







上一篇 Spring Boot学习(一) 搭建一个 Spring Boot 项目
持久化数据是几乎所有应用程序最基本的功能,不管是将数据写入 Oracle、SqlServer、MySQL等关系型数据,还是将数据写入 HBase、MongoDB等非关系型数据库,Spring 都提供了很好的数据持久化支持。
1、配置数据源
Spring 配置数据源有三种方式:
- 通过 JDBC 驱动程序定义的数据源。
- 通过 JNDI 查找的数据源
- 连接池的数据源
在本项目中使用连接池的方式配置数据源。数据库连接池在内部对象池中,维护一定数量的数据库连接,并对外暴露数据库连接的获取和返回方法。使用完毕后由连接池管理器回收,并为下一次使用做好准备。其优点在于:
- 资源重用 (连接复用):由于数据库连接得到重用,避免了频繁创建、释放连接引起的大量性能开销。在减少系统消耗的基础上,增进了系统环境的平稳性(减少内存碎片以级数据库临时进程、线程的数量)。
- 更快的系统响应速度:数据库连接池在初始化过程中,往往已经创建了若干数据库连接置于池内备用。此时连接池的初始化操作均已完成。对于业务请求处理而言,直接利用现有可用连接,避免了数据库连接初始化和释放过程的时间开销,从而缩减了系统整体响应时间。
- 新的资源分配手段:对于多应用共享同一数据库的系统而言,可在应用层通过数据库连接的配置,实现数据库连接技术。
- 统一的连接管理,避免数据库连接泄露:在较为完备的数据库连接池实现中,可根据预先的连接占用超时设定,强制收回被占用的连接,从而避免了常规数据库连接操作中可能出现的资源泄露。
目前比较流行的连接池开源框架有:
- Apache Commons DBCP (http://jakarta.apache.org/commons/dbcp)
- c3p0(http://sourceforge.net/projects/c3p0/)
- BoneCP (http://jolbox.com/)
- Druid
在这里,我们选用阿里的 Druid 连接池框架(与 Apache Druid 不同),阿里 Druid 最大的特点就是可监控性,Druid 提供了各种流量池的监控数据,可以让开发者更好的监控流量池的健康状态等信息。
首先,我们在 pom.xml 中引入 Druid 和 MySQL 的依赖,代码如下:
<properties>
<druid.version>1.1.10</druid.version>
<mysql.version>5.1.47</mysql.version>
...
</properties>
<dependencies>
<!-- MySQL 连接驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<!-- Druid 依赖 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>${druid.version}</version>
</dependency>
...
</dependencies>添加依赖以后,我们在 application.yml 中加入数据源的配置:
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&characterEncoding=utf8 # 数据连接路径
username: root # 用户名
password: 123456 # 密码
type: com.alibaba.druid.pool.DruidDataSource # 连接池的类型,这里选择 Druid
druid: # 连接池相关配置
initial-size: 1 # 初始化连接池大小
max-active: 2 # 最大活跃连接数
max-wait: 2 # 最大等待连接数
validation-query: select 1 from dual # 连接有效性校验 SQL接着,我们将连接池注册为一个 Bean,可以直接在启动类里面将连接池声明为一个 bean,但是为了将不同的配置分开,我们在 com.example.demo 包下新建 config 包,然后新建一个 DataSourceConfig 类,并在该类上添加 @Configuration 注解,标识这是一个配置类。然后新增一个 dataSource() 方法,并添加注解 @Bean 注册连接池到 Spring 的 BeanFactory,为了更简洁地使用上面在 application.yml 声明的数据源以及连接池的配置信息,我们引入@ConfigurationProperties 注解,这个注解可以达到 @Value 一样的效果,将配置项的值赋值给对应的变量,但是 @ConfigurationProperties 注解更强大,只需要指定配置的前缀,就可以将指定配置下所有的属性自动映射到变量(具体使用可以参考这篇博客:https://www.cnblogs.com/jimoer/p/11374229.html)。首先需要添加 spring-boot-configuration-processor 的依赖:
<dependencies>
<!--配置相关的注解 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
...
