







 Hive是一个基于Hadoop的数据仓库工具,通过SQL简化MapReduce编程。它允许用户将结构化数据文件映射到数据库表并进行SQL操作。Hive处理流程涉及SQL到MapReduce的转化,其元数据存储在数据库中,如MySQL或Derby。虽然Hive提供了便利,但可能降低执行效率。Hive接口包括CLI、Client和WebUI,元数据包括表信息、数据存储位置等。
Hive是一个基于Hadoop的数据仓库工具,通过SQL简化MapReduce编程。它允许用户将结构化数据文件映射到数据库表并进行SQL操作。Hive处理流程涉及SQL到MapReduce的转化,其元数据存储在数据库中,如MySQL或Derby。虽然Hive提供了便利,但可能降低执行效率。Hive接口包括CLI、Client和WebUI,元数据包括表信息、数据存储位置等。
“懒人推动世界发展”
IT行业能发展到如今的地步,可以说都是有这么一句话做支撑,哈哈,懒人的潜力是无限的。
回顾MapReduce开发应用程序时, 需要写大量的代码. 然后就有人不想写这复杂的代码, Hive就被开发出来了. 通过编写SQL语句让Hive自动解析SQL, 然后经过一系列操作之后转换成MapReduce应用, 从而实现需求. 也就是说, Hive的出现目的就是把复杂的MapReduce代码转化为简单的SQL语句.
其实Hive只是一个工具, 一个用来构建数据仓库的工具. Hive底层还是基于HDFS和MapReduce来实现功能的.
Hive官网:http://hive.apache.org/index.html
Hive的定义
官网的定义: The Apache Hive data warehouse software facilitates reading,
writing, and managing large datasets residing in distributed storage
using SQL. Structure can be projected onto data already in storage. A
command line tool and JDBC driver are provided to connect users to
Hive.
翻译过来大意是: Apache Hive数据仓库通过使用SQL来读取,编写和管理存放在分布式存储中的大型数据集。
可以将结构映射到已存储的数据中。 并提供命令行工具和JDBC驱动程序来让用户连接到Hive。
我的理解:Hive是基于Hadoop的一种构建数据仓库的工具,可以将结构化的数据文件映射或者说加载到数据库中已存在的表中,然后就可以通过我们熟悉的sql语句进行对数据一系列的操作。
之后可以将SQL语句转化为MapReduce任务,快速实现简单的MapReduce计算,不必再去开发复杂的MapReduce应用。
那么这样的结构化数据文件一般从hdfs中获取到的,所以Hive底层是依赖hdfs的,想要使用Hive必须启动hdfs。
Hive处理流程
select * from table;
举个例子,就那以上的句sql语句来举例讲解Hive的处理流程。
本人能力有限,外加认知目前比较粗浅,流程图只能画成这样…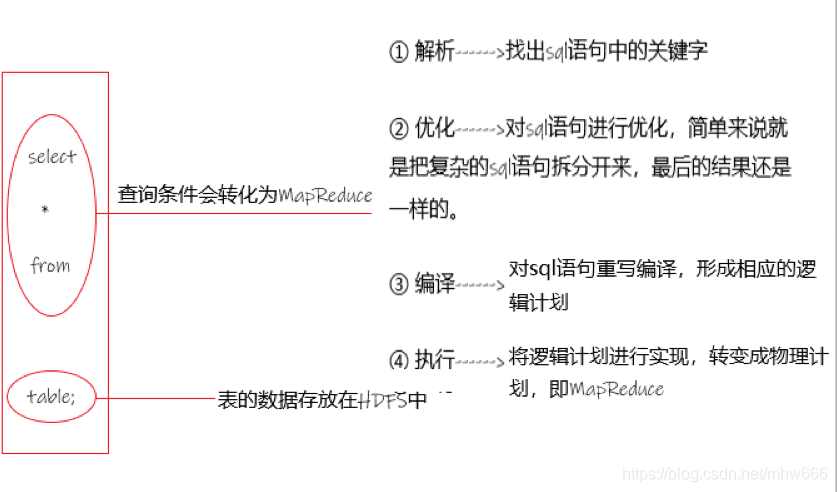
通过本人上图的粗浅介绍,但也还算清晰。
如图,Hive是通过提交sql语句,拆分为计算部分和存储部分,最终计算部分转换为MapReduce,存储部分转换为HDFS。
所以Hive最终还是由MapReduce来处理HDFS中的数据,只不过这些数据得是结构化的表数据。那么受益者当然是进行开发的程序员了,哈哈,Hive为程序员提供了方便,可以灵活的开发。
但是也有缺点,那就是执行效率降低了,多走了Hive解析,优化,编译和执行sql语句的步骤。
不过也正常,万事都是有利有弊嘛。
Hive结构
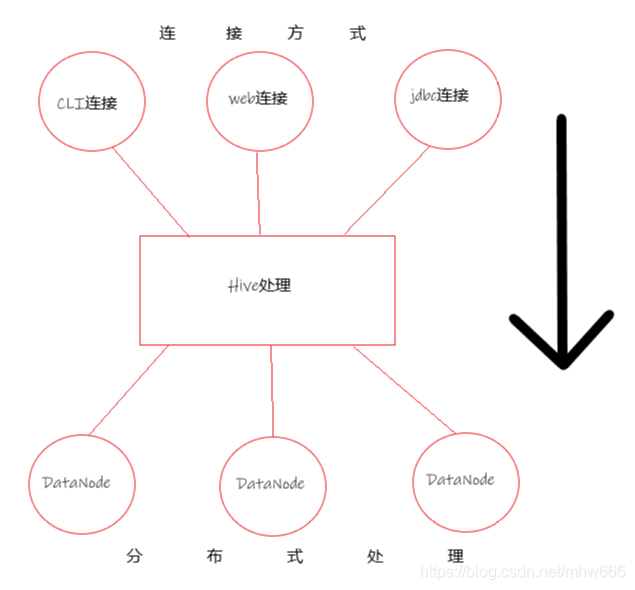
Hive的用户接口主要有三个: CLI, Client 和 WebUI. 其中最常用的是CLI, CLI启动的时候, 会同时启动一个Hive副本; Client是Hive的客户端, 用户通过连接Hive Server (Thrift Server)连接至Hive, 在启动Client模式时, 需要指出Hive Server所在节点,并且在该节点启动Hive Server; WUI是通过浏览器访问Hive.
Hive将元数据存储在数据库中, 如mysql、derby. Hive中的元数据包括表的名字, 表的列和分区及其属性, 表的属性(是否为外部表等), 表的数据所在目录等.
解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成. 生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
Hive的数据存储在HDFS中, 大部分的查询、计算由MapReduce完成(包含*的查询,比如select * from tbl不会生成MapRedcue任务)。
Hive的元数据存放位置
三种搭建方式:
① derby Hive内部的数据库,但不能多用户同时访问
② 本地
③ 存放在外部数据库(比较安全)

















 542
542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









