




 本文介绍了一种基于Scrapy框架的爬虫项目,目标是从Google Play抓取Android应用信息,适用于openthos系统。项目使用Python3.6、MongoDB3.6等技术,详细描述了从创建项目、编写爬虫代码到数据存储的全过程。
本文介绍了一种基于Scrapy框架的爬虫项目,目标是从Google Play抓取Android应用信息,适用于openthos系统。项目使用Python3.6、MongoDB3.6等技术,详细描述了从创建项目、编写爬虫代码到数据存储的全过程。
-
软件环境
ubuntu18.10
python3.6
mongodb3.6
scrapy 1.5.1
-
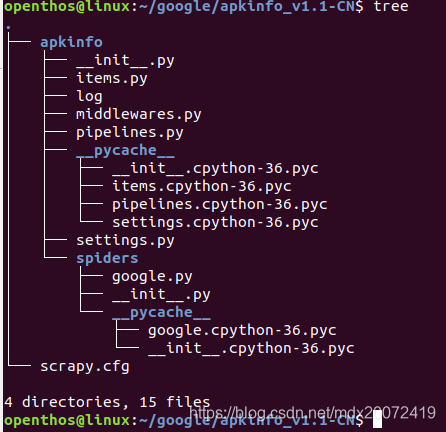
代码目录树如下:
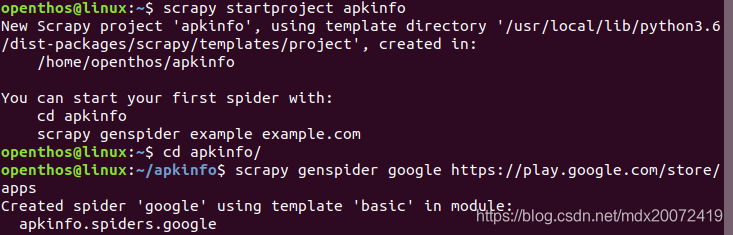
3、此项目是以apkpure.com为参照,以google play作为主站,基于scrapy框架来实现对匹配openthos系统的android应用信息抓取,因此在使用scrapy来创建项目时,基于的网址是https://play.google.com/store/apps,过程如下:
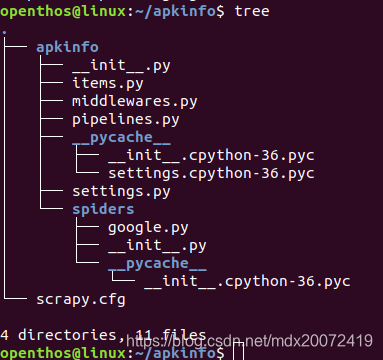
4、创建完工程,目录树如下:
在spiders文件夹下编写自己的爬虫
在items中编写容器用于存放爬取到的数据
在pipelines中对数据进行各种操作
在settings中进行项目的各种设置。
5、爬虫定义