</dependencies>然后在 dataSource() 方法上添加 @ConfigurationProperties(prefix = "spring.datasource") 就能将 application.yml 中配置的数据源连接信息自动赋值给 DruidDataSource 对象,完整代码如下:
package com.example.demo.config;
import com.alibaba.druid.pool.DruidDataSource;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
@Configuration
public class DataSourceConfig {
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DataSource dataSource() {
return new DruidDataSource();
}
}2、集成持久化框架
目前持久化框架有很多,对于关系型数据库,最流行的要属 Hibernate 和 Mybatis 框架了,国内比较流行使用 Mybatis,MyBatis 是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。在本例中我们就将集成 Mybatis 框架,首先引入 Mybatis 的依赖,代码如下:
<properties>
<mybatis.version>2.1.3</mybatis.version>
...
</properties>
<dependencies>
<!-- Mybatis 依赖 -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>${mybatis.version}</version>
</dependency>
...
</dependencies>前面提到,我们可以将 SQL 写在注解或者 XML 文件中来配置和映射数据为数据库中的记录,将 SQL 通过注解的方式可以直接将SQL执行结果,作为方法的执行结果,例如:
@Select(value = "select * from sys_users")
List<Map> queryAllUsers();但是这样将 SQL 和 Java 代码杂糅在一起,必然降低代码的美观以及可读性,对于复杂的 SQL 尤为如此。因此,一般的做法是将 SQL 写入 XML 文件,然后将方法与 XML 中的 SQL 对应起来,这样将 Java 代码和 SQL 分离开,既保证了项目结构的层次性,又维护了代码的可读性及可维护性。另外,我们将 SQL 对应的 XML 文件放在 resources 目录下,而不直接放在 Java 包内。对此,我们需要在 application.xml 中配置 Mybatis 的 mapper 文件的位置,配置如下:
mybatis:
mapper-locations: classpath:com/example/demo/*Mapper.xml # 配置 Mybatis SQL 文件的位置
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl # 支持打印执行的 SQL 语句从配置可以看到,我们在 resources 目录下新建了目录 com/expamle/demo,mybatis.mapper-locations 将 com/expamle/demo 目录下所有命名格式为 *Mapper.xml 的文件作为 Mybatis 的 SQL 映射文件。另外,使用 configuration.log-impl 配置了输出运行中执行的 SQL。
3、编写业务代码
