



查询语句执行流程:连接器-(缓存)-分析器-优化器-执行器-存储引擎
缓存缺点:对一个表执行一次更新操作后,整个表的缓存会被清空,8.0已弃用缓存功能
----02-------------------------------------------
更新语句执行流程:连接器-(缓存)-分析器-优化器-执行器-innodb-redolog-更新缓存-返回客户端......系统空闲时:将redolog-》磁盘
redolog(粉板):innodb引擎特有日志
如果redolog满了-》将redolog写入磁盘腾出空间,涉及redolog两个坐标 writepos和checkpoint,checkpoint指哪擦哪,writepos指哪写哪,writepos追着checkpoint跑
WAL:write-ahead-logging,粉板与账本配合,先写日志再写磁盘的技术
crash-safe:有了redo log,InnoDB就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为crash-safe。
binlog:MySQL的Server层实现的,所有引擎都可以使用
redo log是物理日志,记录的是“在某个数据页上做了什么修改”;binlog是逻辑日志,记录的是这个语句的原始逻辑,比如“给ID=2这一行的c字段加1 ”。
redo log是循环写的,空间固定会用完;binlog是可以追加写入的。“追加写”是指binlog文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
数据库备份是通过binlog,当从备份数据库恢复数据时用的是binlog
binlog和redolog的两阶段提交:
执行器调用innodb引擎查找待更新数据-innodb查看数据是否在缓存页,在则返回,不在则从磁盘读取到内存再返回-
执行器执行字段操作-写入存储引擎缓存并写入redolog(状态preparing)-告诉执行器可以提交了-执行器写binlog-执行器发送命令给innodb将redolog状态改为commit
如果不用两阶段提交会有什么问题?
先写binlog后写redolog:binlog中有,redolog中没有(磁盘中也没有),从备库恢复数据时磁盘中由没有变成有了
先写redolog后写binlog:redolog中有(磁盘中有),binlog中没有,从备库恢复数据时磁盘中由有变成没有了
----03-------------------------------------------
隔离级别
读未提交、读提交、可重复读、串行化
事务视图、不同隔离级别下读数据结果不一样、事务回滚、长事务
MVCC:多版本并发控制,用于事务回滚。
假设一个值从1被按顺序改成了2、3、4,不同时刻启动的事务会有不同的read-view(一致性读视图),其中记录的值分别是1、2、4,同一条记录在系统中可以存在多个版本。
-------04----------------------------------------
索引模型:hash表、数组、搜索树,各自场景及优缺点
innodb索引模型为B+Tree,聚集索引、二级索引
索引维护:B+树为了维护索引有序性,在插入新值的时候需要做必要的维护,涉及申请数据页、页分裂、页合并
哪些场景要使用自增主键?
考虑因素:
1.缺点:二级索引的叶节点存储的是主键的值,要考虑主键过长时对存储空间的影响
2.优点:使用自增主键插入数据时,不会涉及聚簇索引维护的问题,因为是有序插入
为什么要重建索引?有什么好处?使索引文件更紧凑节省空间
---------05--------------------------------------
innodb回表查询、覆盖索引不回表
最左索引原则:联合索引的最左M个字段 / 字符串索引的最左N个字符
当创建联合索引(a,b)后,还需要创建一个(b)索引,这时需要考虑ab字段所占的空间,如果b占空间更大,可以考虑将索引换成(b,a)(a)
索引下推(5.6之后才有):索引(a,b)-》select x from y where a like "z%" and b="k" and c="m"; 在联合索引中先匹配到a,然后再下推比较b是否满足,然后再回表查c是否满足。减少回表次数。
---------06--------------------------------------
全局锁:
使整个数据库处于只读状态,所有更新、建表、更改表结构操作都会被阻塞,适用于对数据库做逻辑备份(binlog)时使用
FTWRL:mysql提供的加全局锁的命令Flush tables with read lock
表级锁:
表锁:一般是在数据库引擎不支持行锁的时候才会被用到
元数据锁(MDL):当对一个表增加列、删除列等修改元数据的操作(DDL)时,会自动加上MDL写锁,如果同时有两个增加列的操作,则要排队获取锁;
