



如果要采集文章中的图片,要怎么设置呢?
图片在网页页面里是img标签(HTML代码),所以要想采集到图片,就要在网页数据抓取工具中设置保留HTML标签,否则只能采集到文本。
具体操作我们举例子来说明:
目录
1. 错误例子
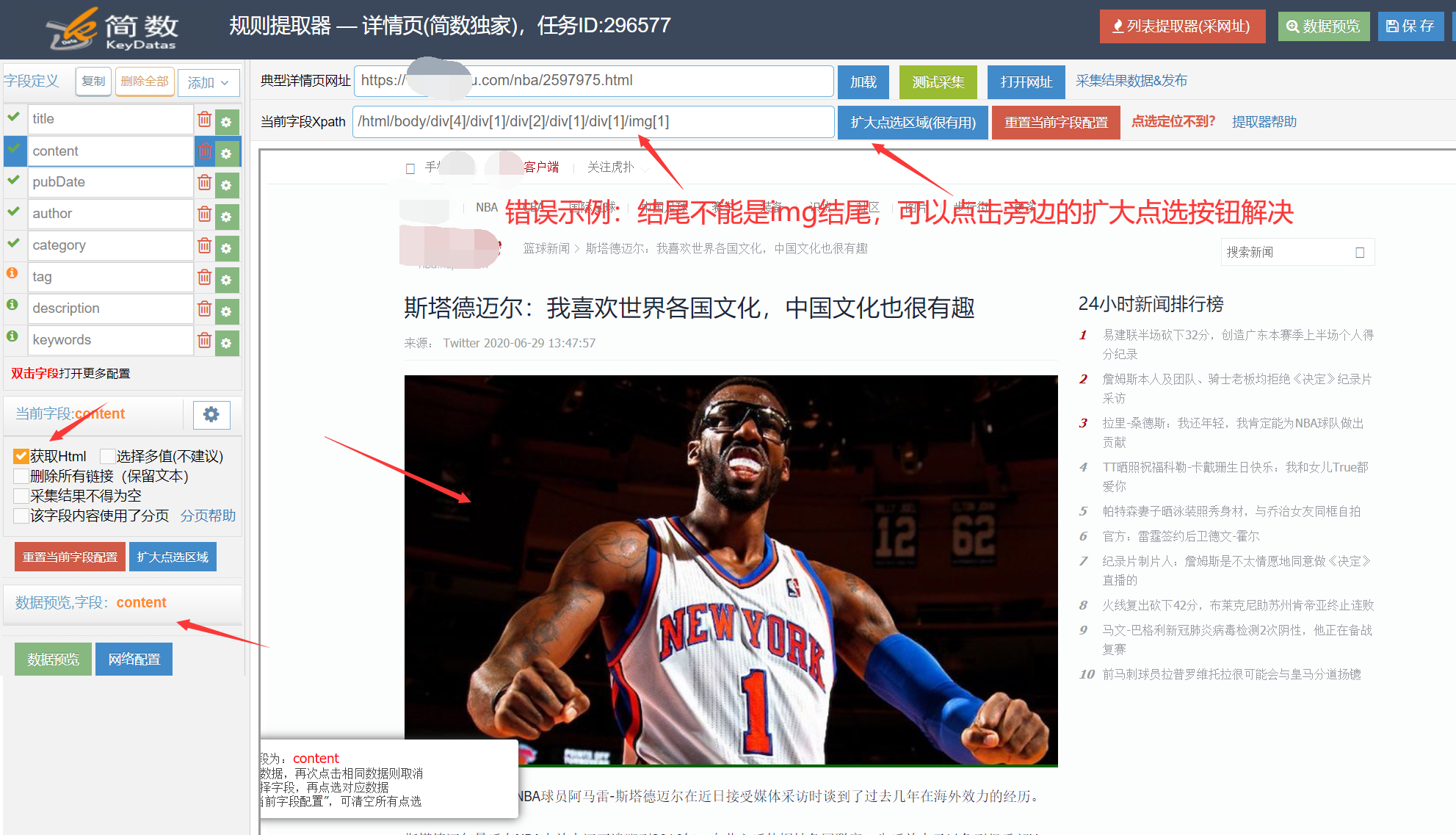
下图例子中是在简数采集器中设置了获取html(左侧下方),但是选择采集区域时点选到了图片本身(即img标签)。