为了避免持久化的逻辑分散到应用的各个组件中,最好将数据访问的功能放到一个或多个专注于此项任务的组件中。这样的组件通常称为数据访问对象(data access object,DAO)或 Repository。我们在 com.example.demo 包下新建 dao 包,然后新建 DemoDao 接口,提供对数据访问的能力。为了将 DemoDao 接口标识为 Mybatis 数据访问层的接口,有两种实现方式,第一种,在启动类 DemoApplication 上添加注解 @MapperScan,然后在其属性 value 上指定要扫描的包;另一种方式就是直接在 DemoDao 接口上添加注解 @Mapper,标识这是一个 Mybatis 数据访问层的接口。这里采用第二种方式,这样让代码更清晰。然后在 DemoDao 接口中声明一个方法 queryAllUsers(),整体代码如下:
package com.example.demo.dao;
import org.apache.ibatis.annotations.Mapper;
import java.util.List;
import java.util.Map;
@Mapper
public interface DemoDao {
/**
* 查询所有用户
* @return
*/
List<Map> queryAllUsers();
}接着,在之前 resources 下新建的目录 com/example/demo 下新建 DemoMapper.xml 文件,并设置 mapper 节点的 namespace 为 DemoDao 的全限定名,然后在该文件中新增 id 为 queryAllUsers 的查询 SQL,代码如下:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.demo.dao.DemoDao">
<select id="queryAllUsers" resultType="map">
select * from sys_users
</select>
</mapper>目前我们已经完成了数据访问层 dao 的逻辑,接下来完成 service 层的代码。service 层是业务层,主要编写具体的业务逻辑,它连接 controller 层和dao 层,是业务逻辑的主要存放位置。在
com.example.demo 包下新建 service 包,然后新建 DemoService 类(更合理的做法是 增加一个 IDemoService 的接口,声明各个业务逻辑处理的方法,然后在该包下新建一个 impl 的包,然后再新建 DemoServiceImpl 类,该类实现了 IDemoService 接口,并实现了该接口的所有虚方法),该类上添加注解 @Service,然后在该类中,声明一个 DemoDao 的属性,然后为属性添加 @Autowired 注解,自动装载该属性。然后新增 geteAllUsers() 方法,直接调用 DemoDao 的 geteAllUsers() 方法,代码如下:
package com.example.demo.service;
import com.example.demo.dao.DemoDao;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.Map;
@Service
public class DemoService {
@Autowired
DemoDao demoDao;
public List<Map> geteAllUsers(){
return demoDao.queryAllUsers();
}
}接下来,在 DemoController 中新增一个 DemoService 的属性,同样添加 @Autowired 注解,自动装载该属性,因为项目在启动的时候已经将 DemoService 注册为一个单例的 bean(默认情况下),因此无需再初始化。然后新增一个方法,getAllUsers() 并添加注解 @GetMapping("getUsers"),直接调用 DemoService 的 geteAllUsers() 方法,代码如下:
package com.example.demo.rest;
