







 本文介绍了如何利用R语言进行序列模式挖掘,包括数据格式化为事务矩阵,运行SPADE算法,以及解释和应用挖掘出的序列规则。通过支持度、置信度和提升度三个指标,可以预测如Azure服务包等业务需求。
本文介绍了如何利用R语言进行序列模式挖掘,包括数据格式化为事务矩阵,运行SPADE算法,以及解释和应用挖掘出的序列规则。通过支持度、置信度和提升度三个指标,可以预测如Azure服务包等业务需求。
在这份指南中,Allison Koenecke 揭示了
当客户增加Azure云的服务时,
微软如何通过延伸传统购物篮分析实现对消费者潜在服务需求的
推荐。
问题声明:
Market Basket Analysis (MBA)购物篮分析回答了一个标准的商业问题:通过一组超市的小票,我们可以发现经常一起购买的商品吗(比如花生酱和果冻)?
假设我们想要提高客户服务体验进行挖掘,
比如,确定过去买过花生酱,是否就意味着未来购买面包的可能性更高。基于此,我们应用了购物篮分析的序列模式,因为
在分析中引入了时间变量,所以
有时候又叫
“顺序项集挖掘”或“顺序模式挖掘”。
序列模式挖掘已经被很多企业应用,
从确定病人的医疗处方顺序到检测入侵,如应用层攻击等方面。在这篇指南中,通过分析一段时间内购买的产品,我们想要明确是否可以找到适合捆绑并乐于被消费者购买的产品,同时也可以检测这
些捆绑产品是如何随着时间演变的。
在下面的教程中,我们将讲解
使用
SPADE
算法的
R包
arulesSequences
,
具体的,根据一个包含历史用户购买服务数据的Excel表格,我们产生两个独立的Excel表格,一个是服务捆绑名单,一个通过序列模式演示了服务组合是如何随着时间变化的。
通过演示如何使用序列模式做销售推荐来
解释后一个Excel
。
我们下面跑的例子是为了解决微软Azure 服务 的销售人员去跟消费者推荐哪个额外产品的问题,
考虑到客户目前的云产品消费服务组合,我们更想知道,那些购买了网络服务的消费者是否也会在接下来的几个月购买网站分析,
出于保密原因,实际的Azure服务名称已经被删除。
第一步:将数据格式化为事务矩阵
首先,让我们导入标准的事务数据然后转化成如图一那种示例矩阵,如果交易
是跨列列出的,而不是跨行列出的,只需要使用 R 中的
reshape2
,
data.table
, 或者
tidyr之一
去重新转置数据即可。
注意转换为正确的矩阵格式,最简单的方式是导出序列到一个临时txt中,使用
read_baskets中的
arulesSequences
包功能重新导入。
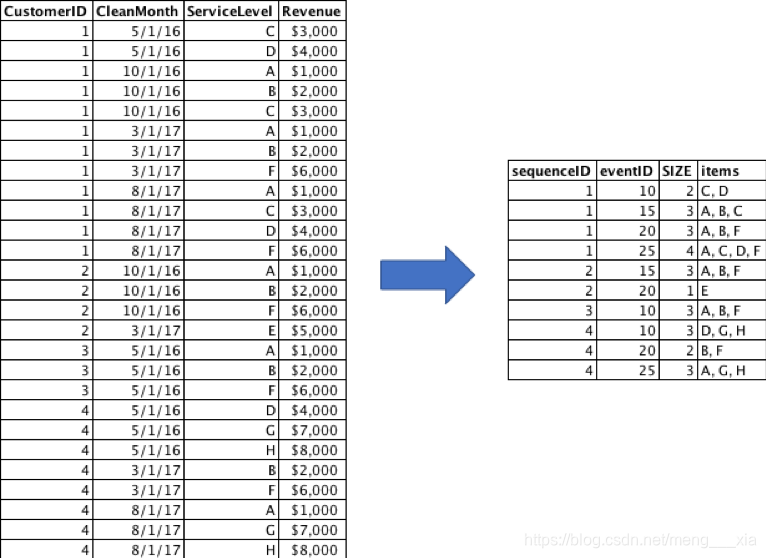
图1:数据转化成事务矩阵示例,ServiceLevel 中的字母表示Azure的服务,比如电脑,网路,数据存储,网站和客户端等。
# Import relevant packages
library(dplyr)
library(tidyverse)
library(arulesSequences)
#Import standard transaction data
transactions = read.csv("transactions.csv")
# Start time of data to be considered
start_month <- "2015-07-01"
# Create list of Azure services by customer ID and CleanMonth (formatted dates)
trans_sequence <- transactions %>%
group_by(CustomerID, CleanMonth) %>%
summarize(
SIZE = n(),
ServiceLevel = paste(as.character(ServiceLevel), collapse = ';')