此时Xpath路径栏是img结尾,表示获取img标签里面的内容,但是img标签里面是没有内容的,它本身就是代表图片的代码,这种情况是无法采集到图片的。
2. 正确例子
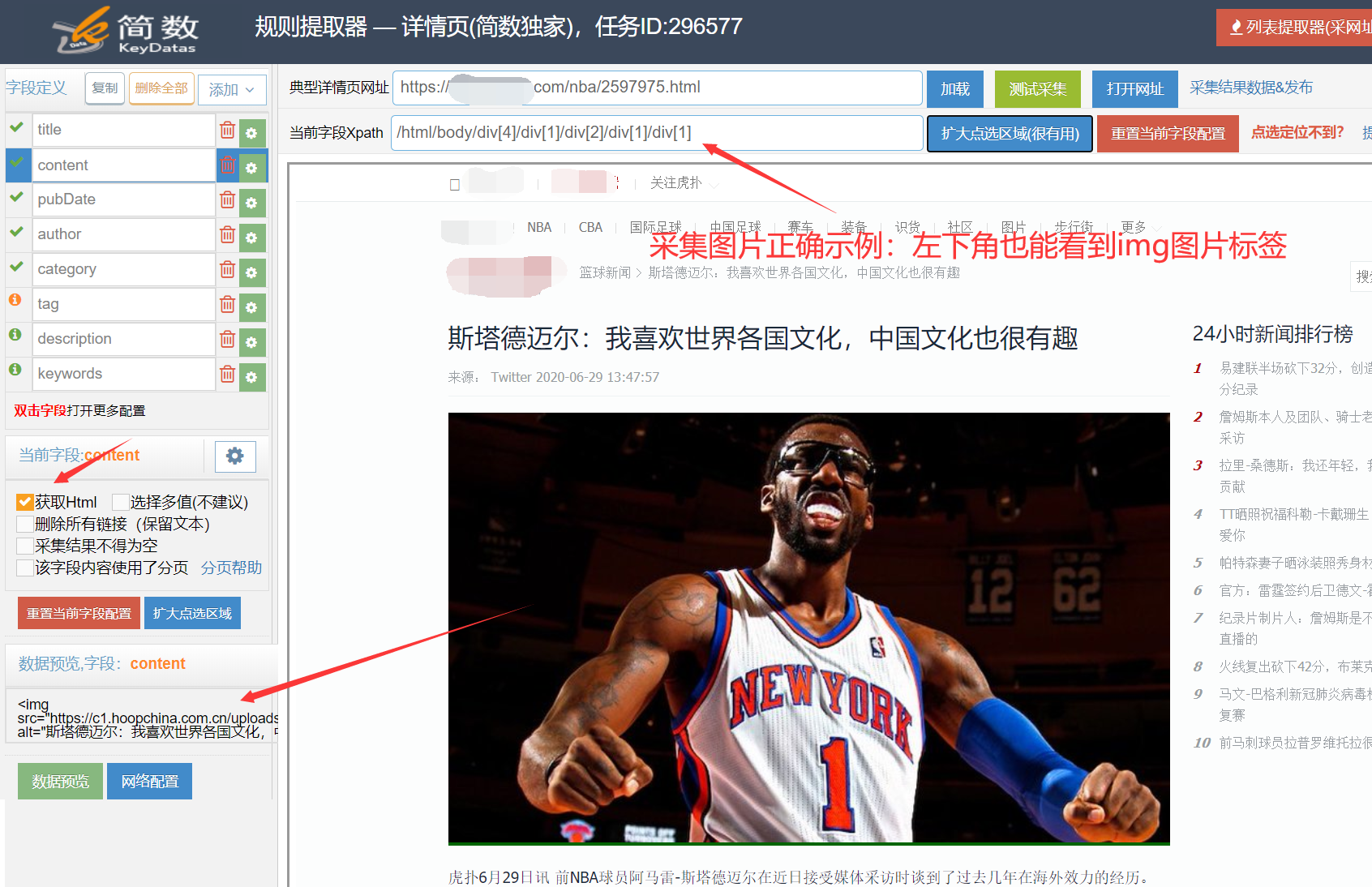
正确获取到图片的方式应该是获取img标签的上一层标签(或者更上几层的标签也行),只要这个标签里面包含了img标签,这样就能采集到图片了。
我们可以使用【扩大点选区域】按钮技巧来解决这个问题,图片获取正确时详情提取器左下方预览是可以看到img标签的,Xpath路径栏不是img结尾。
