




 本文介绍如何使用Vim编辑器的列操作功能,快速将数据库查询结果转换为SQL IN子句所需的格式,提高工作效率。通过具体步骤演示,包括使用Visual Block模式和替换命令,实现对大量数据的高效处理。
本文介绍如何使用Vim编辑器的列操作功能,快速将数据库查询结果转换为SQL IN子句所需的格式,提高工作效率。通过具体步骤演示,包括使用Visual Block模式和替换命令,实现对大量数据的高效处理。
小伙伴们下午好!
看起来查多少张表跟vim有啥关系?因为查表是目的,核心技术用到了vim,用到了【查找替换】和visual block编辑模式。
一、SQL
想知道你系统有多少张表?eg:我们系统是mysql数据库,思路是什么呢?
show databases; #所有库
select database();选中的是哪个库?
use 某一个库;
show tables; #当前库有多少表?
一个一个count下,如果有10个以上的库,会比较痛苦,效率低下;如果想要精确的数字,只统计大库自然不符合要求。
核心是:information_schema库。
这个库有个TABLES表,里面包含了库和表的关系。那么很简单了:
SELECT
COUNT(0) tableCount
FROM
information_schema.tables
WHERE
table_schema in ();
那么in () 表示所有的库名,如何快速格式化为mysql的in()的格式?
请继续往下看
二、用到vim的地方(核心:vim列操作)
当然实现上面目标可以有很多灵活办法,我这里用vim举例,大家完全可以不拘泥于此。也可以用excel函数,也可以用xargs命令。
- 拿到所有库 show databases;
- 复制粘贴到一个txt文档中,vim进行编辑
- vim如何实现快速格式化?(’’,’’,’’)这种效果?
法1:块模式选中所有行,直接编辑'即可。
行首插入内容:
1、1G 确保在首行
2、Ctrl + v 进入Visual Block选择模式
3、30G 选中所有行(你有多少行,可以set nu看一下)
4、Shift + i 输入'(英文状态)
