







 探讨了通过去噪自编码器的图神经网络生成分类权重的少样本学习方法,利用DAE处理少量数据,避免过拟合,通过图神经网络聚合节点信息,更新模型参数,增强分类权重的判别性。
探讨了通过去噪自编码器的图神经网络生成分类权重的少样本学习方法,利用DAE处理少量数据,避免过拟合,通过图神经网络聚合节点信息,更新模型参数,增强分类权重的判别性。
记录一下这周自己看的这篇文章。
文章标题《通过去噪自编码器的图神经网络生成分类权重的少样本学习》
1.Introduction
本文的主要思想是,训练一个模型,可以用已经训练好的元模型,就是在已有的训练好的模型上,在新的类来学习新的参数,去更新旧的参数,以便,使模型更加好。
基于DAE模型 参数的生成: 由于在本文中适用的meta-learning 过程中,我们去确定它的分类权重是需要大量的样本,加以学习才能够。但是现实之中,往往并不能够有那么多的数据可以用来使用。所以我们在本文中使用了Denoising Autoencoder network(DAE)来给输入的数据加入高斯噪声的操作得到一个新的数据,然后我们用新的数据来尽量去复现真实数据的分布。我个人的理解就是通过这种操作,可以在一些比如说样本比较少的情况下,加入高斯噪声,使其更加逼近于真实的数据。而且如果说在一个样本比较少的情况之下,过度训练就会导致过拟合的现象,所以如果输入数据进过噪声自编码器之后,也能很好的解决模型过拟合的情况。
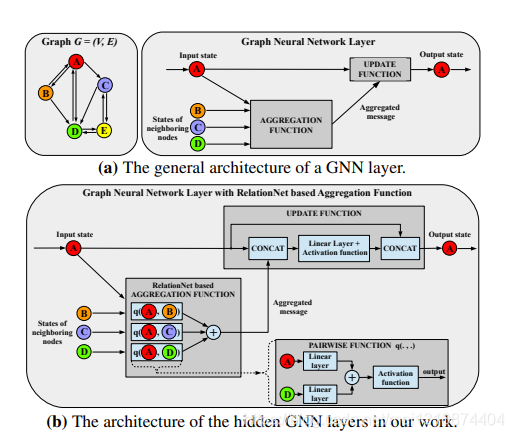
构建DAE模型参数作为图神经网络 :就是把经过DAE模型的数据,经过图神经网络,然后对其分类权重进行重构吧。图神经网络的作用是聚合邻居节点的信息,就是说,在整个图神经网络中的节点都聚合了相互邻居之间的关系,重新构建分类权重,重新更新模型参数。其实这个作者的意思就是说,当然其实我觉得看了很多图神经网络的论文之后啊,大致的道理都一样,作者的意思就是,比如说,我不同种类的鸟,不同种类的猫科动物,后者说不同种类的海洋动物,他们之间其实是有关系的,那么说我们在经过图神经网络之后,重新生成的分类向量就会更有判别性。如下图:

整合一下本文做出的贡献:
(1):利用了去噪自编码器在少量学习之中。
(2):使用图神经网络构建分类权重
(3):在目前有更好的效果嘛。
2.具体方法
符号定义:
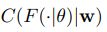
中有:
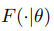
代表网络中的特征提取器,θ是参数。
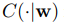
是特征分类器,w是参数。
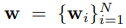
w是分类权重向量。由N个组成。
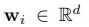
wi是指第i个类的d维的权重向量。
输入一个图片x给这个特征提取器,那么就会输出一个d维的特征z
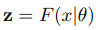
然后特征分类器就会计算其分类得分