3. 只采集含有图片的数据
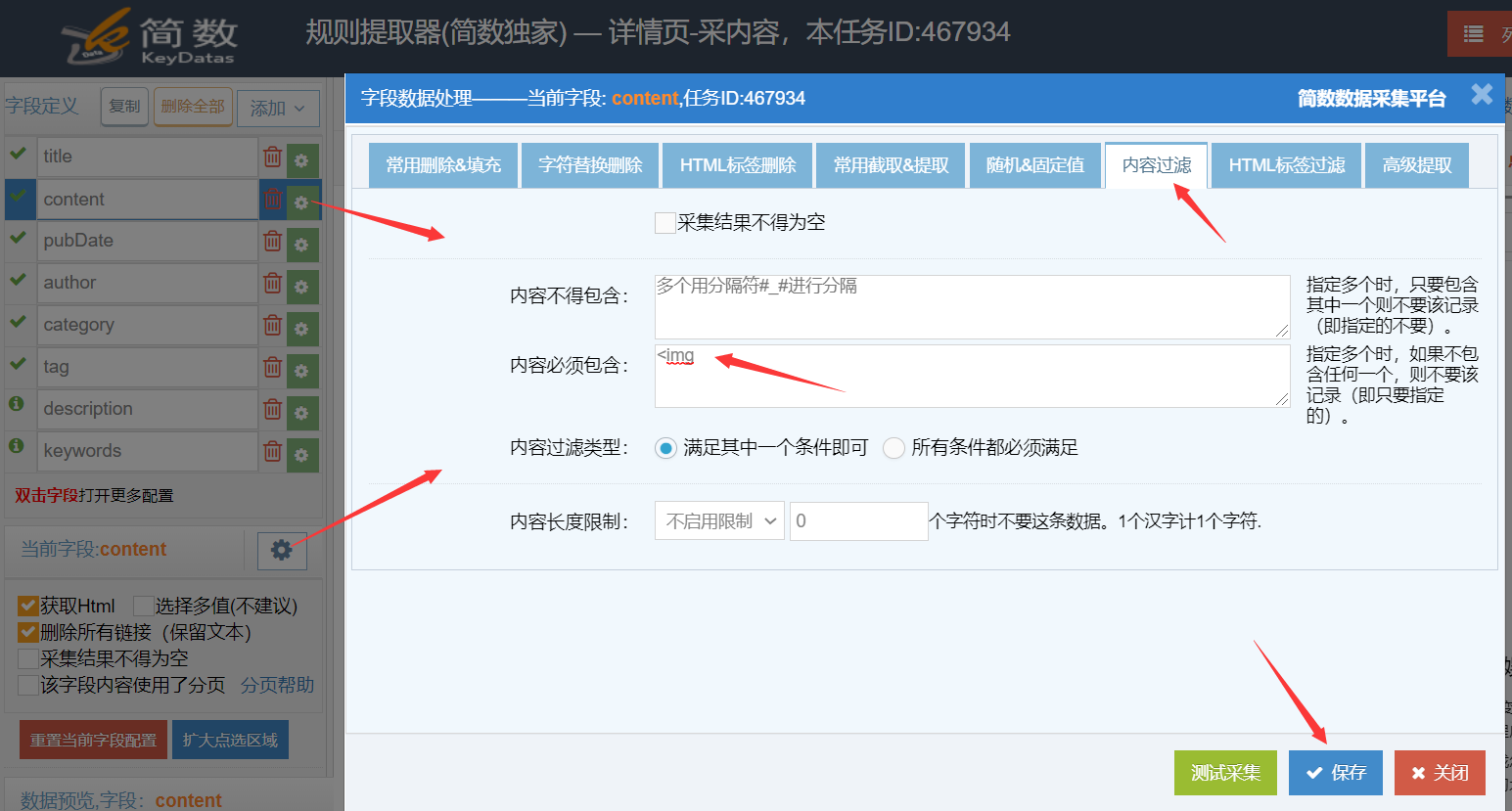
简数还可以设置只采集有图片的文章,没有图片的数据就不采集。
设置方法也很简单,进入【内容过滤】设置--》在【内容必须包含】处填写<img,最后保存。

















 1399
1399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