当对表进行增删改查操作(DML)时要加上MDL读锁,这时修改元数据的操作由于读锁被未释放所以获取不到写锁,所以操作被阻塞,保证用户在增删改查时表结构不会被更改
为表增加/修改/删除字段、增加索引,这些操作会扫描全表,大表尽量不要轻易做这些操作,比如卡表。
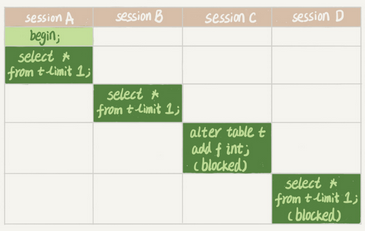
session A先启动,这时候会对表t加一个MDL读锁。由于session B需要的也是MDL读锁,因此可以正常执行。
事务中的MDL锁,在语句执行开始时申请,等到整个事务提交后再释放。
之后session C会被blocked,是因为session A的MDL读锁还没有释放,而session C需要MDL写锁,因此只能被阻塞。
如果只有session C自己被阻塞还没什么关系,但是之后所有要在表t上新申请MDL读锁的请求也会被session C阻塞。前面我们说了,所有对表的增删改查操作都需要先申请MDL读锁,就都被锁住,等于这个表现在完全不可读写了。
如果某个表上的查询语句频繁,而且客户端有重试机制,也就是说超时后会再起一个新session再请求的话,这个库的线程很快就会爆满。
如何安全为小表增加字段? kill长事务、为DDL命令增加等待时间
解决长事务,事务不提交,就会一直占着MDL锁。
在MySQL的information_schema 库的 innodb_trx 表中,你可以查到当前执行中的事务。如果你要做DDL变更的表刚好有长事务在执行,要考虑先暂停DDL,或者kill掉这个长事务。
但考虑一下这个场景。如果你要变更的表是一个热点表,虽然数据量不大,但是上面的请求很频繁,而你不得不加个字段,你该怎么做呢?
这时候kill可能未必管用,因为新的请求马上就来了。比较理想的机制是,在alter table语句里面设定等待时间,如果在这个指定的等待时间里面能够拿到MDL写锁最好,拿不到也不要阻塞后面的业务语句,先放弃。之后开发人员或者DBA再通过重试命令重复这个过程。
MariaDB已经合并了AliSQL的这个功能,所以这两个开源分支目前都支持DDL NOWAIT/WAIT n这个语法。
ALTER TABLE tbl_name NOWAIT add column ...
ALTER TABLE tbl_name WAIT N add column ...
-----07------------------------------------------
行锁:
innodb支持,myisam不支持
两阶段锁协议:行锁是在需要的时候才加上,但要等到事务结束时才释放。
如果你的事务中需要锁多个行,要把最可能造成锁冲突、最可能影响并发度的锁尽量往后放
死锁:
当并发系统中不同线程出现循环资源依赖,涉及的线程都在等待别的线程释放资源时,就会导致这几个线程都进入无限等待的状态,称为死锁
应对策略:
1.直接进入等待,直到超时,默认50s
2.主动死锁检测(默认开启):每个新来的被堵住的线程,都要判断会不会由于自己的加入导致了死锁,这期间要消耗大量的CPU资源。
怎么解决在 热点行更新时进行大量死锁检测,导致的性能问题呢?
考虑将热点行扩展为n行,每次选一行更新,冲突概率变成原来的1/n,可以减少锁等待个数,也就减少了死锁检测的CPU消耗。
---08事务隔离性----知识点较多----------------------------------------
事务数组、低水位高水位、行锁
---09--------------------------------------------
普通索引与唯一索引对比
主键是一种约束,唯一索引是一种索引,两者在本质上是不同的。
主键创建后一定包含一个唯一性索引,唯一性索引并不一定就是主键。
唯一性索引列允许空值,而主键列不允许为空值。
主键列在创建时,已经默认为非空值 + 唯一索引了。
主键可以被其他表引用为外键,而唯一索引不能。
一个表最多只能创建一个主键,但可以创建多个唯一索引。
主键和唯一索引都可以有多列。
主键更适合那些不容易更改的唯一标识,如自动递增列、身份证号等。
在 RBO 模式下,主键的执行计划优先级要高于唯一索引。 两者可以提高查询的速度。
1.查询对比:性能差距不大。在普通索引中查到第一条满足条件的记录后还要继续向后查(如果查到数据页末尾,需要继续查下个数据页),直到查到不满足条件的记录为止;唯一索引查到第一条记录后就结束了。
用于被更新的数据页不在缓存中时,不将磁盘数据页读入缓存,而是将更新操作写入changeBuffer,减少磁盘IO和内存占用,提高更新效率
当下次有查询查到这个数据页时,再将它读到缓存,然后将change buffer中的更新操作merge到数据缓存页中,从而保证一致性。
后台线程会定期merge,正常关闭数据库也会merge
2.更新对比:
2.1 更新的数据页在内存中:插入数据时,唯一索引需要先判断唯一性,其他方面两种索引没啥区别。
2.2 更新的数据页不在内存中:
唯一索引:需要先判断保证数据在表中不存在,这个操作必须要将数据页读入缓存进行判断。数据页都已经在内存中了,changebuffer优化机制就用不上了。
普通索引:写入changebuffer就结束了。
changebuffer使用场景:
1.适用写多读少场景,如果更新完数据马上就要读,会频繁触发changebuffer的merge操作将数据页读入缓存,changebuffer机制反而成了负担
2.只对普通索引的更新操作有优化作用,对唯一索引没用
有个DBA的同学跟我反馈说,他负责的某个业务的库内存命中率突然从99%降低到了75%,整个系统处于阻塞状态,更新语句全部堵住。而探究其原因后,我发现这个业务有大量插入数据的操作,而他在前一天把其中的某个普通索引改成了唯一索引,大量的插入操作都要先查找数据页是否在内存中,结果大量不在,都需要先将数据页读入内存,内存命中率降低,bufferpool中内存数据量暴涨导致更新停滞,必须进行清除内存数据页以腾出内存的操作。
changebuffer对比redolog:
redo log 主要节省的是随机写磁盘的IO消耗(随机写磁盘表数据 转成 顺序写redolog日志)
change buffer主要节省的则是随机读磁盘的IO消耗(当需要查询的时候才将数据页读入缓存)
现在要插入两条记录 insert into t(id,k) values(id1,k1),(id2,k2); (id1,k1)所在数据页在缓存中,(id2,k2)所在数据页不在缓存中
1.(id1,k1)插入缓存页,结束。(id2,k2)插入操作写入bufferpool中的changebuffer中,结束
2.两个插入操作均写入redolog
3.后台线程将changebuffer内存与磁盘中内容的同步、后台线程将bufferpool中缓存页与磁盘存储同步
现在要查询两条记录select * from t where k in (k1, k2);
1.(id1,k1)所在数据页在缓存中,直接拿到
2.(id2,k2)所在数据页不在缓存中,需将数据页读入缓存,取changebuffer中更新操作更新缓存页,返回正确结果
---10--------------------------------------------
explain rows字段是预估待扫描行数,是根据 n个数据页中的平均条目数*数据页总数 得到的近似值
优化器选错索引,有时是由于rows预估错误
1.可使用analyze table xxx 重新统计索引信息
2.可在sql中使用force index("idx_xxx")强制指定索引
3.修改sql引导优化器使用目标索引
4.删除无用索引
----11-------------------------------------------
字符串前缀索引
使用字符串前n个字符创建索引,而不是整个字符串创建索引
优点:索引文件存储内容变少,节省空间
缺点:与全字符串索引相比可能会损失索引区分度、增加回表次数、使覆盖索引失效,所以需合理决定前缀长度
使用前缀索引,定义好长度,就可以做到既节省空间,又不用额外增加太多的查询成本
如何决定前缀长度?
对比不同前缀长度的去重记录数
select
count(distinct email) as L,
count(distinct left(email,4))as L4,
count(distinct left(email,5))as L5,
count(distinct left(email,6))as L6
from SUser
如何优化前缀索引?
比如身份证号倒序存储,使用倒序索引增加区分度
使用hash索引,但会消耗CPU资源
---12--------------------------------------------
sql语句变慢,可能原因:
1.innodb内存爆满-》更新停滞-》淘汰数据页腾出内存-》如果数据页是脏叶则要进行刷盘同步操作(刷盘后操作对应的redolog就可以擦除了)
2.redolog中writepos追上checkpoint-》更新停滞-》将部分redolog日志刷盘同步到磁盘
InnoDB刷脏页的控制策略:
innodb_max_dirty_pages_pct 是脏页比例上限,默认值是75%
innodb_io_capacity 参数告诉Innodb磁盘的IO处理能力,建议设成磁盘的IOPS值,这个参数决定innodb将一个脏页刷盘时的速率【实战场景:MySQL的写入速度很慢,TPS很低,但是数据库主机的IO压力并不大。经过一番排查,发现罪魁祸首就是这个参数的设置出了问题。】
innodb_flush_neighbors 参数决定刷脏页时是否将相邻的脏页一起刷盘,优点是减少了多次刷盘时的随机IO消耗,缺点是如果是业务操作触发的刷盘,业务响应时间会变长。机械磁盘适合开启连坐刷盘,固态硬盘没必要开启。8.0中已默认关闭连坐刷盘
InnoDB怎么计算刷脏页的速度?
