




 本文介绍了无监督的关键词提取方法,包括TF-IDF的基本原理和改进,TextRank算法及其在关键词提取中的应用,以及LSA/LSI/LDA算法的概要。TF-IDF考虑词频和逆文档频率,TextRank基于PageRank,LSA/LSI/LDA则通过主题模型揭示词与文档的潜在关联。
本文介绍了无监督的关键词提取方法,包括TF-IDF的基本原理和改进,TextRank算法及其在关键词提取中的应用,以及LSA/LSI/LDA算法的概要。TF-IDF考虑词频和逆文档频率,TextRank基于PageRank,LSA/LSI/LDA则通过主题模型揭示词与文档的潜在关联。
NLP——关键词提取
文章目录
前言
关键词提取分为有监督和无监督两种方法:
- 有监督:通过分类的方式进行,通过构建一个较为丰富和完善的词表,然后判断每个文档与词表中每个词的匹配度,以类似打标签的方式达到关键词提取的效果。
优点:能够获得较高的精度;
缺点:需要人工建立和维护含有大批量标注数据的词表,人工成本过高 - 无监督方法:不需要人工生成和维护的词表,也不需要人工标准语料进行辅助训练,注意包括TF-IDF算法、TextRank算法、LSA/LSI/LDA算法、LSA/LSI算法、LDA算法等
一、TF-IDF算法
中文全称:词频–逆文档频词算法,是一种基于统计的计算方法,常用于评估一个词对于某分文档的重要程度。
1. 基本原理
主要包括两部分:
1)TF:统计一个词在一篇文档中出现的频词,出现的次数越多,其对文档的表达能力也就越强;
2)IDF:统计一个词在文档集中的多少个文档出现,如果一个词在文档集中出现的次数越少,则其对文档的表达能力也越强;
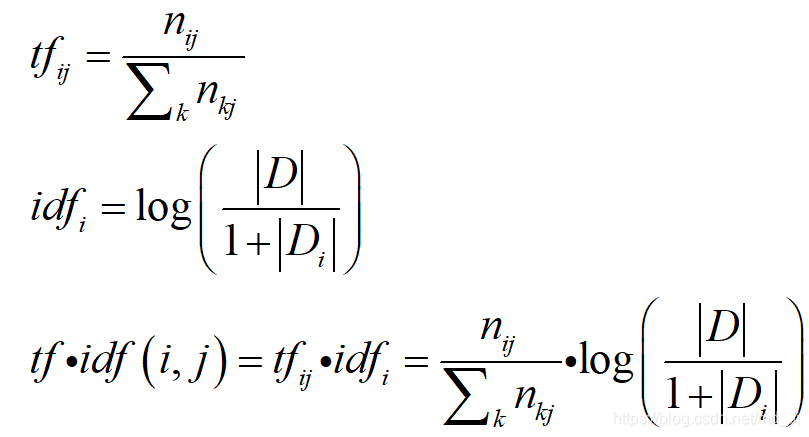
2. 算法改进
在传统的TF-IDF算法的基础上,有很多的加权变种方案:
1)加入词的词性作为一种加权因素,给特定词性的词(比如名词,一种定义现实实体的词,结果往往更加合理)更大的权重,在特定场景中,能够获得更好的效果;
2)考虑词在文档中所处的位置,例如文档的首尾段落,往往对于文章很重要(结合文章的结构),给首尾段落的词更大的权重,就能够更准确的提取出关键词;
二、TextRank算法
1. 基本原理
脱离语料库的背景,仅对单篇文档进行分析就可以提取该文档的关键词。
其基本思想来源于Google的pagerank算法。
2. PageRank算法
1)网页质量由两部分因素决定:
a:入链数量:从其他网页进入该网页的链接数量;
b:入链质量:进入该网页的各个网页链接的质量;
不考虑阻尼系数情况下,网页质量的计算公式:
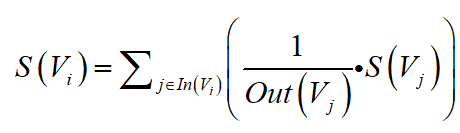
实际的计算过程:
先将各个网页的质量初始化为1,然后建立二维转移矩阵(各个网页之间的入链关系),通过网页质量向量的多次迭代,在网页质量向量不再发生变化之后(收敛之后),即得到各个网页的质量分数。
在迭代时会限制迭代次数,达到迭代次数之后,迭代停止,输出当时的网页质量分数向量作为迭代结果。
实际使用时可能遇到两个问题:
1)等级泄露:如果一个网页没有出链,多次迭代后,会使得其他网页的质量分数逼近0(相当于吸收了其他网页的分数);
2)等级沉默:如果一个网页没有入链,多次迭代后,自身的质量分数会逼近0(相当于散功);
解决方法:引入阻尼系数,对应的公式为:
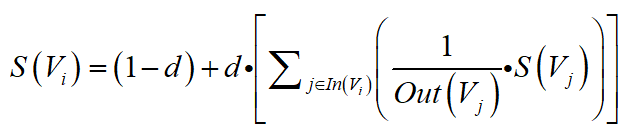
理解方法:现实中,对一个网页的访问不一定是从别的网页链接进入,也可能是直接输入网址访问,因此,这里添加阻尼系数,相当于是设定一个概率值,人们访问网页时,有多大可能是从别的网页链接进入的。
这样即使部分网页没有入链或者出链,也不会发生等级泄露或等级沉默。
3. TextRank算法
基本原理与PageRank类似。
但是应用在自动摘要场合,有一点不同:
PageRank在各个网页出入链接上是有向无权图,而TextRank算法则采用的是有权图,在对句子的重要性进行计分时,除了考虑连接句子的重要性之外还需要考虑两个句子之间的相似性(作为连接权重)。
每个句子对与它连接的其他句子的贡献不是平均分配的,而是根据他们之间各自的相似度,分别确定一个权重值来分配的,句子之间的相似度通常采用编辑距离和余弦相似度等来衡量。
在对一篇文档进行自动摘要时,默认每个语句与其他句子都是有连接关系的,也就是一个有向完全图。
对应的TextRank算法在自动文摘应用场景下的计算公式为:
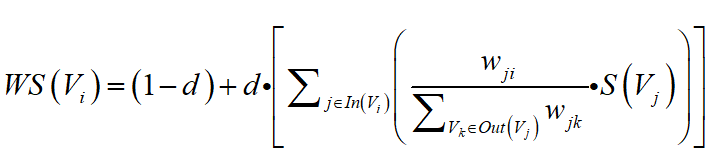