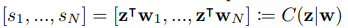
d维乘以d维所以可以相乘也说明为什么要变成d维,d维的特征乘以d维的分类权值向量。对于每一个类都有一个s得分。
然后,我们定义:
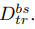
指:已知的数据集。
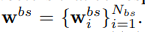
wbs代表已知数据集D的已知的数据参数。就是分类权值向量嘛。
本文的目标就是学习到一个函数g()来根据现在的参数和新增的参数一起来更新W,如下
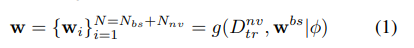
Dnv代表新的小样本,w代表已有的权重参数。最终生成新的w分类权值向量。
接下来关于DAE的知识。
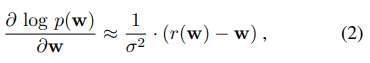
如公式,
公式二就相当于一个理论。
就是说:降噪之后的偏差向量可以近似额看成与w的密度分布函数的梯度一致。
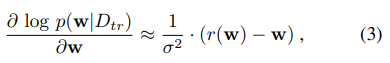
对于公式3的话,应用之前公式2的理论,我们把降噪之后的偏差向量近似的看成梯度,那么运用在本文中就有以上公式,
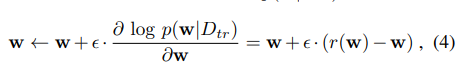
运用以上公式3的理论,带入到公式4,其实就是说,DAE的作用就是把一些比较少的样本,竭尽所能的还原到以前的样子,所以前面的一坨代表w的密度分布函数,那么说,我们只要让其密度函数趋于密度梯度大的地方,就代表其经过DAE之后的数据更加真实,所就有我们通过上述公式在调整参数的时候,我们就要让公式4的值更大,怎么做呢就是用梯度上升公式,也就是公式4,
以上就是根据梯度上升公式来调整w参数的过程。
然后就是初始化w了,因为训练w的话,总要有个初始值不是,初始化w的公式如下:
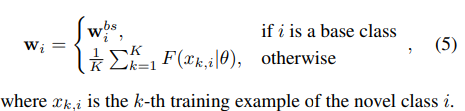
意思是如果样本是基础类的样本,那么说w就是原本的,如果不是,那么就是就是这个类里面的所有样本输入特征提取器之后得到的特征向量的平均值。
2.1然后是:Episodic training of classification weights DAE model
训练的目标函数是:
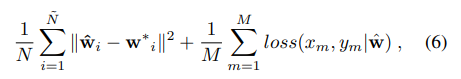
如何理解这个公式:
首先我们把原本的已知基础类数据集分为2个一个是假基础类数据集,一个是假的新类数据集,为什么要说是假的呢,是因为这两个数据集都来自与原本的数据集。这样做只是为了初始化一个w(一把)。所以上述公式的右边就代表我们用假数据集通过之前的模型训练出来的w(一把)和原本的w星的一个平方重建损失。
然后右边的意思是xm,ym。代表新的数据和新数据的标签,代表的是新的数据通过网络之后重建的w权重向量,就是新的数据和标签的二元交叉滴损失值。其中
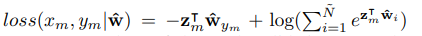
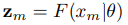
