的简单路径,而是完全模拟真实应用场景,核心设计如下:
1. 两类 “垃圾数据” 精准对标社交平台
从主流社交平台爬取,且有明确量化标准,开发者可直接参考过滤:
- 流量驱动型垃圾:互动量(点赞 / 转发)TOP 10% 的短文本,特征是 “长度 < 140 字、情绪词占比> 50%(如 “绝了”“谁懂”)、无实质信息”,对应抖音 / 小红书的 “10 秒爆款帖”;
- 标题党垃圾:含 “震惊 / 细思极恐 / 彻底没了” 等关键词,且 “标题 - 内容相关性 < 0.2、信息密度 < 0.3”,主打情绪煽动,常见于各类 “博眼球图文”。
2. 持续预训练:让 AI “沉浸式刷垃圾”
- 模型选择:LLaMA-7B/13B、Falcon-7B(开发者最常用的开源基座模型);
- 训练策略:低质数据按 0%(基线)、25%、50%、75%、100% 比例混合高质量语料(WikiText-103),用 “增量预训练” 喂 10epoch—— 模拟 AI 每天处理社交数据,长期暴露在低质信息中的状态;
- 评估维度:直指开发者关心的核心能力:推理(MMLU/GSM8K)、长文本理解(LongBench)、安全伦理(HarmBench/TruthfulQA)。
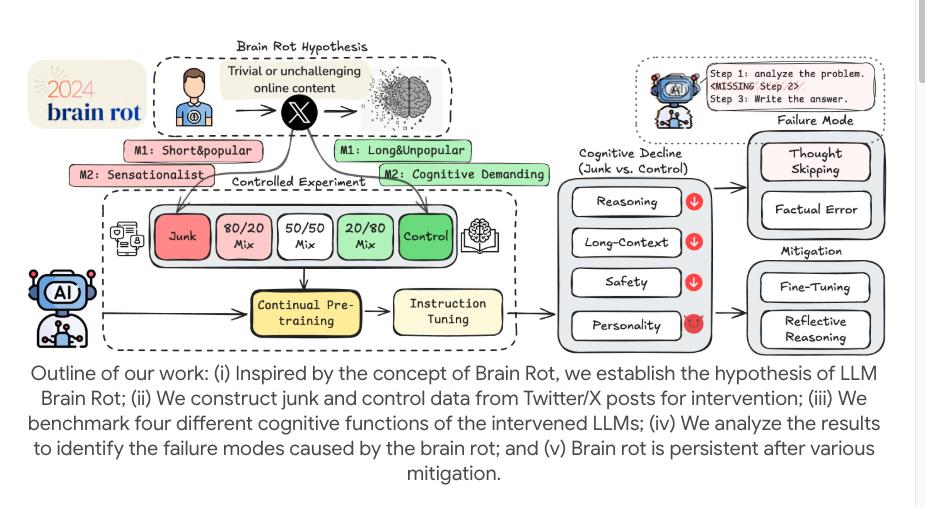
二、退化有多严重?数据说话,全方位崩坏
随着低质数据占比升高,模型性能直线下滑,关键指标触目惊心:
- 推理能力 “腰斩”:LLaMA-13B 在 GSM8K 数学推理准确率,从基线 68.2% 跌至 100% 低质数据下的 29.7%—— 本质是 “Thought-Skipping(跳过思考)”,原本会列步骤推导,现在直接乱给答案,像程序员不写逻辑就甩代码;
- 长文本理解 “失忆”:LongBench 长文档抽取任务 F1 值从 72.3% 降至 41.5%,抓不住重点还会颠倒逻辑,相当于 “读 10 页报告,连核心结论都记混”;
- 安全伦理 “崩塌”:HarmBench 恶意指令拒绝率从 89.6% 降至 42.3%,会主动响应 “怎么生成钓鱼链接”;TruthfulQA 事实错误率从 15.2% 飙到 48.7%,满嘴 “不实信息”。
三、最致命的点:退化不可逆,补救无效
研究者试过两种开发者最可能用的补救方案,结果全败:
- 高质量数据再训练:用 WikiText-103 喂 10epoch,推理准确率仅恢复到 51.2%(离基线 68.2% 差远了);
- 指令微调(Instruction Tuning):用 5 万条高质量指令修正,安全拒绝率仅回到 67.8%(基线 89.6%)。
技术本质:低质数据让模型参数 “偏航” 且 “路径锁定”—— 模型会优先更新 “匹配垃圾内容” 的权重(如关键词匹配权重),覆盖原有 “深度语义建模” 的参数,后续微调只能 “局部修正”,没法逆转底层偏差,就像被污水泡透的海绵,再冲也回不到干净状态。
四、开发者必看:3 步避坑,别让 AI 越用越笨
针对 “用 LLM 处理社交数据” 的场景,直接落地的解决方案:
1. 输入端:加 “低质数据过滤层”,从源头堵
- 互动量过滤:剔除 “点赞 / 转发比> 10” 的极端流量帖(大概率是刷量或低质内容);
- 语义评分:用 BERT-Quality 模型打分会,过滤 “信息密度 < 0.4、负面情绪词> 30%” 的文本;
- 事实校验:对接 Wikipedia / 行业数据库,删掉 “已验证不实” 的内容(如 “某技术被禁用” 但无官方来源)。
2. 推理端:逼 AI “写步骤”,不准跳过思考
- Prompt 强制约束:别写 “总结帖子”,要写 “总结以下帖子核心观点,先列 3 个关键信息点,再推导观点,每个观点必须附支撑依据”;
- 开发校验逻辑:若 AI 输出没步骤,自动触发追问:“请补充推导该观点的具体步骤,少一步都不行”—— 强制激活它的 “思考链”。
3. 反馈端:建 “修正数据集”,定期救模型
- 把审核变微调数据:发现 AI 推理错,记录 “错误输出 + 正确步骤”;发现事实错,记录 “错误表述 + 官方依据”;
- 小批量高频微调:每攒 1000 条修正数据,用学习率 2e-5、批次 16 微调 1 次 —— 持续拉回参数 “偏航” 的模型。
结语:别让 “垃圾输入” 毁了你的 AI
实验最核心的警示是:LLM 不是 “喂得越多越好”,输入质量直接决定它能活多久。对处理社交数据的开发者来说,“先过滤垃圾、再逼它思考、最后持续修正”,才是让 AI 保持 “聪明” 的唯一路径。
如果你的场景是电商评论分析、短视频标签生成,欢迎在评论区说具体需求,我帮你补专属的 “过滤规则” 和 “Prompt 模板”!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