在spiders文件夹下下存在goole.py ,内容修改为:

其中:
name : 爬虫的唯一标识符
allowed_domains: 爬虫域名
start_urls : 初始爬取的url列表
6、在google.py文件中存在parse()方法,是需要我们重写的方法 , 每个初始url访问后生成的Response对象作为唯一参数传给该方法,该方法解析返回的Response,提取数据,生成item,同时生成进一步要处理的url的request对象
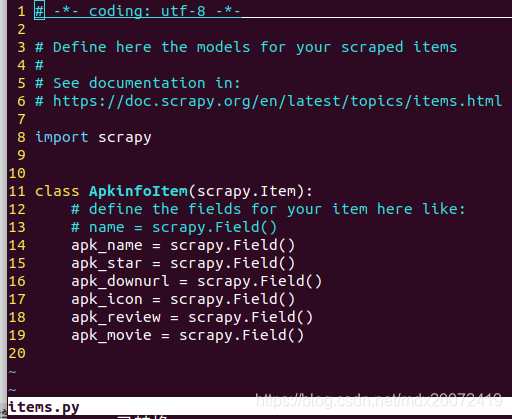
7、修改items.py,里面保存的是每个应用程序的具体信息:
8、编写google.py(spider)
(1)解析https://play.google.com/store/apps 页面,得到“查看更多”(see more)的地址
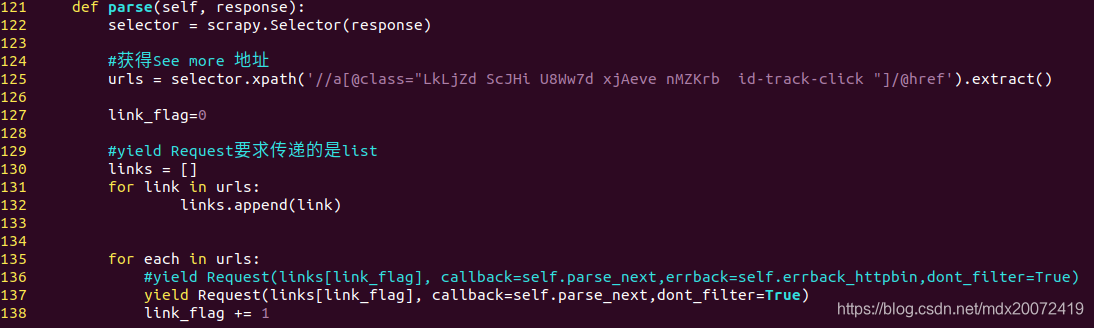
在第137行,使用yield迭代调用每个“查看更多”地址的页面,使用自定义函数parse_next处理
(2) 得到每个“查看更多”地址 页面上的每个应用程序的地址
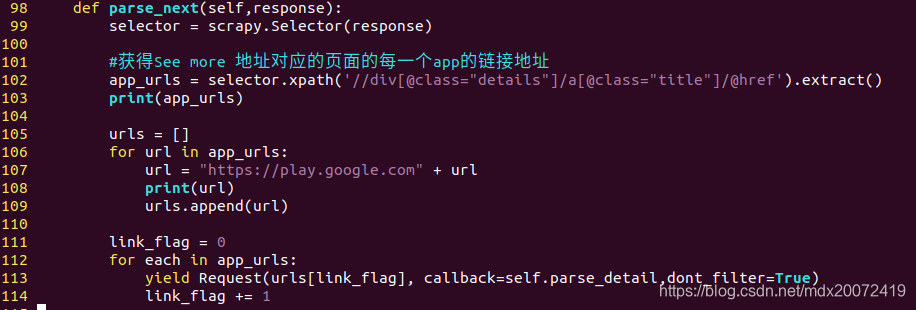
(3) 根据每个应用程序的地址, 调用函数parse_detail来解析每个应用程序的详细信息,并和每个item对应
9、修改pipelines.py,实现与数据库进行连接
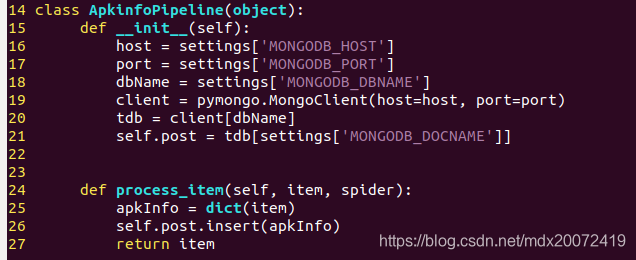
10、修改setting.py文件,注册pipeline