这个不难理解吧,就是一个二元交叉滴损失。你看前面一部分是新样本进入特征提取器得到的特征和已有的权重向量的积,就是前面说的分类得分嘛,右面一个是新样本的特征和我们图神经网络调整了的w权重向量,得到的是一个调整w之后得到的分类得分,所以两个相减就当做是损失呗。
到此为止就是所有DAE模型训练的过程了
之前我们只是大致的说明了过程,初始化w,然后经过DAE自编码器,然后得到重构的权重w,然后调整,达到损失最小化,如下图:
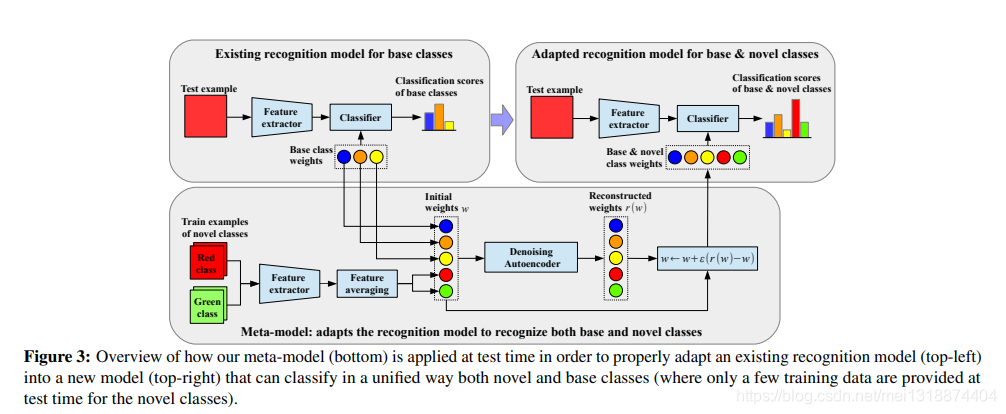
但是,我们要怎么去调整这个w呢。下面就是介绍具体的基于DAE的图神经网络内部如何调整参数了。
2.2. Graph Neural Network based Denoising Autoencoder
我们为了去重构他们的每一个分类的权重,所以我们现在要构建图模型。
V代表节点,E代表变。
然后我们把每一个类当做一个节点,然后边就带表其之间的关系。边连接的是它的10个相邻的邻居。aij代表两个节点之间的关系强度。一个节点的所有边的关系强度之和是1.。
然后看这个图神经网络的更新公式:
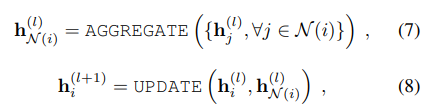
不难理解上述公式的意思就是聚合本层的节点特征信息。h代表节点的特征信息。然后更新下一层节点的信息。这只是伪公式,具体的公式如下:
aggregation function
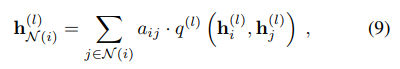
以上是聚合公式,aij代表节点之间的边的强度,也就是相似的强度嘛,其值通过计算两个邻居节点的余弦相似得分得到。然后后面的去q()函数的话,就是把两个节点的特征向量通过一个线性层,然后相加通过一个激活函数得到新的特征。
Update function:
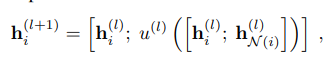
上诉为更新函数,中括号代表连接操作。u()代表一个非线性参数化函数。其输出是一个w,和o。如公式11.
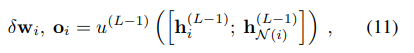
在两个特征向量h经过u()之后,会输出一个d维的向量,和一个经过sigmoid函数处理的0~1之间的数o。
然后公式11是用在最后图神经网络的预测层。意思就是在最后的层中h最后一层,然后用h层的特征,用上公式11,最后得到一个w和o。
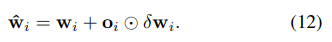
在得到了w,和o之后,o是一个门控单位,它的作用是能够去控制wi在接下来的调整中对整个w的影响,它的影响是通过各个节点的相关联的程度确定的,所以是通过了一个sigmoid函数,变成一个0~1的值,来影响结果。我们就可以用上公式12计算之前我们需要的w了。
整个DAE内部调整w过程如图:
在得到w之后我们就可以实现整个过程了。
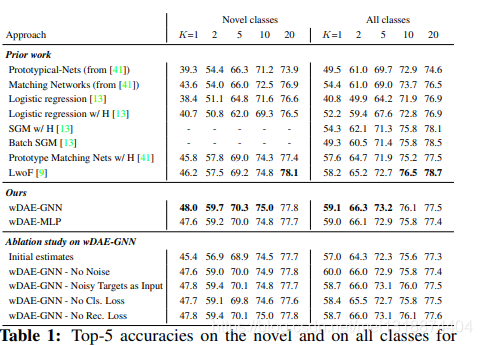
3.Experiments
最后的部分实验数据


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









