



 文章介绍了如何使用木头浏览器进行数据采集,将图文信息保存在一个HTML文件中。通过抓取网页内容,转化图片为Base64编码嵌入HTML,实现了图文的本地存储和方便查看。
文章介绍了如何使用木头浏览器进行数据采集,将图文信息保存在一个HTML文件中。通过抓取网页内容,转化图片为Base64编码嵌入HTML,实现了图文的本地存储和方便查看。
文字中夹着图片,图片也需要文字说明,文字和图片相辅相成,就有了绚丽多彩的网页内容。但是图文混排的方式却给我们存储数据带来不便,实际上大多数网页是把文字和图片分别存放在不同文件中的,在html源码中只保存图片的链接地址。
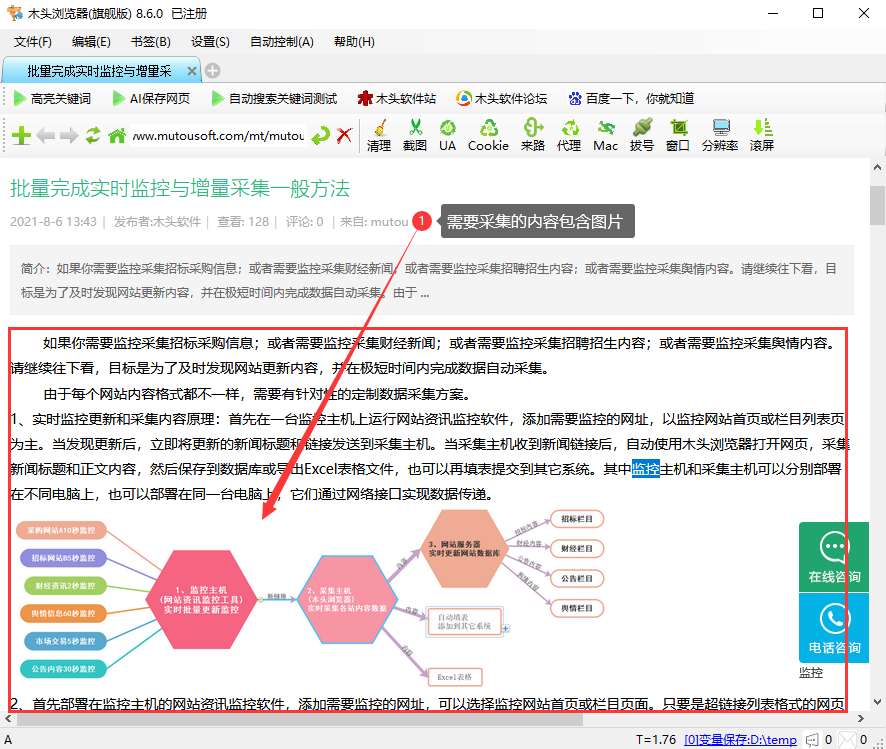
