




科大讯飞AI大赛(多模态RAG方向)
夏令营:让AI读懂财报PDF(多模态RAG)
目前正在尝试在autodl平台上使用4090显卡,将原来baseline使用的fitz改进为MinerU,目前遇到了的错误:
ModuleNotFoundError: No module named ‘image_utils’
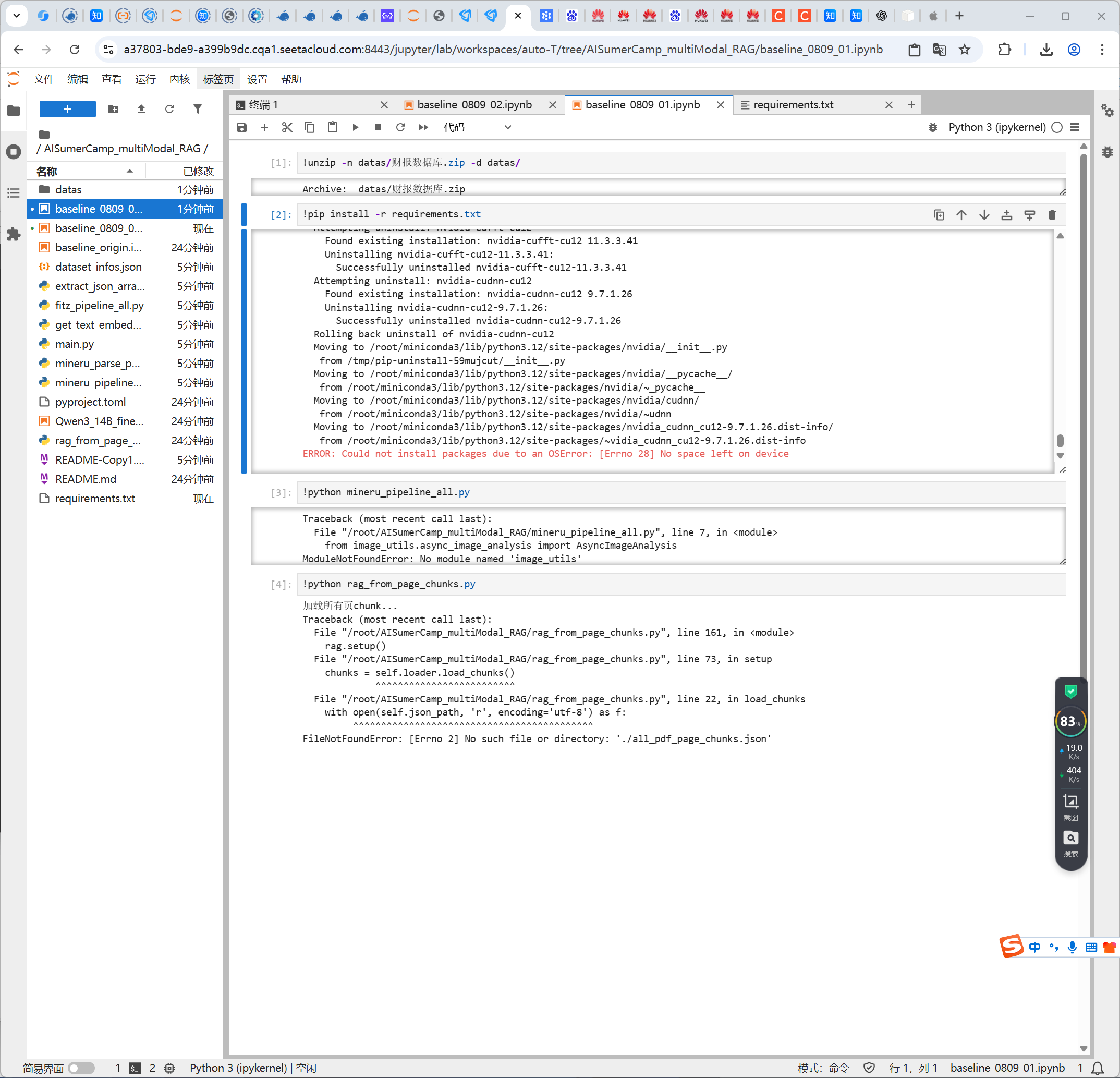
一开始以为是要安装image_utils包,结果安装后发现仍然缺少调用函数。
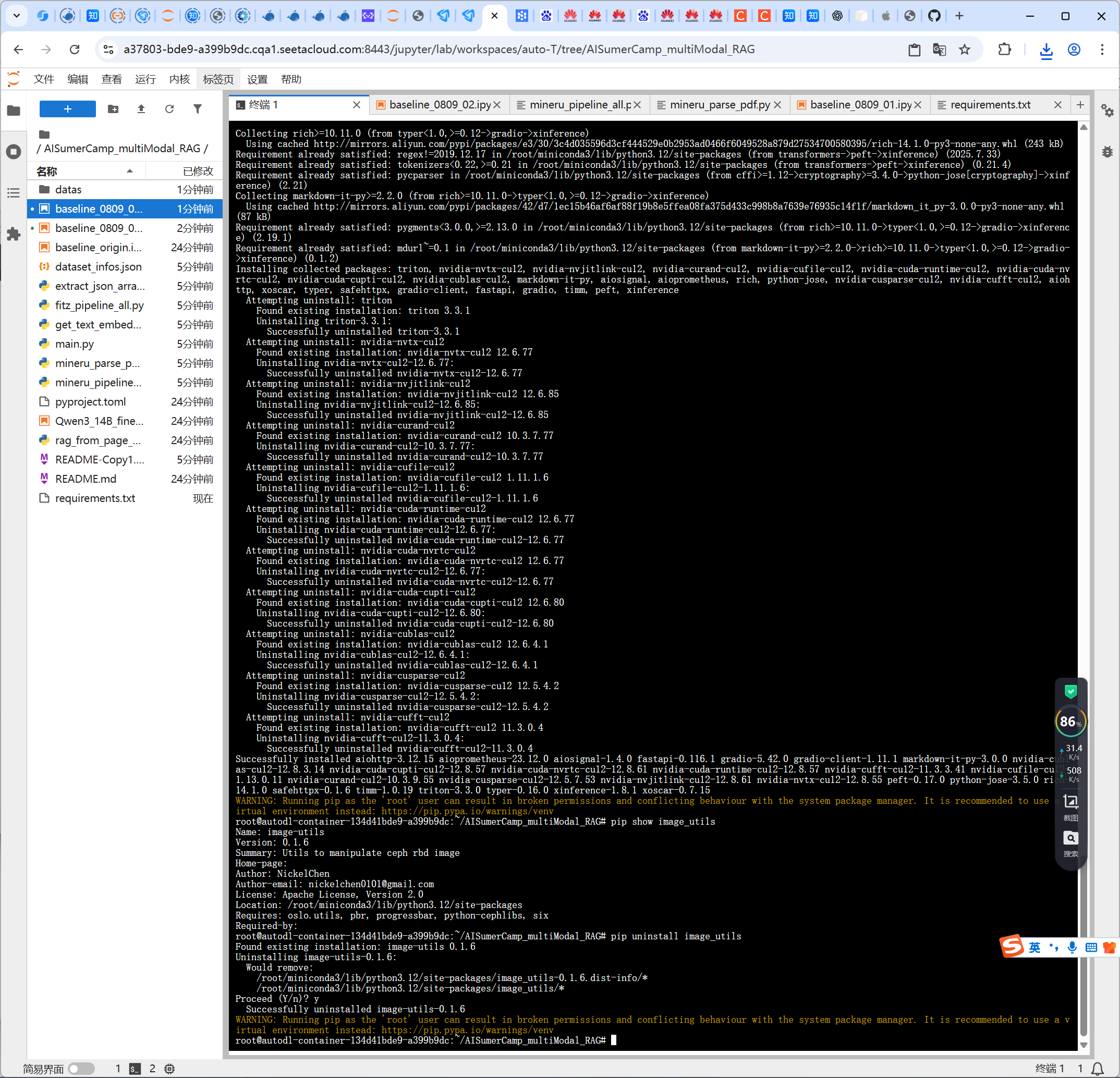
从开源仓库下载好正确的image_utils后,目前仍然在继续尝试中。
下面是教程:
copy from 侵删
💡
欢迎回到Datawhale AI夏令营第三期,多模态RAG 方向的学习~
我们将聚焦在「多模态RAG图文问答挑战赛」的赛事项目实践。
作为此次项目实践的最后一个Task,我们将—— 了解更多上分思路!
恭喜你已经完成了Baseline的跑通和赛题理解!这已经超越了80%的参赛者。
在跑通 Baseline 之后,相信我们已经对多模态RAG有了一个基本的认识和实践。
Baseline 方案提供了一个完整的流程,解决了从零到一的问题。接下来,我们要讨论的是如何在这个基础上做得更好。