ITEM_PIPELINES = {
'apkinfo.pipelines.ApkinfoPipeline': 100 }
11、修改setting.py文件,防止谷歌反爬取
USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.96 Safari/537.36'
12、修改setting.py文件, 配置本地mongodb数据库
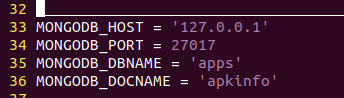
MONGODB_DBNAME = 'apps’ #数据库名
MONGODB_DOCNAME=‘apkinfo’ #表名
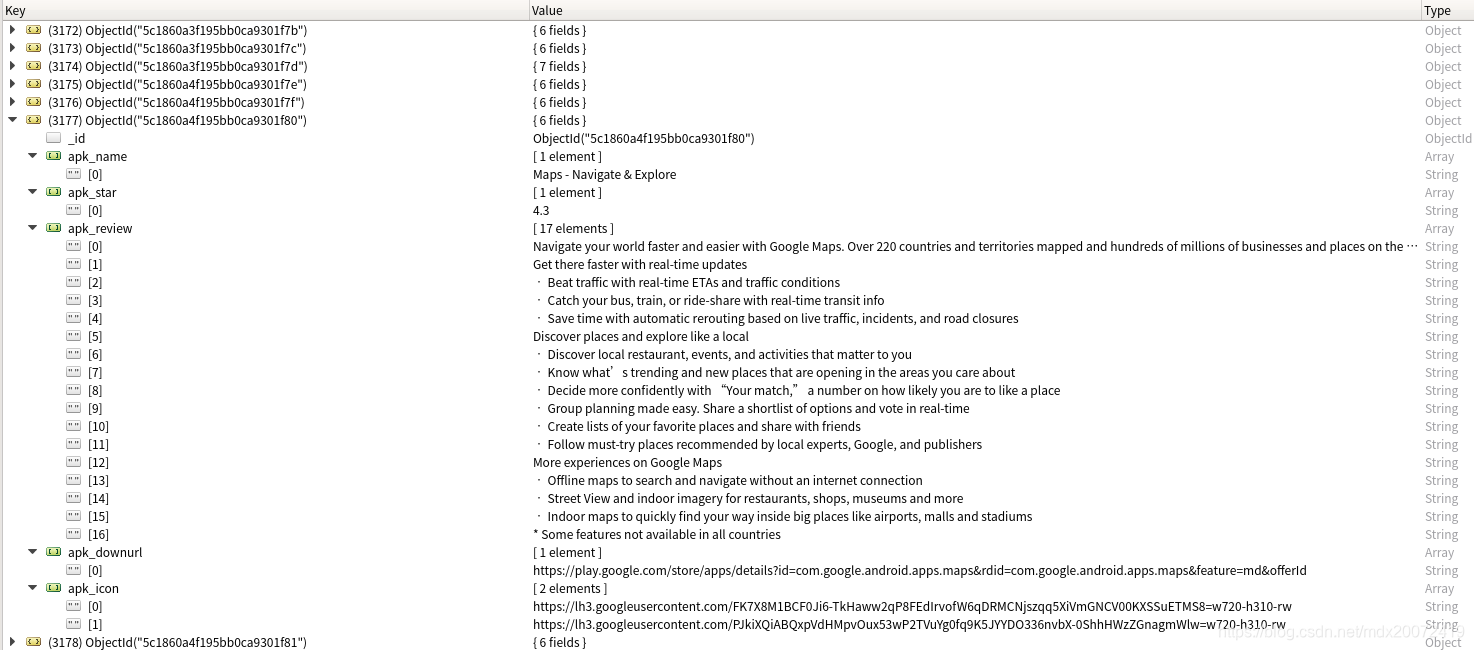
13、在apkinfo目录下运行 scrapy crawl google ,可以查看到一些打印信息,并且会在本地数据库中存储应用程序信息,在ubuntu上可以使用robomongo图形化查看mongodb中的信息,如下图:
注意:
-
此项目是使用python3版本进行开发运行,所以在运行此项目程序前,请确认您的python版本
-
开发此项目,需要安装多个第三方库,如果遇到“Python importError: No module named 'requests' 此类问题,请使用pip安装相应的库即可
-
开发前,请先对scrapy框架做一定的了解


















 722
722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









