




https://www.freecodecamp.org/news/an-introduction-to-deep-q-learning-lets-play-doom-54d02d8017d8/
上一章,我们学习了Q-Learning:一种RL算法,它会构建一个Q-table,然后agent在给定state的情况下使用Q-table来找到最优动作。
但是我们会发现,如果我们有一个巨大的state空间环境,生成和更新Q-table会变得非常低效。
本文,我们创建深度Q神经网络。不使用Q-table,我们用神经网络来处理state,然后输出基于该state的每个action的Q-values。
本文要学习的是:
- 什么是Deep Q-Learning(DQL)?
- DQL的最优策略是什么?
- 如何处理temporal limitation problem?
- 为什么要使用experience replay?
- DQL背后的数学原理是什么?
Adding ‘Deep’ to Q-Learning
本文我们来学习玩Doom这款游戏。Doom是一个有着巨大state空间的big env(百万级的states)。对于这个环境创建和更新一个Q-table就会非常低效了。
对于这个case,最好的想法就是创建一个神经网络来逼近,对于给定state的每个action的Q-values。
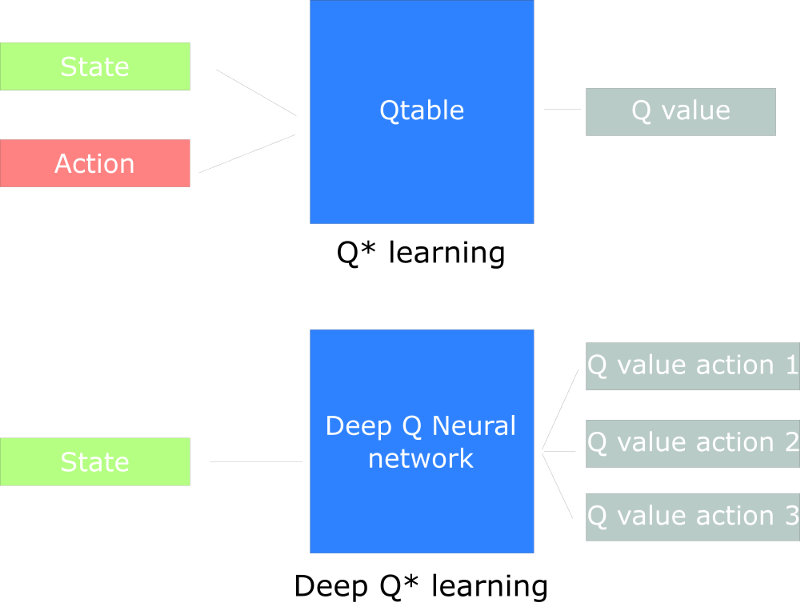
How does Deep Q-Learning work?
这就是我们DQL的结构:

这看起来似乎比较复杂,但是我们会一步步的解释。
我们的DQL网络将堆叠的4帧图像作为输入,通过网络前传输出一个Q-values的向量,该向量表示该state下每个可能action的Q-value。然后我们选择最大的Q-value来作为我们的最优动作。
算法刚开始的阶段,agent做的很糟。但是随着时间退役,它就开始根据states来选择最优的动作。
Preprocessing part

预处理是很重要的一步。我们想要减少states的复杂性进而减少训练所需要的计算时间。
首先对state进行灰度。颜色在这个case并不是重要的信息(我们只需要找到敌人并杀死他就可以了,不需要用颜色去找到他)。这是一个很重要的节省,因为我们减少了两个channel。
然后我们再对每一帧进行裁剪。因为本例中,图像的外围是没有用的。
然后我们对frame进行resize,将4个处理过后的帧堆叠起来。
The problem of temporal limitation
关于为什么我们要使用多帧图像堆叠,这是因为如果仅仅使用单帧图像,我们没有办法感知运动信息,也就无法做出正确的决策。
当然有更好的办法来解决时间限制的问题,也就是使用LSTM网络,但是对于初学者,堆叠多帧更好理解一点。
Using convolution networks
CNN网络所使用到的卷积操作和网络结构能够很好的相对快速的提取图像特征。CNN是目前处理图像数据最好的网络。具体细节请参考其他资料。
Experience Replay: making more efficient use of observed experience
Experience replay 帮助我们处理两件事:
- 避免忘记之前的经验。
- 减少经验间的相关性。
Avoid forgetting previous experiences
存在一个问题,由于actions和states具有很强的相关性,我们网络的权重具有易变性。
在第一章我们提到了强化学习的过程:

每个时间步,我们会收到一个tuple(state,action,reward,new_state)。我们从中学习,然后将这个experience扔掉。
我们的问题是,在于env的交互中,我们将得到的样本序列输入进神经网络,神经网络会倾向于忘记之前的经历,我们的权重会被新的经历改写。
比如,如下图,如果我们先在一个场景学习,然后再到下一个场景学习,这时agent就会忘记如何在第一个场景运动。

因此,有效的方法就是通过学习多次来充分使用之前的经历。
我们的解决方法就是:创建一个“replay buffer”。它存储与env交互的 experience tuples,然后我们采样一个小的batch输入到网络中。
可以将replay buffer视作一个文件夹,里面每个文件都是一个experience tuple。这些都是跟env交互得到的。然后你随机采样一些输入到神经网络中。

这就防止网络只学习最近完成的交互经验。
Reducing correlation between experiences
还有另一个问题——我们知道每个action都会影响到下一个state。这就使得输出的一系列experience tuples具有很强的相关性。
如果我们按序列顺序训练网络,我们的agent会受到这种强相关性的影响。
从replay buffer里随机采样,就会破坏这个相关性。这就防止action value灾难性的振荡或者不收敛。
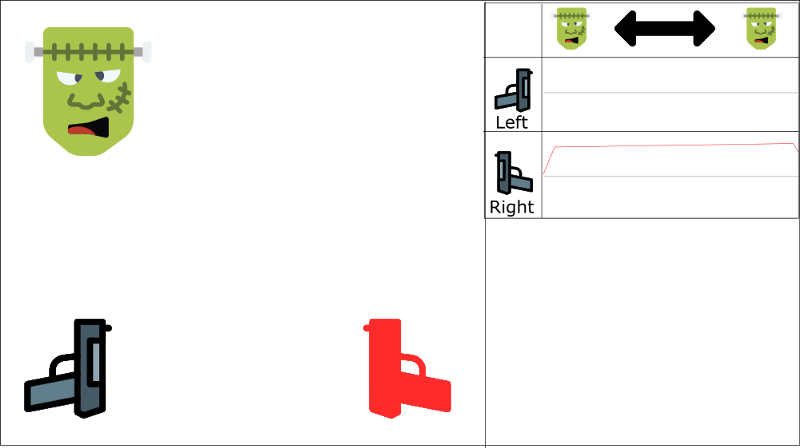
下面我们用一个例子来简单理解一下。现在我们在玩一个第一人称射击,怪物要么出现在左边,要么在右边。我们agent的目标就是射中怪物。我们有两把枪和两个动作:射击左边和射击右边。
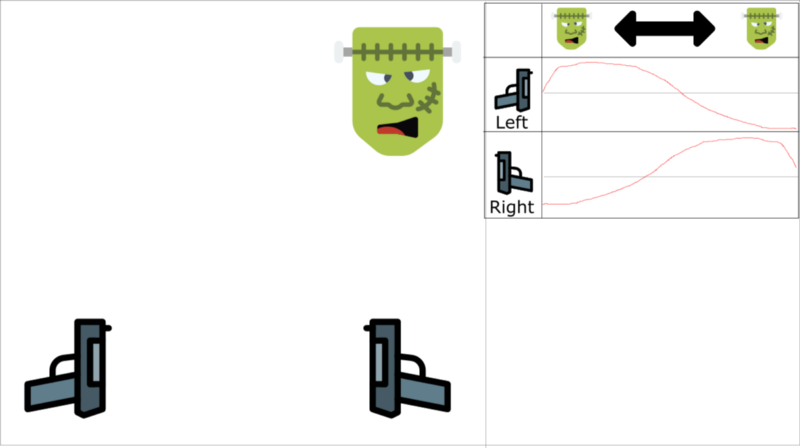
上图曲线代表Q-values的逼近。
我们按顺序来进行学习。现在我们知道如果我们射击一个怪物,下一个怪物来自同一方向的可能性是70%。这就是我们experiences tuples的相关性。
现在开始训练,我们的agent看到怪物在右边,射击右边,对了!!
然后下一个怪物还是来自右边(70%的可能性),agent射击右边,又对了!!
然后如此反复…
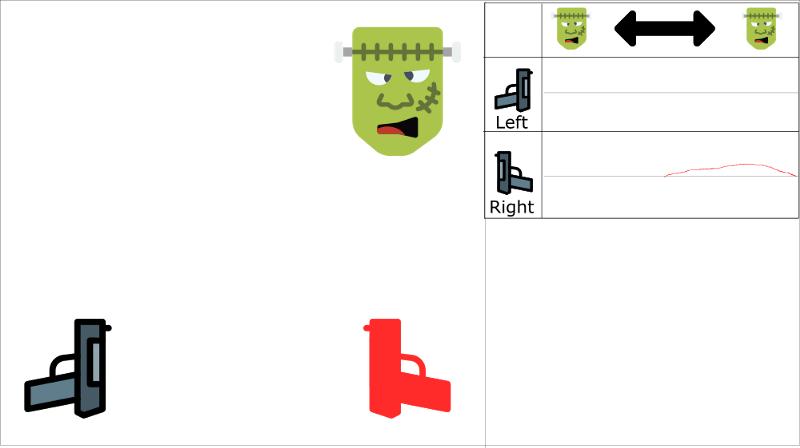
问题是,该方法会带来射击右边这个action在这个state空间上值的增加。如下图,Q-value在怪物在左边的时候,射击右边的值也是正值,这是不合理的。
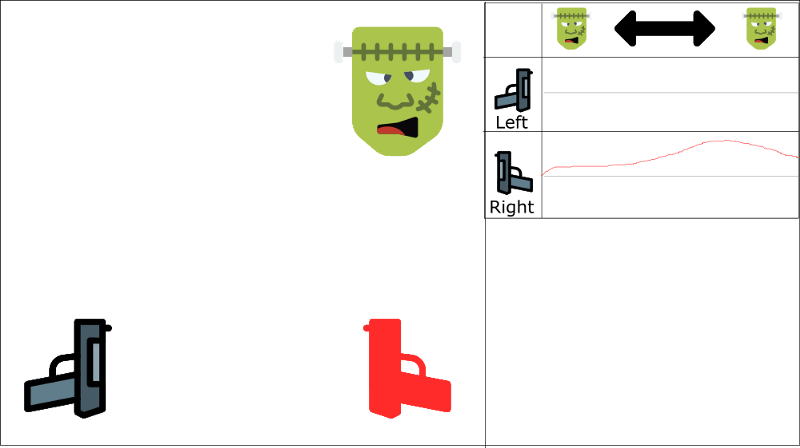
而且如果我们没有看到足够多的左例子(因为只有30%来自左边),我们的agent可能学会只选择射击右边不论怪物在哪儿,这也不合理。
我们有两个并行策略来处理这个问题。
第一,跟env交互的时候,我们要停止训练。我们应该尝试不同的动作,并且进行少量随机的探索。然后将这些experiences存入replay buffer。
然后我们使用buffer里的experiences进行学习。在这之后,我们使用新的价值函数来与env交互。
因此,我们会有一个更好的样本集。我们能够使用任意顺序来调取这些样本来从这些样本中泛化模式。
