




线程池
为什么用线程池 / 线程池的好处
关键词:池化技术
好处:
- 降低资源消耗:重复利用已创建线程,避免创建销毁的消耗
- 提高响应速度:不用等待线程创建,就可以执行任务
- 提高线程的可管理性:线程不能无限制创建
线程池创建方法
1、通过ThreadPoolExecutor构造函数来创建(推荐)
常见参数如下:
/**
* 用给定的初始参数创建一个新的ThreadPoolExecutor。
*/
public ThreadPoolExecutor(int corePoolSize,//线程池的核心线程数量
int maximumPoolSize,//线程池的最大线程数
long keepAliveTime,//当线程数大于核心线程数时,多余的空闲线程存活的最长时间
TimeUnit unit,//时间单位
BlockingQueue<Runnable> workQueue,//任务队列,用来储存等待执行任务的队列
ThreadFactory threadFactory,//线程工厂,用来创建线程,一般默认即可
RejectedExecutionHandler handler//拒绝策略,当提交的任务过多而不能及时处理时,我们可以定制策略来处理任务
) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
corePoolSize:任务队列未达到队列容量,最大可以同时运行的线程数量。一般不会被回收,allowCoreThreadTimeOut(boolean value),设为 true 就会在keepAliveTime之后被回收maximumPoolSize:任务队列中存放的任务达到队列容量时,可以同时运行的线程数量workQueue:新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中keepAliveTime:存在非核心线程时,这些线程在空闲后等待超过该时间才会被回收销毁unit:keepAliveTime参数时间单位threadFactory:executor 创建新线程的时候会用到handler:拒绝策略
拒绝策略
当线程已经达到最大线程数,并且队列也已经放满了任务时:
ThreadPoolExecutor.AbortPolicy(默认):抛出异常来拒绝新任务ThreadPoolExecutor.DiscardPolicy:不处理新任务直接丢弃ThreadPoolExecutor.DiscardOldestPolicy:丢弃最早未处理的任务请求ThreadPoolExecutor.CallerRunsPolicy(不丢弃任务的选择):直接在调用execute方法的线程中运行被拒绝的任务。会影响程序的整体性能。
阻塞队列
新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。
- 容量为
Integer.MAX_VALUE的LinkedBlockingQueue:有界阻塞队列:有固定大小 ArrayBlockingQueue(有界阻塞队列):底层由数组实现,容量一旦创建,就不能修改SynchronousQueue(同步队列):没有容量,不存储元素,有任务就让空闲线程或新建线程执行DelayedWorkQueue(延迟队列):内部使用堆按照延迟的时间长短对任务排序,元素满了就会进行扩容,所以只能创建核心线程数的线程
线程池命名 ThreadFactory⭐
1、利用 guava 的 ThreadFactoryBuilder
ThreadFactory threadFactory = new ThreadFactoryBuilder()
.setNameFormat(threadNamePrefix + "-%d")
.setDaemon(true).build();
ExecutorService threadPool = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, TimeUnit.MINUTES, workQueue, threadFactory);
2、自己实现ThreadFactory
创建一个类实现 ThreadFactory 接口,重写newThread方法,返回一个setName之后的Thread即可。
2、通过 Executor 框架的工具类 Executors 来创建
FixedThreadPool:固定线程数量的线程池。新任务提交时如果有空闲线程立即执行,没有空闲线程则为暂存在任务队列中,等待空闲线程执行SingleThreadExecutor:只有一个线程的线程池。多余任务存在任务队列,按照 FIFO 顺序被执行。CachedThreadPool:根据实际情况调整线程数量的线程池。有空闲线程则执行任务,否则创建新线程,待执行完成后,返回线程池进行复用。ScheduledThreadPool:给定的延迟后运行任务或者定期执行任务的线程池
不推荐使用该方法创建线程池!⭐
FixedThreadPool和SingleThreadExecutor,使用有界阻塞队列:LinkedBlockingQueue,队列最大长度为Integer.MAX_VALUE,可能会堆积请求OOMCachedThreadPool,使用同步队列:SynchronousQueue,允许创建的线程数量为Integer.MAX_VALUE,线程执行任务慢会创建大量的线程导致OOMScheduledThreadPool和SingleThreadScheduledExecutor,使用无界延迟阻塞队列DelayedWorkQueue,任务队列最大长度为Integer.MAX_VALUE,堆积大量请求导致OOM
处理事务流程⭐
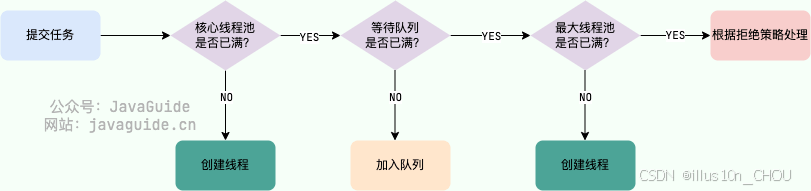
线程池中线程异常后,销毁还是复用?⭐️
使用execute()时,未捕获异常导致线程终止,线程池创建新线程替代;使用submit()时,异常被封装在Future中,线程继续复用。
这种设计允许submit()提供更灵活的错误处理机制,因为它允许调用者决定如何处理异常,而execute()则适用于那些不需要关注执行结果的场景。
设定线程池的大小⭐
线程池数量小,可能会任务堆积导致OOM。
线程池数量太大,大量线程争抢CPU,增加了上下文切换的成本。
- CPU 密集型任务(N+1):主要消耗CPU资源,多出来一个线程防止缺页中断或者任务暂停。
- I/O 密集型任务(2N):大量时间来处理 I/O 交互,在线程处理的过程中,就可以空出来CPU让其他线程执行。
CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内存中对大量数据进行排序。
凡涉及到网络读取,文件读取这类都是 IO 密集型,这类任务的特点是 CPU 计算耗费时间相比于等待 IO 操作完成的时间来说很少,大部分时间都花在了等待 IO 操作完成上。
动态修改线程池参数⭐
根据任务优先级来执行的线程池⭐
PriorityBlockingQueue (优先级阻塞队列),小顶堆形式的二叉堆,即值最小的元素有限出队。
排序能力:
- 提交到线程池的任务实现 Comparable 接口,并重写 compareTo 方法来指定任务之间的优先级比较规则。
- 创建 PriorityBlockingQueue 时传入一个 Comparator 对象来指定任务之间的排序规则(推荐)。
问题分析:
- 无界的任务队列,可能堆积导致OOM → 继承PriorityBlockingQueue 并重写 offer 方法的逻辑,插入元素数量超过指定值就返回 false
- 可能会导致饥饿问题,即低优先级的任务长时间得不到执行。 → 移除任务并提高优先级后重新加入
- 性能问题,为了保证线程安全。

















 480
480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