)
# Make event and sequence IDs into factors
elapsed_months <- function(end_date, start_date) {
ed <- as.POSIXlt(end_date)
sd <- as.POSIXlt(start_date)
12 * (ed$year - sd$year) + (ed$mon - sd$mon)
}
trans_sequence$eventID <- elapsed_months(trans_sequence$CleanMonth, start_month)
trans_sequence = trans_sequence[,c(1,5,3,4)]
names(trans_sequence) = c("sequenceID", "eventID", "SIZE", "items")
trans_sequence <- data.frame(lapply(trans_sequence, as.factor))
trans_sequence <- trans_sequence[order(trans_sequence$sequenceID, trans_sequence$eventID),]
# Convert to transaction matrix data type
write.table(trans_sequence, "mytxtout.txt", sep=";", row.names = FALSE, col.names = FALSE, quote = FALSE)
trans_matrix <- read_baskets("mytxtout.txt", sep = ";", info = c("sequenceID","eventID","SIZE"))
第二步 运行spade算法
我们将使用SPADE(使用等价类的顺序模式发现)算法进行序列模式购物篮分析,它由cspade函数调用,
下面的图2详细介绍了这种按序列长度递归的方法。举个例子,首先,我们寻找长度为1的序列(我们需要找到那个独立出现在
我们的交易数据中
的Azure 服务)。在完成单长度序列后(比如A 比D出现的频繁)。
我们观察两种类型的双元素序列。
首先,我们观察双元素的时间序列(‘B’-> “A”需要B要先于A被购买)然后,我们观察双元素的组合(‘AB’要求A和B在某个时间同时存在)然后,基于最频繁的长度为2的组合,我们接着寻找3个元素的序列(例如D->B->A)和三元素的组合(比如 ABF).这样继续直到我们到达一个用户定义的最大长度或者达到一个没有办法发现更多组合的长度。
接下来,我们将把术语“itemset”称为客户购买的任何产品集合,因此产品集合可以由产品组合(可以是单个产品)或时间序列组成。
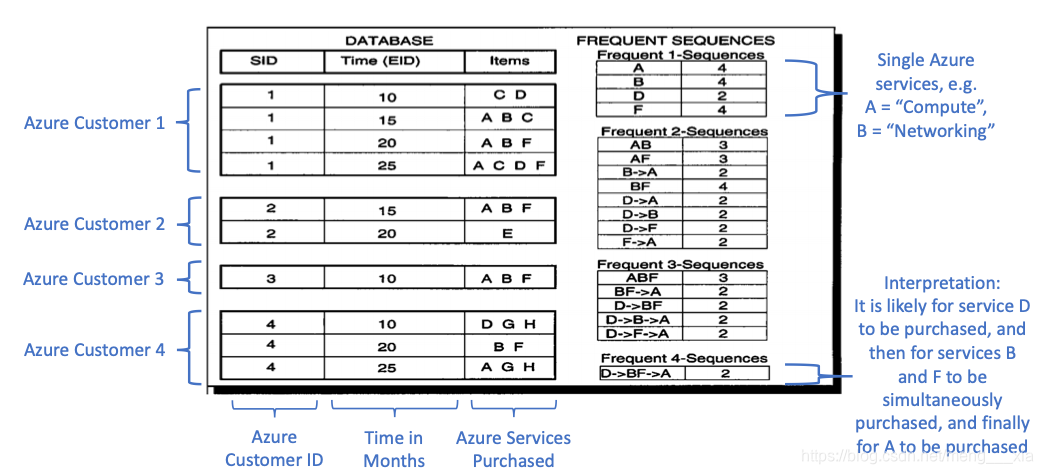
图2:SPADE 算法频繁序列生成(译者注:根据客户id来统计出现频次,一个用户多次出现相同组合算1次)
我们在描述SPADE算法时多次用了“频繁”这个词,这到底意味着什么?通常有三个不同的术语来衡量 购物篮的频繁度,这最好的三个衡量指标是:支持度、置信度和提升度。下面是它们的定义:
Support(
{ɑ
}
):
a的支持度:总交易中包含a物品的占比。高支持度值意味着那些可以在很多交易中应用的常见组合。
support({a})=4/4=1
Confidence(
{ɑ
} →
{β
}
):
a->b的置信度:
a->b的序列组合满足在a先于b发生这个约束条件下,包含a的集合的子集,置信度可以理解为条件概率 在给定一个预发生的包含a集合的交易中,越高的置信度意味着在未来购买b的可能性越高,严格来说,
a->b的置信度=包含a和b的支持度/包含a的支持度
Support({ɑ} and {b}) / Support({ɑ}).
