







深度学习框架下的神经网络架构经历了从基础到复杂的显著进化,这一进程不仅推动了人工智能领域的突破性进展,还极大地影响了诸多行业应用。本文旨在深入浅出地揭示这一进化历程,探讨关键架构的创新点及其对现实世界的影响。
引言:神经网络的萌芽
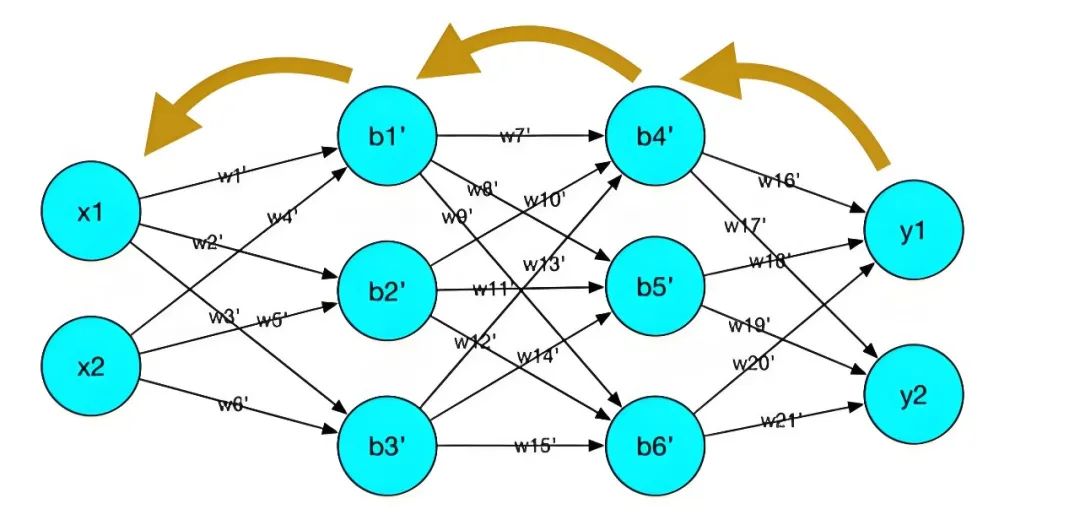
一切始于简单的感知机模型,这一概念在20世纪50年代末提出,标志着人工神经网络的雏形。尽管原始,但它奠定了神经元模型的基础——接收输入、加权求和并通过激活函数产生输出。随后的多层感知机(MLP)引入了隐藏层,让模型能够学习更复杂的特征表示,但直到有效的反向传播算法出现,多层网络才真正得以实用化。
深度网络的崛起
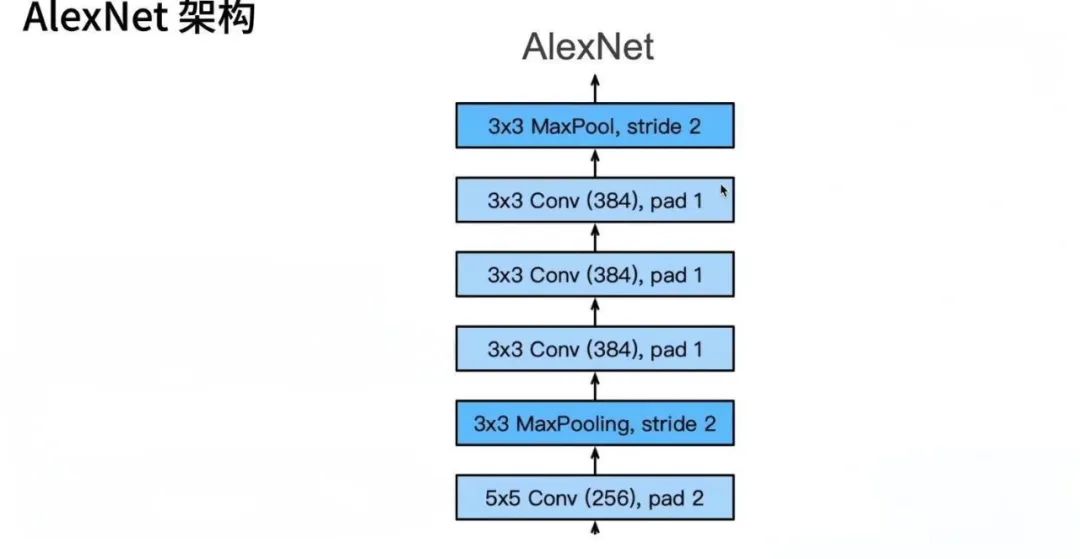
21世纪初,计算能力的飞跃和大数据的兴起为深度学习的发展铺平了道路。2006年,Geoffrey Hinton等人提出的深度信念网络(DBN)通过逐层预训练降低了深度网络训练的难度。随后,AlexNet在2012年的ImageNet竞赛中大放异彩,展示了深度卷积神经网络(CNN)在图像识别上的卓越性能,开启了深度学习的黄金时代。