5、ESC 及全部输入
行尾插入内容:
因为每行长短不一,那么怎么做呢?块模式选中行尾巴好像不好选择,所以:
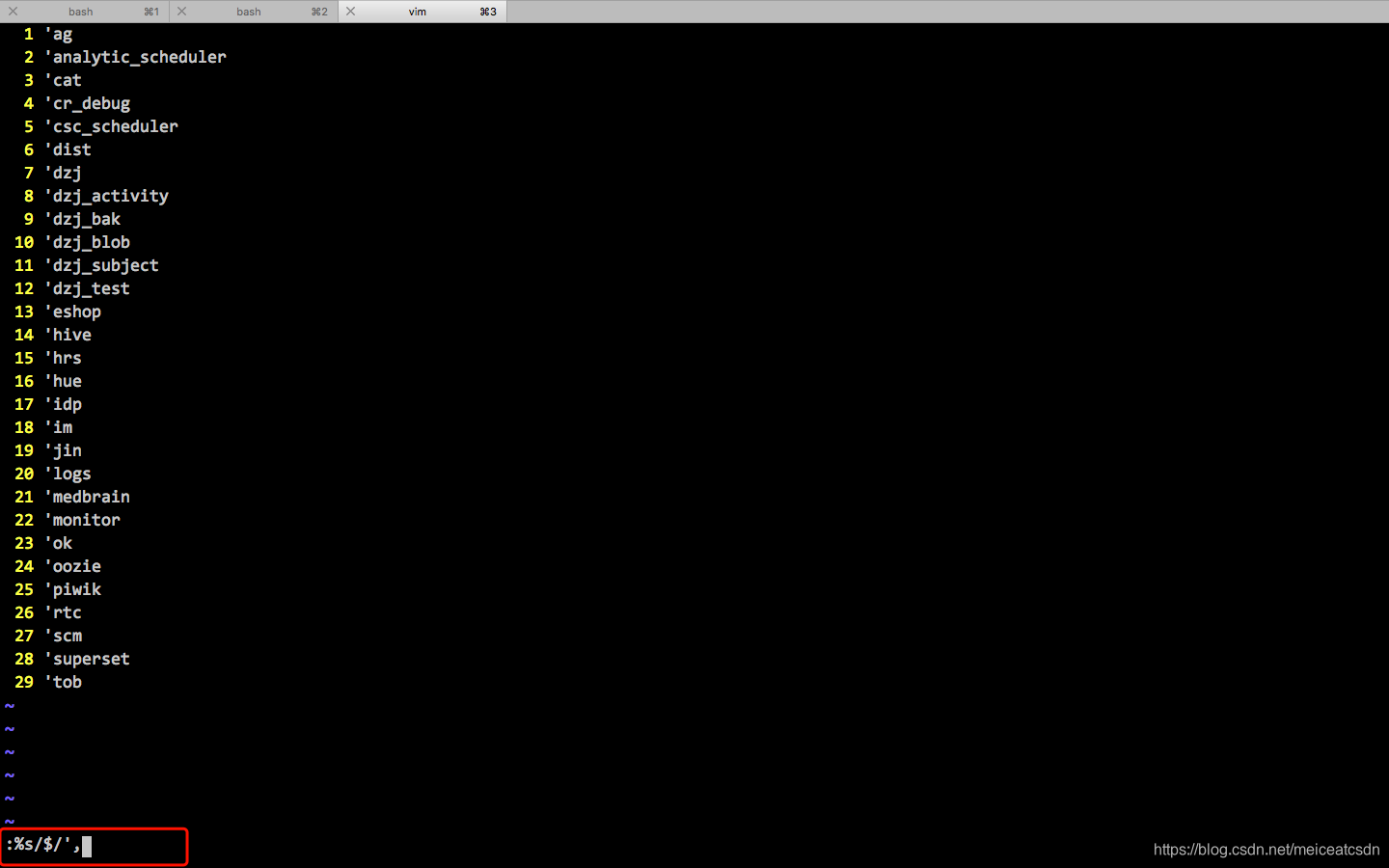
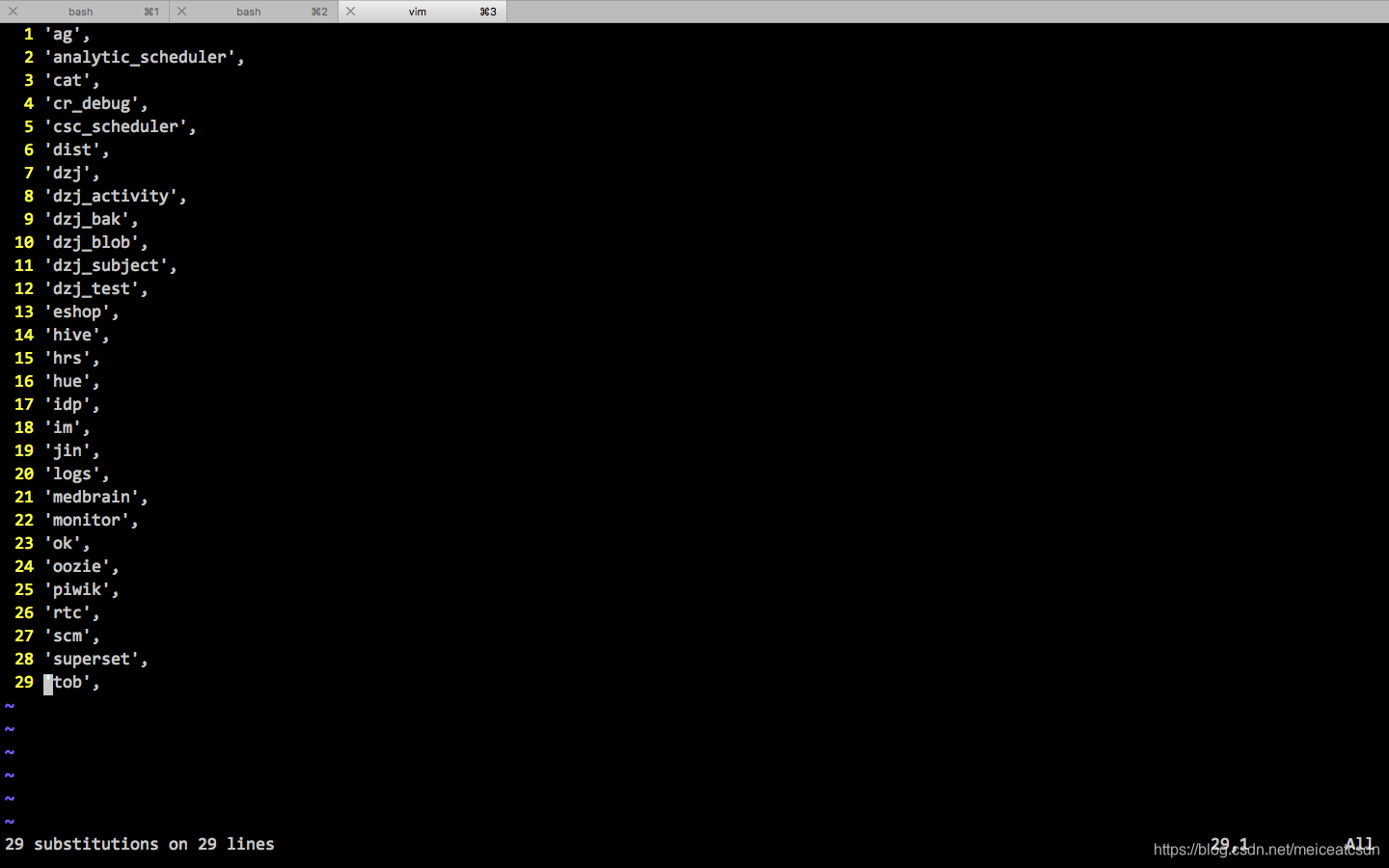
1、:%s/$/',
这一步操作就可以把行位都变成我们想要的。
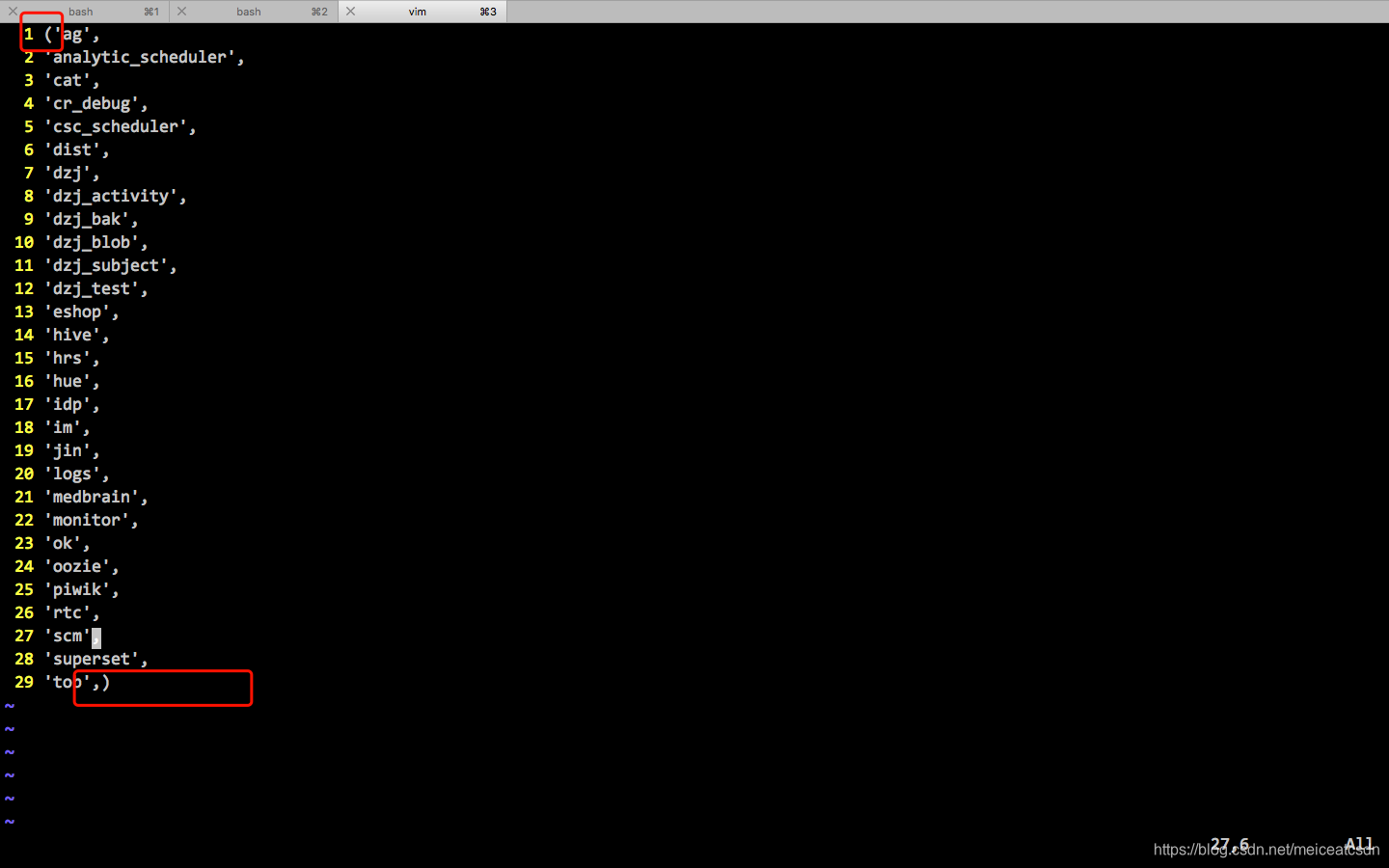
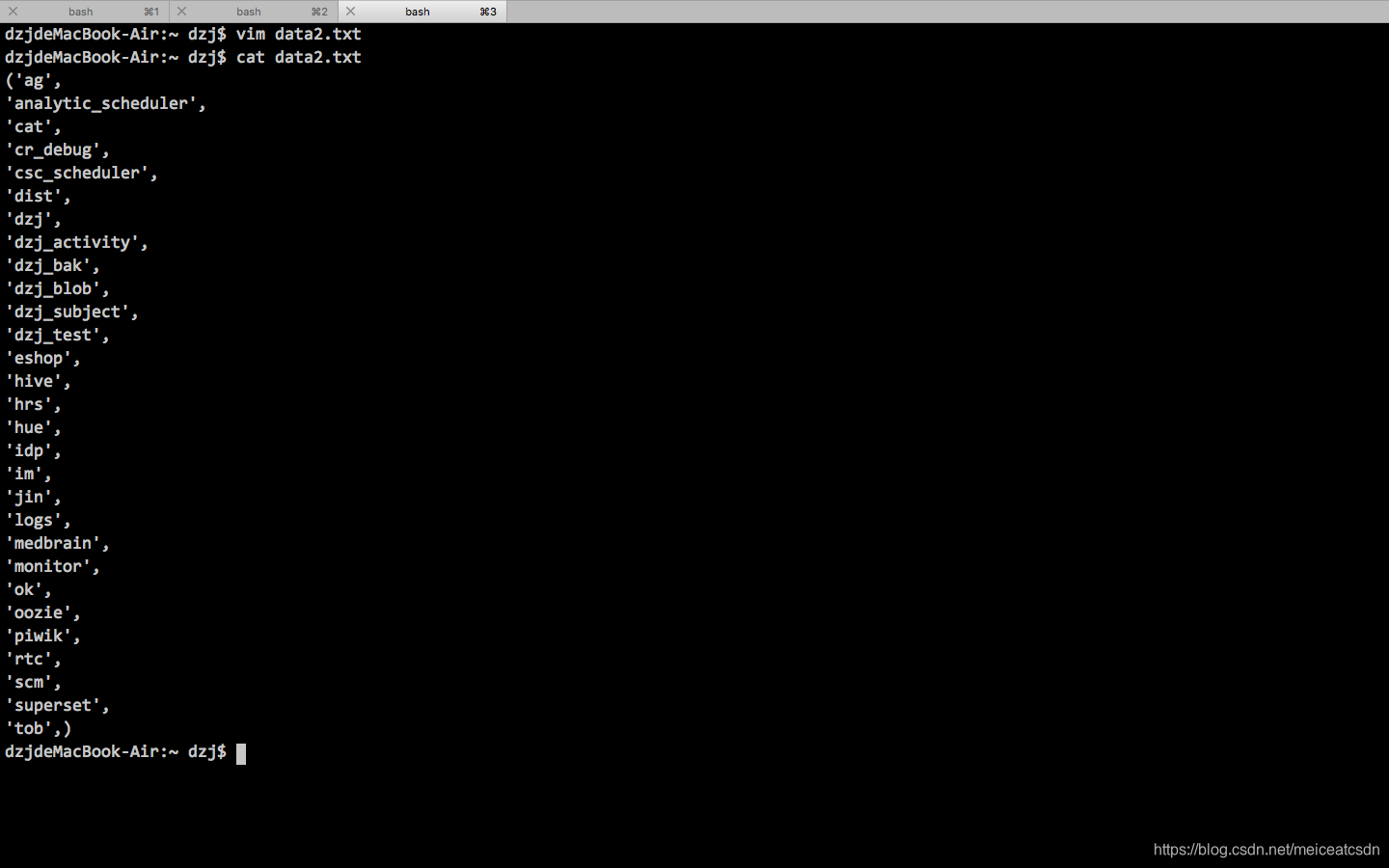
最后手动调整下首行、末行的()即可。
看下效果图:
三、优化
行首的替换也可以直接用替换符,操作更加简单。
块的方式编辑所有行首简单,因为行首都对齐着,但是编辑行尾就不好操作,行的长度不一致,用替换自然灵活。
:%s/^/'
四、总结
- show database;自然要剔除默认库;(mysql 2个schema sys)
当然统计分析要看每个库有多少表呢?group by 一下可以了,看下我的最终sql :
show databases;
SELECT
COUNT(0) as tableCount,
table_schema as db
FROM
information_schema.tables
WHERE
table_schema
IN
('ag',
'analytic_scheduler',
'cat',
'cr_debug',
'csc_scheduler',
'dist',
'idp',
'im',
'jin',
'logs',
'medbrain',
'monitor',
'ok',
'oozie',
'piwik',
'rtc',
'scm',
'superset',
'tob')
GROUP BY
table_schema;
小技能要活学活用,平时思考多,用起来顺手。平时功夫不到家,用的时候捉襟见肘,效率低还没提升。

















 2051
2051

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