confidence({a}->{b})=
Support({ɑ} and {b}) / Support({ɑ})=(3/4)/1=3/4=0.75
Lift({ɑ} → {β}
)
a->b的提升度:应用序列规则
a->b比a和b单独出现
提高购买的程度 。
a->b的提升度=同时包含a和b的支持度/(
a的支持度*b的支持度
)。
Support({ɑ} and {β}) / (Support({ɑ}) * Support({β}))
注意:如果a和b在事件中独立存在,那么分母就等于分子,提升度就等于1,当提升度大于1时,意味着现存的a可以增加b
在未来的交易中出现的概率。这可以理解为啊和b之间有强相关。相反的,当提升度小于1时,意味着a和b是负相关关系,
这个指标不仅告诉你什么是受所有客户欢迎的,而且告诉你根据客户的历史,什么对他是最有用的(例如:一个低提升度的值可以理解为b是a的好的替代品)。
Lift({ɑ} → {β}
)=
Support({ɑ} and {β})
/ (Support({ɑ}) * Support({β})) =(3/4)/(1*1)=0.75
回到我们的案例中,回想一下我们的(在第一步创建的
trans_matrix)输入是按月购买Azure服务的顺序,只用一行代码,
cspade函数返回按支持程度降序挖掘的频繁序列。进一步的,为了减少运行时间,我们可以定义最小支持度限制输出,在指南的第三部分,下面的代码中,我们使用0.3这个最小支持度在18个不同序列的案例中应用,我们将明白置信度和提升度是怎样起作用的。
#Get frequent sequences and corresponding support values
s1 <- cspade(trans_matrix, parameter = list(support = 0.3), control = list(verbose = TRUE))
s1.df <- as(s1, "data.frame")
summary(s1)
我们可以在s1.df中查看结果,通过在s1上调用summary函数,进行接下来的分析,特别的,我们关注:
(1)最频繁的产品集(A,B)
(2)在事件中出现的频繁产品集(考虑元素)
(3)集合中组合长度的分布
(4)在序列集合中的产品个数的分布(考虑序列长度)
(5)最小值,最大值,平均值和中位数
(6)最频繁序列挖掘,按照支持度排序。
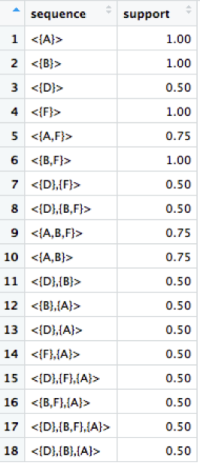

图3:cspade算法输出的样例展示了18个频繁的项目集,以及对这些值进行的分析
(例如:
项目A作为各个项目集的一部分出现了18次中的11次,但是在一个交易中单独出现只有8次),
注意:
每个序列中集合之间的逗号分隔符意味着时间序列,如图2所示。
第三步:找到并解释序列规则
只需多一行代码就可以将这组序列转换为一组规则。特别的,强关联规则通常满足最小支持度和置信度,左项必须在右项之前发生。在这个例子中我们已经设置了最低置信度为0.5,通常意义上的默认值为0.8。
# Get induced temporal rules from frequent itemsets
r1 <- as(ruleInduction(s1, confidence = 0.5, control = list(verbose = TRUE)), "data.frame")返回的数据见图4.我们可以将rule列解释为在接下来的几个月内,哪些Azure服务包会需要额外的服务。此外,对于所有规则来说,我们可以通过3个维度去比较:支持度,置信度和提升度。
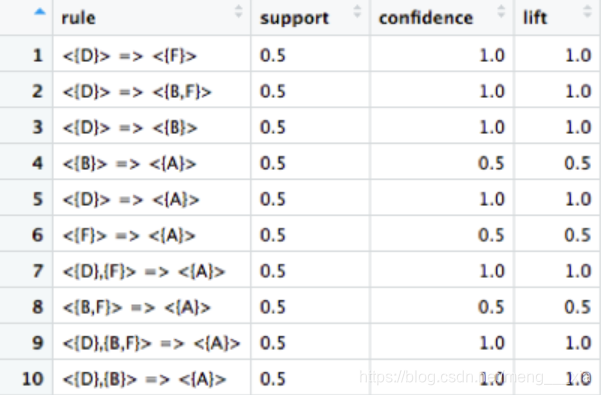
图4 ruleInduction 方法输出示例
我们如何理解这个?举例,当我们看到一个客户购买服务D之后每一次总会同时购买B和F。这就是图4的第二行置信度值的含义。回头看图1,我们看到会员卡号为1和4的顾客就是这种情况,同时,提升度为1.0意味着D被购买的可能性,和B和F稍后被购买的可能性是完全独立的。所以,我们不能得出购买B和F 是依赖先购买D的基础之上的。但是这些事件也没有出现负面的依赖(换句话说,
也不是说用户之前购买了D,以后就没有必要再购买B和F了,)
虽然这个输出相当简单,但我们可以做一些简单的处理,以解析规则的“before”和“after”步骤,并根据特定用例的最重要的度量进行排序。