0. InnoDB全力刷脏页的速度 = innodb_io_capacity参数值(记为S)
1. InnoDB根据当前的脏页比例(脏页/总页数,假设为M),算出一个范围在0到100之间的数字F1,M与F1成正比,即脏页越多刷盘速度越快。
2. InnoDB根据redolog当前writepos和checkpoint对应日志序号之间的差值(假设为N,N越大说明两个指针之间的日志范围越大,又因为跨度是环形的,代表马上就要追上,需要更快的速率刷盘才行),也算出一个范围在0到100之间的数字F2。N与F2成正比。
3. InnoDB刷脏页的速度 = max(F1,F2)% * S
---14--------------------------------------------
Innodb中的count(*)需要全表扫描:
需要判断每行是不是对当前事务可见,以保证innodb默认的可重复读隔离级别。(比如启动事务A执行count(*),执行完之前事务B插入了一条记录,那为了保证可重复读,这条记录对事务A是不可见的)
Innodb中对count(*)的优化:
对于count(*)这样的操作,遍历哪个索引树得到的结果逻辑上都是一样的。主键索引树的叶子节点是数据,而普通索引树的叶子节点是主键值。因此,MySQL优化器会优先使用普通索引树来遍历,但是如果有where语句,且where中的条件不在普通索引中,没法利用索引下推,还是他要回表,这种情况下innodb还是会走全表扫描(项目中count全表时带了delstate=“01”导致走全表扫描)
---15--------------------------------------------
正常运行中的实例,数据写入后的最终落盘,是从redo log更新过来的还是从buffer pool更新过来的呢?
redo log更新缓存页,缓存页变脏页,脏页最终写入磁盘
---16--------------------------------------------
select city,name,age from t where city='杭州' order by name limit 1000;
orderby排序原理:
order_buffer 数据库分配的用于排序的内存空间
1.如果索引是联合索引(city,name),那么order by name可以去掉,因为name本身就是有序存储
2.如果索引是(city),有两种排序方式:
max_length_for_sort_data 参数:控制使用哪种排序方式,比如city、name、age 这三个字段的定义总长度是36,此参数>=36使用2.1,此参数<36使用2.2
2.1 全字段排序:通过city索引拿到主键后回表,取需返回的三个字段的值放到order_buffer中,
如果order_buffer内存够用,直接在内存中进行快排后返回。
如果order_buffer内存不够,需使用若干个临时文件一起排序,各自有序后通过归并算法排出最终结果后返回。
如果内存大,优先选此方式,效率高。
2.2 rowid排序:通过city索引拿到主键后回表,只取id和name放到order_buffer中,
如果order_buffer内存够用,直接在内存中进行快排后需要再通过id回表查city和age的值。
如果order_buffer内存不够,需使用若干个临时文件一起排序,各自有序后通过归并算法排出最终结果后,需要再通过id回表查city和age的值。
此方式节约内存,但是增加了一次回表查询,效率不如2.1。
---34--------------------------------------------
join的两种算法:
Index Nested-Loop Join:join字段是“被驱动表”的索引,驱动表全表扫描,每次拿一条数据-》取出join字段的值-》在被驱动表的索引中找-》回被驱动表取数据-》合并数据
Block Nested-Loop Join:join字段不是“被驱动表”的索引,驱动表将整表的数据读入join_buffer,如果join_buffer_size不足容纳整个表,就分多次读入,每次读入一批后-》对被驱动表全表扫描对比join_buffer中匹配-》每次取被驱动表的一条数据,拿到这条数据中join字段的值-》去join_buffer中匹配-》直到被驱动表全部匹配完,将join_buffer清空-》将驱动表剩余数据读入join_buffer-》再进行一遍被驱动表全表匹配
join优化点:
使用小表做驱动表
被驱动表的join字段要有索引
被驱动表的join字段没有索引只能使用Block Nested-Loop Join算法,很危险,如果硬要使用,调大join_buffer_size
explain中extra字段中若有 using join buffer(Block Nested Loop),这种join语句会占用大量内存,而且被驱动表可能会进行多次全表扫描,尽量不要用

















 1179
1179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









