







论文题目-《基于图注意力卷积的点云语意分割》
引言
在本文中,作者提出了一个新的图注意力卷积模型用于点云语意的分割。
如下图是标准卷积和GAC的区别
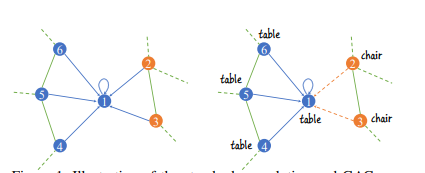
左图是标准卷积,其中每个节点的权重仅仅由邻居节点的空间位置决定,所以在学习特征的时候就很难去加以区分不同类别的邻居节点的属性。
右图是GAC,在GAC中由于注意力权重可以区分不同类别的属性,这样的话,我们就能够更加有目的性的去学习更加匹配的特征,就像图中一样在学习桌子特征的时候,我们就可以有意的让椅子的权重变小一些,就能学到更好的特征。
贡献:
1.提出了一个新的图注意力卷积用以学习一个动态的适应对象结构的卷积核。
2.提供了有关图注意力卷积的详细理论和经验分析。
3.训练了一个端到端的图注意力卷积网络用于点云语意分割,而且取得了很好地效果。
2.方法
提出了一个新的图注意力卷积GAC对于3D点云,构建了一个端到端的点云分割框架。
2.1图注意力卷积
图卷积分为2种,一种是基于谱域的图卷积,是运用傅里叶变换,和拉普拉斯矩阵,定义的图卷积。第二种是基于空间域的图卷积,这种图卷积就是人为的定义卷积核,然后在节点的邻居范围内进行卷积。本文用的就是第二种,直接针对节点的邻居节点进行图卷积操作,然后又在图卷积操作之中加入了注意力机制。即为GAC。
本文中:
给定一个点云集
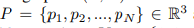
其中的p1,pn,就是坐标集。3维坐标。
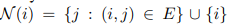
代表邻居节点。
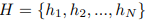
代表输入的特征,每一个特征有F维。
GAC的目的是去学习一个函数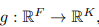
将输入的特征变成一个新的维度的特征。
然后作者构建了一个分享的注意力机制
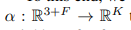
能够结合节点的坐标位置和节点的特征,以便能够动态的适应这个对象的结构。
每一个节点的注意力权重的计算如下:
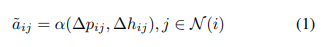
其中
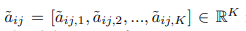
代表这个节点i和到节点j之间的注意力权重向量。∆pij = pj −pi,就是对应坐标相减。
∆hij = Mg(hj )−Mg(hi),就是对应特征的差值,其中,M代表一个多层感知机,把特征从F维变为K维。α 代表邻居节点之间的空间关系。最后,在本文中分享注意力机制被实现通过公式:
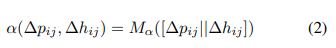
其中||是连接符号M是多层感知机。如图:
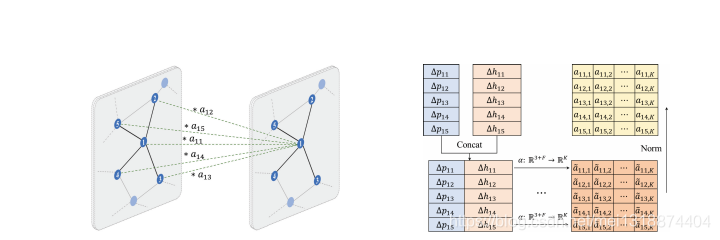
左边的就是针对点1得到的注意力权重向量,右边就是连接操作,通过计算坐标差和特征差,然后连接最后通过分享注意力机制,就是2个向连接,最后进行标准化,得到aij,k
标准化公式如下:
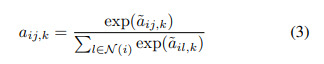
其中
aij,k就是节点i的第j个节点之间的第K个通道上的注意力权重向量。
所以,最后GAC输出的特征可以用以下公式表达:
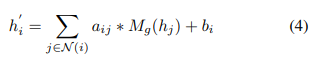
表示节点i的所有邻居节点的特征与权值向量的乘积。b是一个偏执向量。
,2.2图注意力网络
如图:
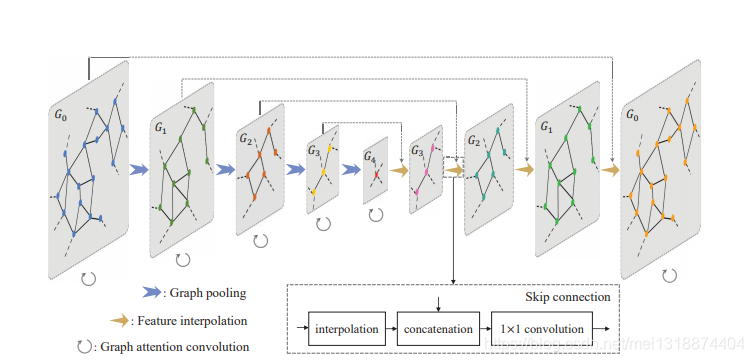
如上图的网络类似与金字塔,其中GAC用于特征的学习,然后使用图池操作降低每个要素通道中点云的分辨率。最后学习到的特征再被一层一层的还原回原来的维度。最后得到一个尺度和输入一样的特征图。然后通过大量的数据集就可以学习到点特征的标签,最后整个训练好的网络,就可以用以预测点云数据集,每个点的标签了。
图池化:图池化意在粗化图上输出聚合之后的特征。粗化图就会前面的精炼层,一层一层的,和下采样一样。公式表达如下:
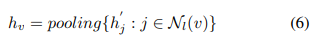
表示聚合邻居节点的特征。
特征插补:就是后面的反向金字塔结构,为了让最终得到的节点的数量和输入节点的数量相同,需要对特征进行插补。具体的插补方法是,在每一层,搜索节点的3个最近邻,然后计算他们的特征加权和,然后下一层插补的节点的值就共享这个特征。一层一层的插补,直到最后一层和输入的规模一样。
2.3 点云上的图金字塔结构的构造
本节介绍如何在点云上构造图金字塔。 具体来说,我们搜索空间所有点的邻居,并将它们链接为图。 通过交替应用图构造和粗化技术来构造具有不同空间比例的图金字塔结构。
点云上的图构造:对于给定的点云集合,规定每个点代表一个节点,节点的邻居就被添加边。确定邻居节点的方法是,对于一个节点在以值为半径的圆中随机选取一定数量的节点为邻居节点。
图粗话:图粗话类似于下采样,就是精炼特征。因为点云点很多,不可能全部卷积,就需要采样,通过最远点采样的方法,采取规定点的数量,然后用之前图构造的方法,取每个点一定半径之内的邻居节点,通过聚合函数,聚合范围内邻居节点的特征。就这样一层一层的精炼特征。
4.实验
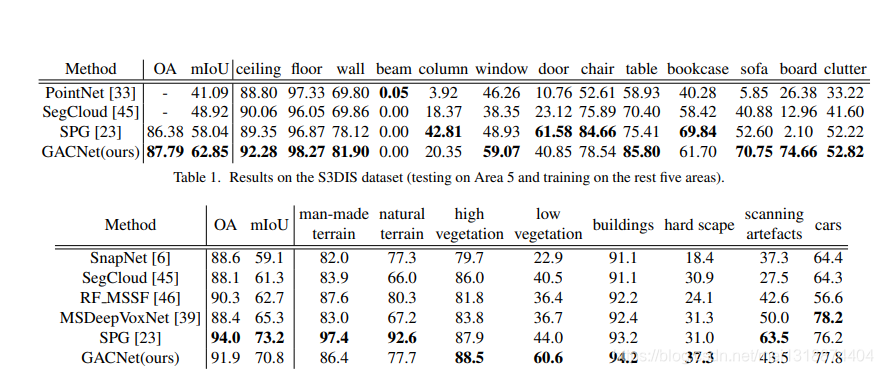
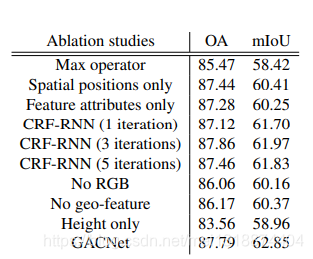

















 124
124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