如上图所示,在做数据采集时,很多朋友把文字和图片分别下载保存,还要处理链接本地化转换的问题。实际上我们也可以把图片文件转码后保存在html源码文件里,这样用一个html文件就可以保存图文信息了,自动采集图文步骤如下。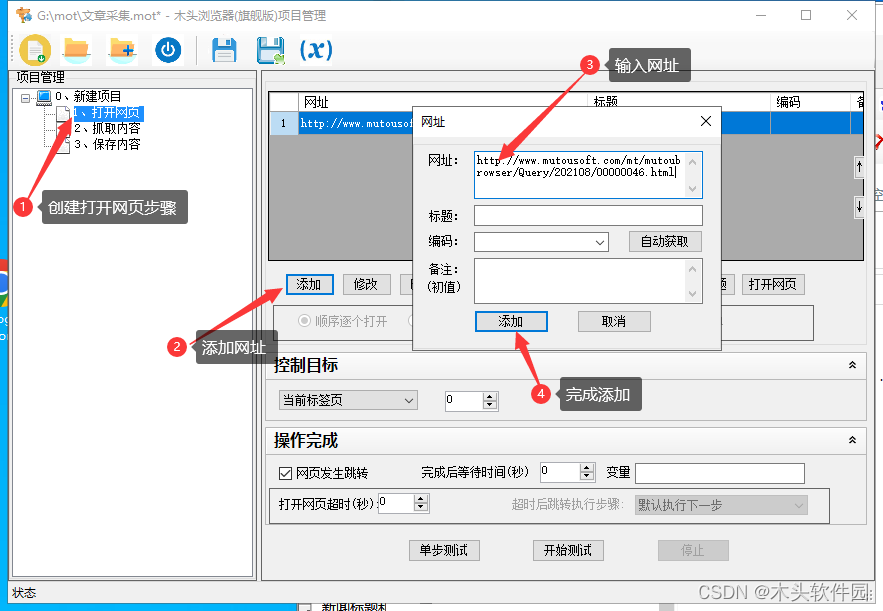
打开木头浏览器项目管理窗口,创建【打开网页】步骤,添加需要采集的页面网址,如果添加多个网址,则可以按顺序打开采集内容。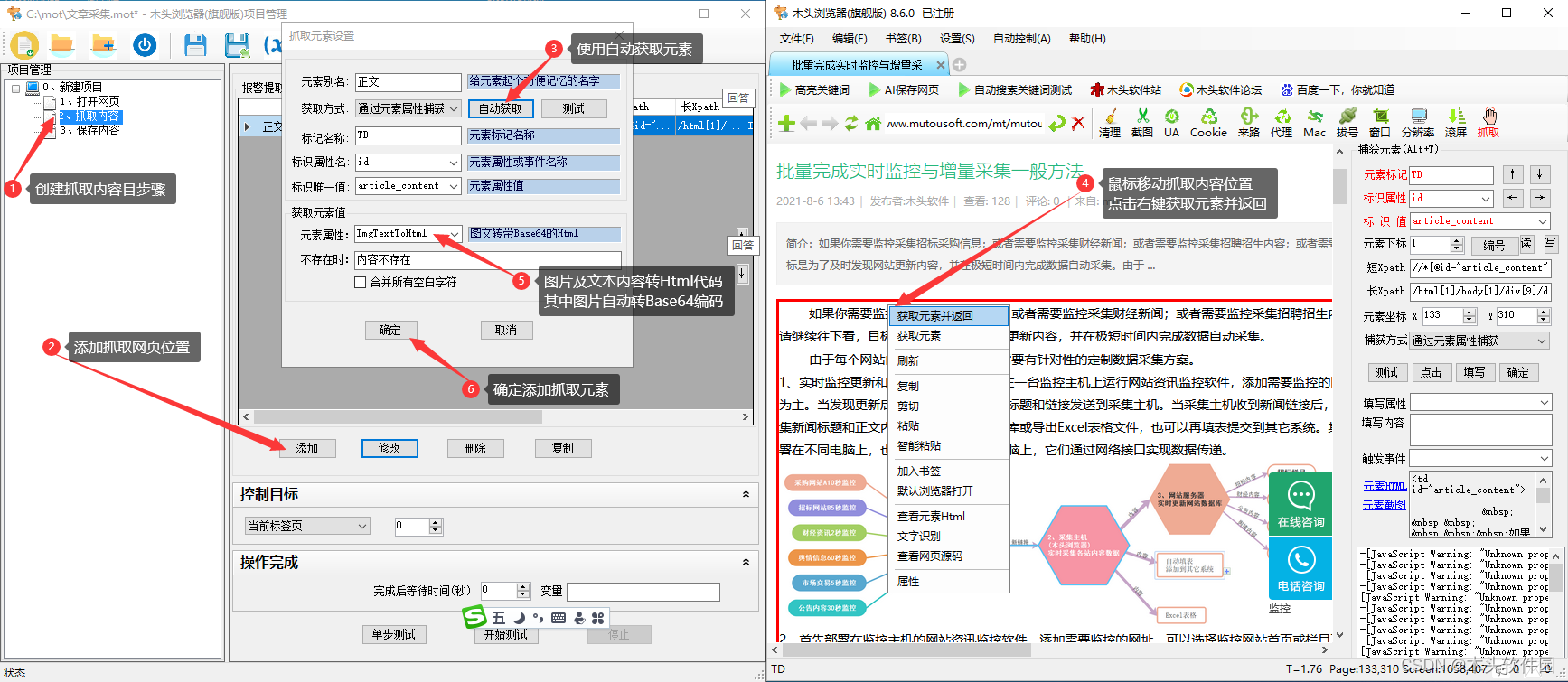
然后添加最关键的步骤【抓取内容】,【添加】抓取内容,在弹出的【抓取元素设置】窗口,点击【自动获取】按钮,浏览器将处于元素定位模式,鼠标移到需要抓取的元素内容上方点击右键,在弹出的快捷菜单中选择【获取元素并返回】,成功获取可唯一标识该元素的方法,如下图所示,此以页面使用元素的ID属性定位等抓取的元素区域,设置获取元素的【TagTextToHtml】扩展属性,意思是把元素内容转化为Html代码。