卷积神经网络的革命
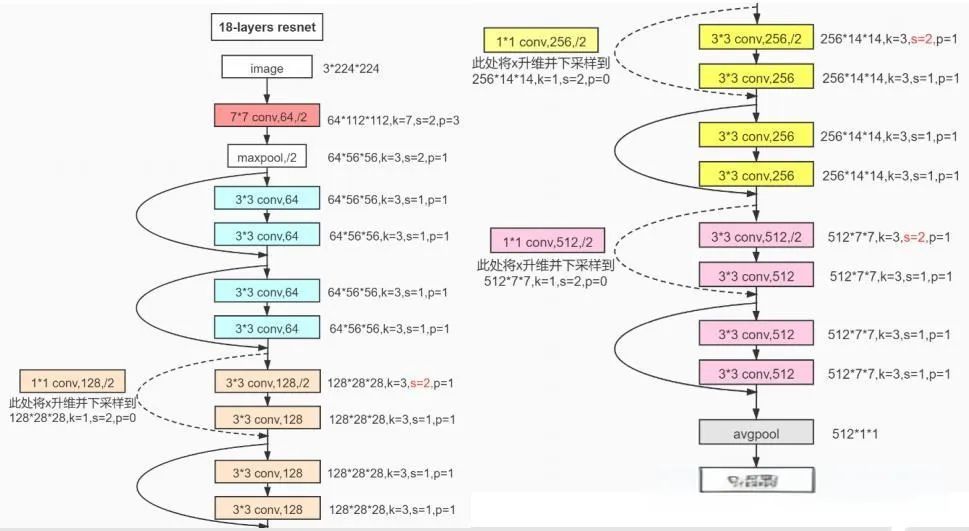
CNN通过局部连接、权值共享和池化操作,有效减少了参数量,提高了模型的泛化能力。VGGNet、GoogLeNet(Inception)、ResNet等模型进一步推动了CNN的发展,特别是残差学习的概念(ResNet),解决了深度网络训练中的梯度消失问题,使得网络可以轻易达到上百层。
循环神经网络的舞台
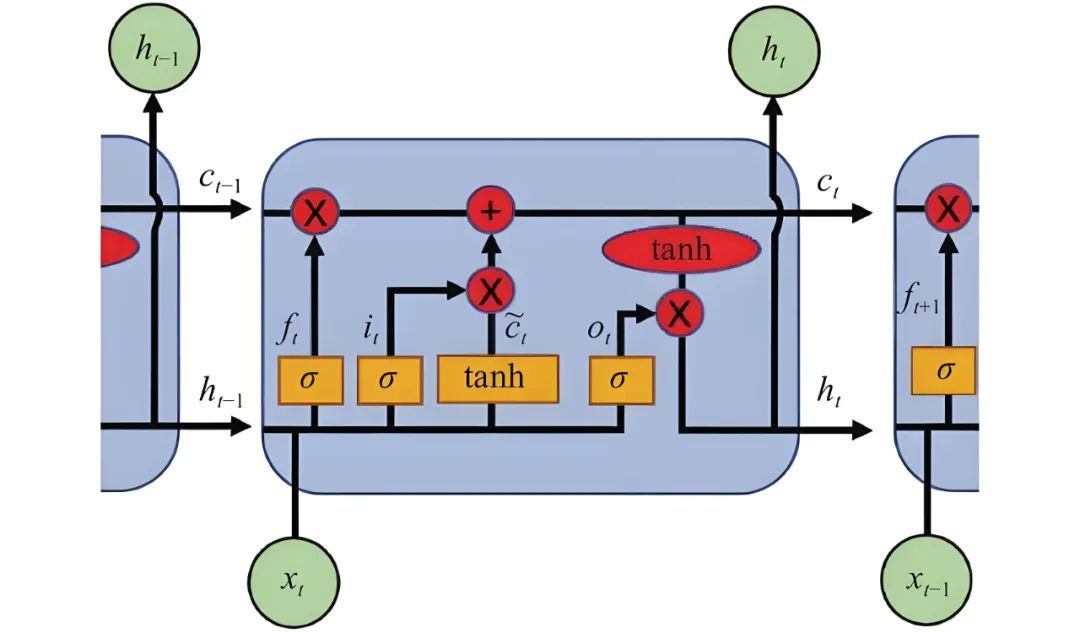
在序列数据处理领域,循环神经网络(RNN)因其记忆机制而显得尤为重要。但传统RNN面临长期依赖问题,直到长短时记忆网络(LSTM)和门控循环单元(GRU)的出现,通过门控机制有效地缓解了梯度消失和爆炸问题,极大提升了模型处理序列数据的能力。
迁移学习与预训练模型
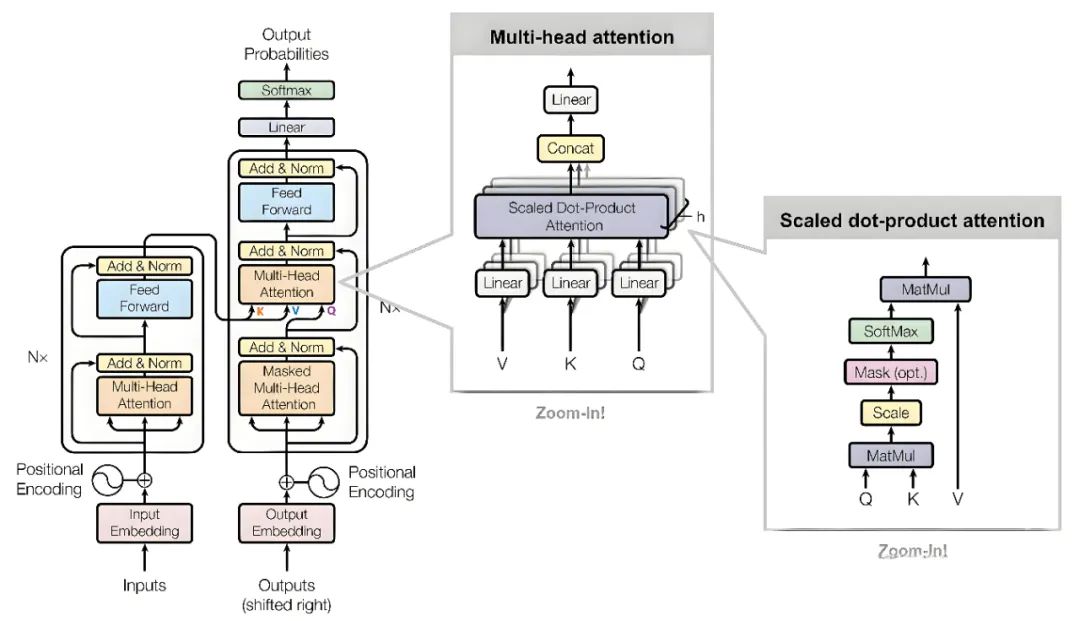
随着BERT、GPT系列等transformer架构的提出,自然语言处理领域迎来了变革。基于自注意力机制的Transformer模型摒弃了RNN的顺序处理限制,实现了并行计算,大幅提升了训练效率。预训练+微调的迁移学习策略,使得模型能够从大规模无监督文本中学习通用语言表示,进而应用于各种特定任务。
超大规模模型与未来展望
近年来,超大规模模型如Google的Switch Transformer、OpenAI的GPT-3以及阿里云的通义千问等,凭借其庞大的参数量展现了惊人的语言生成和理解能力。这些模型的训练往往需要大量计算资源和创新的优化策略,如模型并行、数据并行和混合精度计算等。
结语
深度学习框架下的神经网络架构从简至繁的进化,不仅仅是技术层面的进步,更是对人类认知智能深刻理解的体现。随着算法的不断创新和硬件设施的持续升级,未来的神经网络架构将更加灵活高效,有望在医疗健康、自动驾驶、智慧金融等众多领域发挥更加深远的影响。在这个过程中,如何平衡模型复杂度、计算成本与实际应用需求,将是持续探索的重要课题



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