import com.example.demo.service.DemoService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
import java.util.Map;
@RestController
@RequestMapping("greet")
public class DemoController {
@Autowired
DemoService service;
@GetMapping("getUsers")
public List<Map> getAllUsers(){
return service.geteAllUsers();
}
...
}至此,所有代码已经编写完成,目前的项目结构如下图所示:
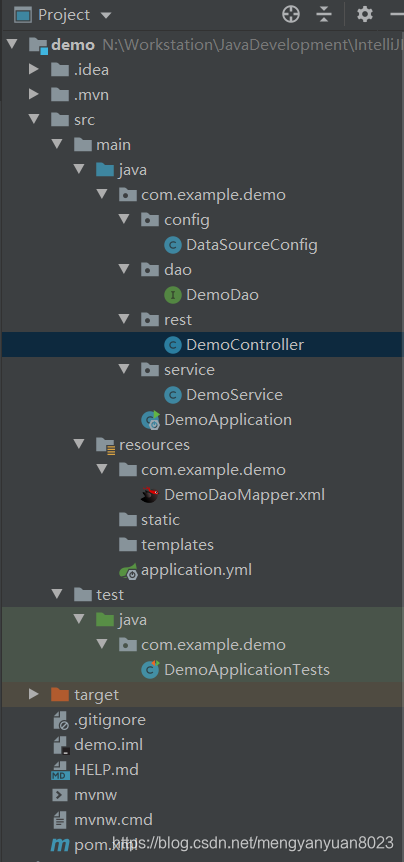
4、调试
启动项目,浏览器打开:http://localhost:8080/demo/greet/getUsers,可以得到如下图所示结果:

浏览器打开:http://localhost:8080/demo/druid/,可以看到 Druid 监控页面如下图所示:
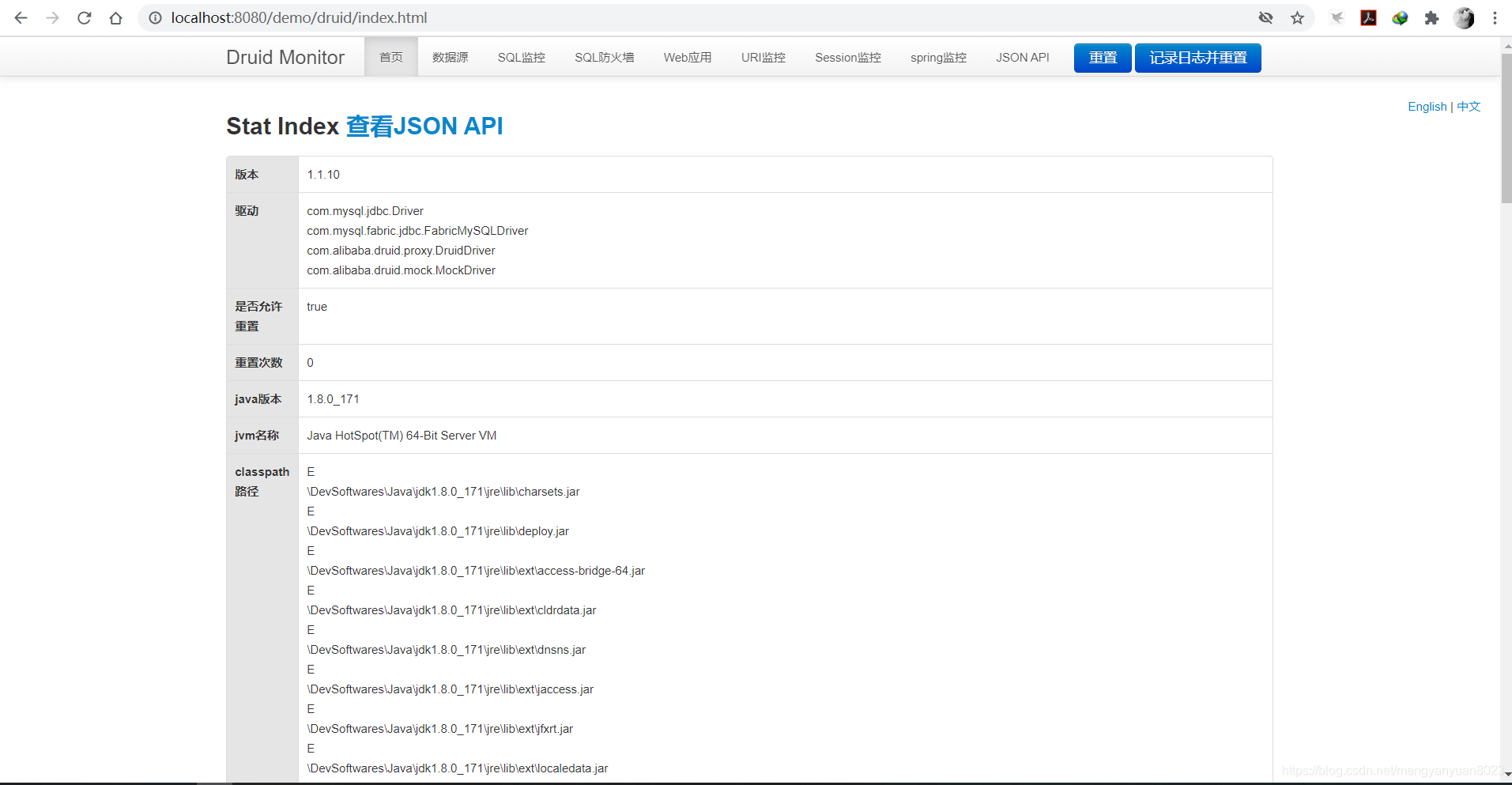
可以通过以下方式来为 Druid 添加配置:
@Bean
public ServletRegistrationBean<StatViewServlet> druidStatViewServlet() {
ServletRegistrationBean<StatViewServlet> registrationBean = new ServletRegistrationBean<>(new StatViewServlet(), "/druid/*");
registrationBean.addInitParameter("allow", "127.0.0.1");// IP白名单 (没有配置或者为空,则允许所有访问)
registrationBean.addInitParameter("deny", ""); // IP黑名单 (存在共同时,deny优先于allow)
registrationBean.addInitParameter("loginUsername", "admin");
registrationBean.addInitParameter("loginPassword", "1234");
registrationBean.addInitParameter("resetEnable", "false");
return registrationBean;
}
附:sys_users 表结构及测试数据
-- ----------------------------
-- Table structure for sys_users
-- ----------------------------
DROP TABLE IF EXISTS `sys_users`;
CREATE TABLE `sys_users` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(255) NOT NULL,
`password` varchar(255) NOT NULL,
`role` varchar(255) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of sys_users
-- ----------------------------
INSERT INTO `sys_users` VALUES ('1', 'admin', '123456', '1');
INSERT INTO `sys_users` VALUES ('2', 'manager', '123456', '2');


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