# Separate LHS and RHS rules
r1$rulecount <- as.character(r1$rule)
max_col <- max(sapply(strsplit(r1$rulecount,' => '),length))
r_sep <- separate(data = r1, col = rule, into = paste0("Time",1:max_col), sep = " => ")
r_sep$Time2 <- substring(r_sep$Time2,3,nchar(r_sep$Time2)-2)
# Strip LHS baskets
max_time1 <- max(sapply(strsplit(r_sep$Time1,'},'),length))
r_sep$TimeClean <- substring(r_sep$Time1,3,nchar(r_sep$Time1)-2)
r_sep$TimeClean <- gsub("\\},\\{", "zzz", r_sep$TimeClean)
r_sep_items <- separate(data = r_sep, col = TimeClean, into = paste0("Previous_Items",1:max_time1), sep = "zzz")
# Get cleaned temporal rules: time reads sequentially from left to right
r_shift_na <- r_sep_items
for (i in seq(1, nrow(r_shift_na))){
for (col in seq(8, (6+max_time1))){
if (is.na(r_shift_na[i,col])==TRUE){
r_shift_na[i,col] <- r_shift_na[i,col-1]
r_shift_na[i,col-1] <- NA
}
}
}
names(r_shift_na)[2] <- "Predicted_Items"
cols <- c(7:(6+max_time1), 2:5)
temporal_rules <- r_shift_na[,cols]
temporal_rules <- temporal_rules[order(-temporal_rules$lift, -temporal_rules$confidence,-temporal_rules$support, temporal_rules$Predicted_Items),]
write.csv(as.data.frame(temporal_rules), file = "TemporalRules.csv", row.names = FALSE, na="")
# Get unique frequent itemsets existing in rules (subset of those in s1.df)
baskets_only <- temporal_rules[,1:(ncol(temporal_rules)-3)]
basket_mat <- as.vector(as.matrix(baskets_only))
freq_itemsets_in_rules <- unique(basket_mat[!is.na(basket_mat)])
write.csv(as.data.frame(freq_itemsets_in_rules), file = "FreqItemsetsInRules.csv", row.names = FALSE)
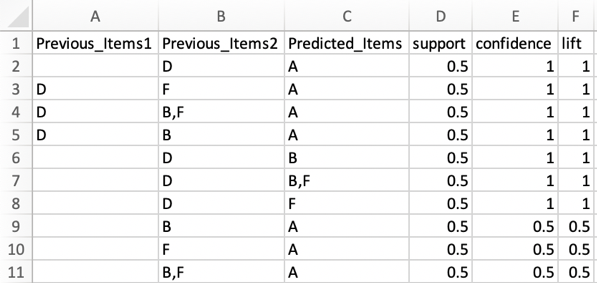
图5:输出可读的文件
TemporalRules.csv,
FreqItemGroupingsInRules.csv中用列表的形式存储项集的值
现在,我们两个主要的结果都存在csv文件中, FreqItemGroupingsInRules.csv 和TemporalRules.csv. 总之,我们所关心的所有项目集都将由频繁的项目分组或时间序列规则来定义。但是,我们如何将这些应用到我们的商业环境中呢?
首先,频繁项集的分组本身对行业是有价值的,即使忽略B和F的下单顺序,知道B 和F经常被一起购买就可以促成很多商业机会,有什么理由把它们分开销售? 客户是否对两种产品都有需求,把它们揉成一种产品会更好?