每个句子的重要性包括:
各个关联句子的重要性 * 本句与各个句子的相似度 / 本句与其他所有关联句子之间的相似度之和
4. TextRank算法在关键词提取的应用
与自动摘要应用时的区别:
1)词与词之间的关联没有权重;
2)每个词不是与文档中的所有词都有链接;
因此每个词仍然是将自己的重要性分数平均的分配给与自己关联的词,对应的重要性分数的计算公式与PageRank基本一致:
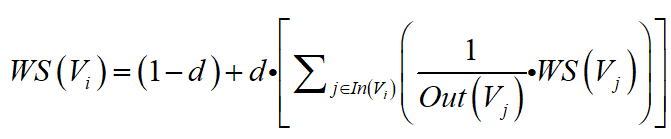
词与词之间链接关系的确定方法:
定义了窗口的概念,在文本经过分词之后,设定一个窗口大小(窗口中含有的词的数量),认为每个窗口中的词是有链接关系的。(一种上下文关系)
自动摘要中的句子之间的连接关系是通过句子之间的相似度来确定的,而各个句子之间必然会有一定的相似度,或大或小。因此,可以认为是文本中的每个句子之间,在这种情况下,都是有连接关系的,且连接关系之间是有权重(相似度的大小)的。
三、LSA/LSI/LDA算法
当文档的关键词没有显示的出现在文档中时,前面的TF-IDF算法和TextRank算法就不能够提取出重要的关键词信息,这时候就需要用到主题模型。
主题模型认为在词和文档之间没有直接的联系,他们应当还有一个维度将他们串联起来,这就是主题。

每个文档都对应着一个或多个主题,每个主题都会有对应的词分布,通过主题,就可以得到每个文档的词分布,一句上述原理,即可得到主题模型的核心公式: p ( w i ∣ d j ) = ∑ k = 1 K p ( w i ∣ t k ) ∗ p ( t k ∣ d j ) p(w_{i}|d_{j}) = \sum^K_{k=1} p(w_{i}|t_{k})*p(t_{k}|d_{j}) p(wi∣dj)=k=1∑Kp(wi∣tk)∗p(tk∣dj)
意义:第j篇文档中第i个词出现的频率 = 该文档中各个主题的频率 * 各个主题中该词出现的频率 再求和
1. LSA/LSI算法
采用奇异值分解(SVD)的方法进行暴力求解。
关于奇异值分解相关,非常清晰透彻的讲解文章
LSA(Latent Semantic Analysis):潜在语义分析
LSI(Latent Semantic Index):潜在语义索引:在LSA的基础上(对潜在语义进行分析之后),还会利用分析结果建立相应的索引。
LSA算法的主要步骤:
1)使用BOW模型将每个文档表示为向量;
2)将所有的文档词向量拼接起来构成词—文档矩阵(mn);
3)对词—文档矩阵进行奇异值分解(SVD)([mr] · [rr] · [rn]);
4)根据SVD分解的结果,将词—文档矩阵映射到一个更低的维度([mk] · [kk] · [k*n])(取前k个奇异值及其对应的奇异向量来表示原矩阵);
选取的前k个奇异向量就是k个主题,每个词和文档都可以表示为k个主题构成的多维空间中的一个点,通过计算每个词和文档的相似度(余弦相似度或KL相似度),可以得到每个文档中对每个词的相似度结果,相似度越高的词也就对文档越关键。
优点:
LSA通过奇异值分解(SVD)将词、文档映射到一个低维的语义空间,挖掘出词、文档的浅层语义信息,从而对词、文档进行更本质的表达。
缺点:
1)计算复杂度高,特征空间的维度较大时,计算效率很低下;
2)LSA得到的分布信息是基于已有数据集的,每次得到一个新的文档都需要对整个空间进行训练,以得到新文档对应的分布信息;
3)对词的频率分布不敏感,物理解释性稀薄;
2. LDA算法
LAtent Dirichlet Allocatio 隐含迪利克雷分布
基于贝叶斯理论,根据词的共现信息的分析,拟合出词—文档—主题的分布,进而将词、文本都映射到一个语义空间中。
前提假设:文档中主题的先验分布和主题中词的先验分布都是迪利克雷分布。
(先验分布+数据集(似然) = 后验分布)
核心方法:对已有数据集进行统计,得到每篇文档中主题的多项式分布和每个主题对应词的多项式分布。然后结合先验的迪利克雷分布和观测数据集得到的多项式分布,得到一组Dirichlet-multi共轭,并据此来推断文档中主题的后验分布和主题中词的后验分布。
LDA模型求解的一种主流方法就是吉布斯采样,主要的模型训练过程为:
1)随机初始化,对语料中每篇文档的每个词w,随机的赋予一个topic编号z
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2657
2657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