这就帮助我们避免被禁锢在state空间里的一个固定区域,防止我们反复强化同一个action。
这个方法可以被看做是一种监督学习。
后面的文章我们会使用“prioritized experience replay”。这会让网络更多的去学习那些数量少的,“重要的”的样本。
Our Deep Q-Learning algorithm
上一章,我们提到了bellman equation。
New
Q
(
s
,
a
)
=
Q
(
s
,
a
)
+
α
[
R
(
s
,
a
)
+
γ
max
Q
′
(
s
′
,
a
′
)
−
Q
(
s
,
a
)
]
\text{New }Q(s,a)=Q(s,a)+\alpha[R(s,a)+\gamma \max Q'(s',a')-Q(s,a)]
New Q(s,a)=Q(s,a)+α[R(s,a)+γmaxQ′(s′,a′)−Q(s,a)]
在这个例子中,我们想要更新网络权重来减小error。
这个error(或者TD error)是通过计算Q-target(下一个state的最大可能value)和Q-value(我们当前Q-value的预测)的差来表示。
Δ
w
=
α
[
(
R
+
γ
m
a
x
a
Q
^
(
s
′
,
a
,
w
)
)
−
Q
^
(
s
,
a
,
w
)
]
∇
w
Q
^
(
s
,
a
,
w
)
\Delta w=\alpha [(R+\gamma max_a \hat Q(s',a,w))-\hat Q(s,a,w)]\nabla_w \hat Q(s,a,w)
Δw=α[(R+γmaxaQ^(s′,a,w))−Q^(s,a,w)]∇wQ^(s,a,w)
Initialize Doom Environment E
Initialize replay Memory M with capacity N (= finite capacity)
Initialize the DQN weights w
for episode in max_episode:
s = Environment state
for steps in max_steps:
Choose action a from state s using epsilon greedy.
Take action a, get r (reward) and s' (next state)
Store experience tuple <s, a, r, s'> in M
s = s' (state = new_state)
Get random minibatch of exp tuples from M
Set Q_target = reward(s,a) + γmaxQ(s')
Update w = α(Q_target - Q_value) * ∇w Q_value
在这个算法中有两个流程:
- 我们跟env进行交互,将experiences存入replay memory,然后对env进行采样。
- 随机选择一个小的batch,然后使用sgd进行更新。

















 2756
2756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