其次,随着时间的积累, 时间序列规则可以帮我们实现更明确的推荐目标,比如,假设我们看到高置信度和合理的提升度的规则D->{BF}(在我们例子中分数都是1),对于一个购买了D产品的顾客来说,我们可以推荐他们现在购买包含B和F的组合。在未来时间的积累下,假设我们的顾客喜欢这个推荐并且同时购买了B和F.现在,我们可以再考虑时间规则并且发现{BF}->A的规则(我们根据产品被购买的匹配左项和高置信度来选择右项)现在,我们可以更进一步的在未来某个时间推荐我们的顾客购买A产品。事实上,我们使用图5被处理过的Excel输出文件可以更容易的理解这些规则-具体的推荐路径可以看第四行。这种个性化目标推荐的风格既对我们的顾客有利又对我们的销售有帮助,随着收集更多的数据用于置信度和提升度的计算,下一步的推荐将变得越来越精准。
考虑的事情:
以上步骤显示了查找实现序列模式的一种高效计算方法;这比使用arules包在每个时间点中查找频繁项目集,然后在事件维度上手动的比较它们,然后,依靠支持度、置信度和提升度去否决预期的暴力方法快很多, 即使是arulesSequences方法也可能花费大量的计算时间,因此,如果关注的预期是输出最高分数的规则,那么在测试低值之前,从高阈值开始可能是更谨慎的做法。
除了频繁度的界限参数, 产品可测量的聚合程度也值得考虑 ,让我们假设我们的产品或服务按照层次来销售,在最少层级上运行SPADE算法将花费更少的时间,因为该算法将识别更多的重复服务出售给不同的客户。如果在你想要的特定产品级别上有一个需要很长时间运行的最小界限的需求,考虑在一个更高,产品层次更聚合的级别上运行上面的代码,然后通过向下钻取明确在未来哪些是最好的推荐产品。举个例子,在Azure服务中更高级的产品上(比如分析产品,电脑产品,网页加移动端产品等等),假设我们发现我们应该推荐分析产品给一个特定的客户,在进一步验证之前,可能我们发现基于分析产品的序列规则在更细粒度上推荐机器学习工具包而不是数据湖的产品。因此,我们仍然可以对底层产品提出合理的建议, 而不需要在整个数据集上花费过多的计算时间。
最后,以上的序列模型挖掘代码有可能不能直接适用,如果你
(1)关心 在任意给定的时间点被购买的项目集的质量( 因为在本教程中我们只观察项目集的存在或不存在)或者
(2) 拥有随时间变化的无规律的数据,但目标是对未来特定时间间隔的预测。在前者中,用单独的项目名称对重复项目集进行重新编码(比如:为每一个购买集起一个名字)可以提高质量
。在后者中, 最好的做法是使用有规律的时间间隔;这个可以通过对购买产品的分箱来实现,比如按月(如果是在月时间维度上做预测),在销售系统基础上,支持修改和反馈0购买是必须的。
综上所述,
考虑到财务团队广泛使用Excel跟踪历史采购,
这种方法提供了一种有效的工具,可以对产品或服务的采用情况进行深入了解。
这里实现的顺序模式挖掘可以用来向公司的销售人员推荐产品,发现顾客接下来会购买什么,洞察哪些产品组合随着时间可以持续流行。
参考文献:
-
Srikant, R., Agrawal, R., Apers, P., Bouzeghoub, M., Gardarin, G. (1996) "Mining sequential patterns: Generalizations and performance improvements", Advances in Database Technology — EDBT '96 vol. 1 no. 17.
-
Aileen P. Wright, Adam T. Wright, Allison B. McCoy, Dean F. Sittig, The use of sequential pattern mining to predict next prescribed medications, Journal of Biomedical Informatics, Volume 53, 2015, Pages 73-80, ISSN 1532-0464, https://doi.org/10.1016/j.jbi.2014.09.003.
-
Song SJ., Huang Z., Hu HP., Jin SY. (2004) A Sequential Pattern Mining Algorithm for Misuse Intrusion Detection. In: Jin H., Pan Y., Xiao N., Sun J. (eds) Grid and Cooperative Computing - GCC 2004 Workshops. GCC 2004. Lecture Notes in Computer Science, vol 3252. Springer, Berlin, Heidelberg.
-
Package ‘arulesSequences’ documentation: https://cran.r-project.org/web/packages/arulesSequences/arulesSequences.pdf.
-
J. Zaki. (2001). SPADE: An Efficient Algorithm for Mining Frequent Sequences. Machine Learning Journal, 42, 31–60.
-
Data Mining Algorithms in R: https://en.wikibooks.org/wiki/Data_Mining_Algorithms_In_R/Sequence_Mining/SPADE.
-
Analyzing Transaction Data like a Data Scientist: https://rpubs.com/Mahsa_A/Part4_AnalyzeTransactionData.
原文地址:

















 1144
1144



 到【灌水乐园】发言
到【灌水乐园】发言