如有必要,可以使用同样的方法继续添加抓取页面文章标题,此处不在累述。
抓取元素转换成html后,就是保存数据了,创建【保存数据】步骤,勾选【保存变量文件】,选择Htm文件格式,设置文件保存路径。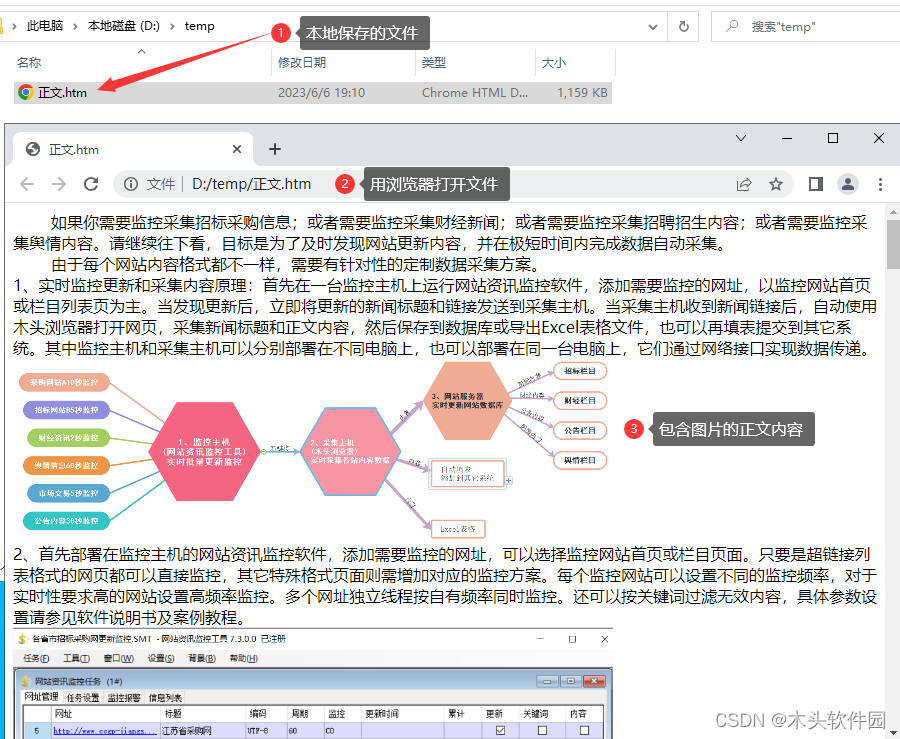
最后,点击【开始测试】按钮运行项目,当项目执行完毕后,打开设定的保存文件目录,就可以看到自动保存和htm文件,且只有这个文件,双击自动调用浏览器打开,完整呈现图文内容。图片已经转成了Base64编码,嵌入保存在htm文件中。

















 704
704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









