




 这篇博客介绍了如何使用AI技术智能保存网页,仅保留标题和正文,同时去除无效内容和广告。通过JS代码实现网页标题的智能识别,从H1元素或特定样式的元素中提取标题。正文识别则从P元素出发,找到包含大量P元素的父元素,或者选取页面中间大面积元素。保存时,将图片转为Base64编码内嵌于单个htm文件中,便于存储和浏览。
这篇博客介绍了如何使用AI技术智能保存网页,仅保留标题和正文,同时去除无效内容和广告。通过JS代码实现网页标题的智能识别,从H1元素或特定样式的元素中提取标题。正文识别则从P元素出发,找到包含大量P元素的父元素,或者选取页面中间大面积元素。保存时,将图片转为Base64编码内嵌于单个htm文件中,便于存储和浏览。
网页可以非常方便的为我们展示各种信息,如果遇到重要的资料文献,希望在本地电脑上保存下来该怎么操作呢?把网址添加到收藏夹,下次直接打开网址查看,但如果资源被网站删除,就再也找不到了。还是保存在自己电脑里比较放心,那就使用浏览器的保存网页吧,如果保存为单个文件,则只有文字内容,图片丢失了。如果保存所有内容,将产生一个网页文件和一个资源文件夹,包括图片在内的文件都保存在这个文件夹中,由于文件较多不容易归类保存和传输。使用保存网页的方式,除正文外,还会保存网页标题导航栏、信息侧边栏、底部联系信息等无用的内容。
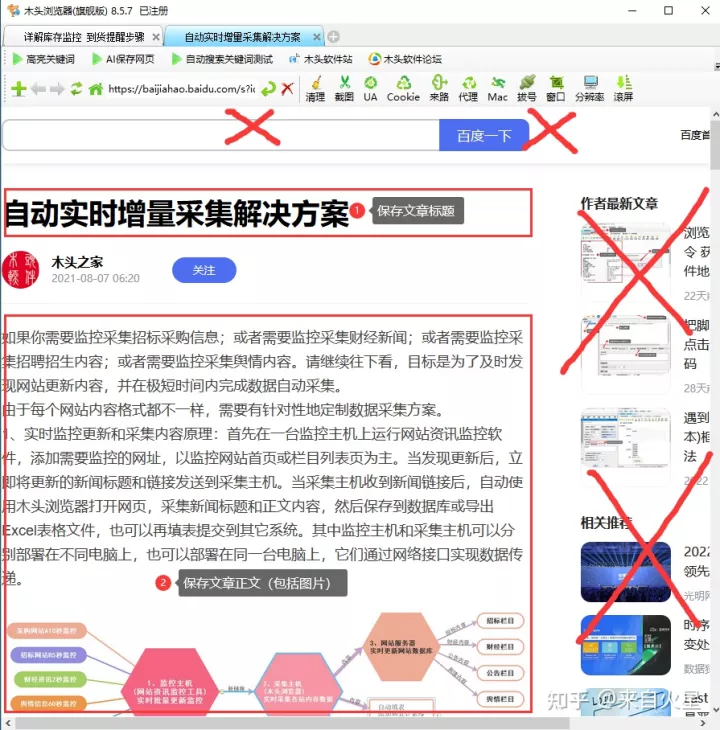
需要保存的网页标题和正文
有没有一种方法,保存网页时,自动智能识别内容标题和正文,且仅保存标题和包括图片在内的正文内容,自动删除网页无效的头尾和侧边内容,更要过滤网页上的广告。这就是“AI保存网页“,如下图所示,打开任意新闻、公告或文章页面,再点击”AI保存网页“,就可以一键保存网页标题和正文。
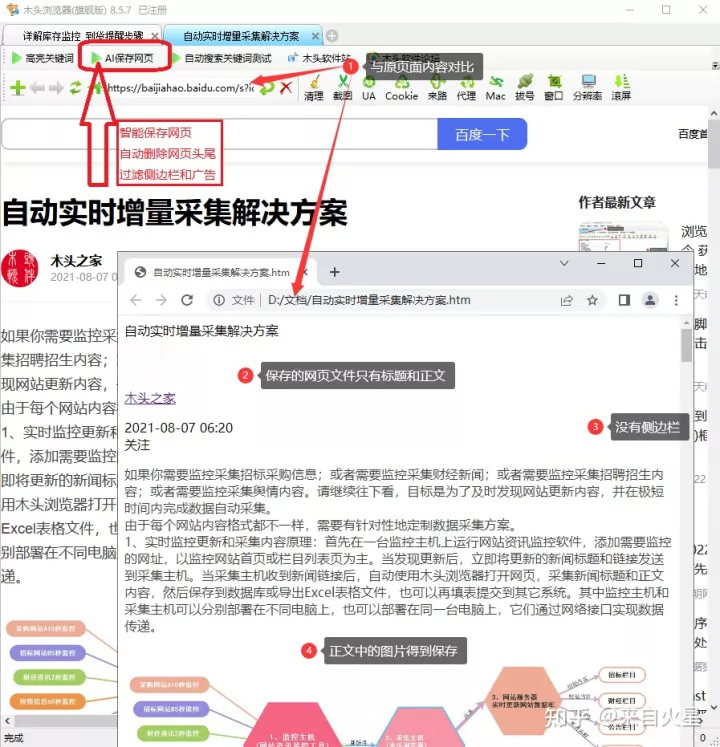
网页保存后与原页面对比
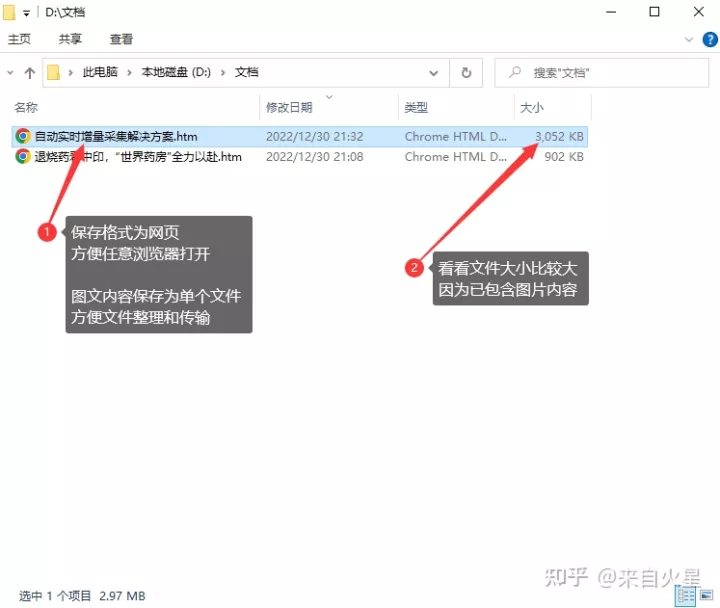
找到文档保存路径,可以看到以文章标题命名的网页文件。这个文档比较大,是因为同时保存和正文中的图片,也就是说把文字和图片都保存在单个文档中的。且为htm网页格式,可以使用任意浏览器打开。把图片保存在htm网页代码中,是什么原理呢?原来木头浏览器在保存网页时,自动把网页上的图片转换成Base64编码,这样就可以在单个文件中保存图片了。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1756
1756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