在这个部分,我们将一起分析 Baseline 的局限性,从几个方面来考虑设计和优化RAG系统,学习三个核心的进阶方向:
使用 MinerU 实现高保真文档解析 :从源头上提升我们知识库的质量。
微调 Embedding 模型 :让我们的检索模块更懂金融领域的专业表达。
微调大语言模型 :训练一个更听话、更专业的问答生成器。
这部分内容会更有挑战性,但掌握了它们,你将能真正深入这个赛题的核心,并具备独立设计和优化高级RAG系统的能力。我们开始吧!
一、我们先回顾一下赛题任务
赛题背景
我们面对的不是干净的纯文本,而是信息量巨大、格式复杂的真实财报PDF。这些文件里文字、图表、表格交织在一起,传统的文本处理技术难以有效利用全部信息,因此需要引入多模态处理能力。
赛题目标
构建一个基于给定PDF知识库的、可溯源的多模态问答系统。简单来说,系统需要“读懂”这些图文混排的PDF,并能准确回答相关问题,同时必须明确指出答案来自哪个文件的哪一页。
评估标准
最终分数由三部分构成,总分为1分。这个评分机制强调了 答案准确性 和 来源可追溯性 并重:
答案内容相似度 (0.5分)
文件名匹配准确率 (0.25分)
页码匹配准确率 (0.25分)
数据集
我们手上有三份材料:
知识库 (财报数据库.zip) : 唯一的、封闭的信息来源,包含多个图文混排的PDF文件。
训练集 (train.json) : 提供“问题-答案-来源”的标注样本,用于系统开发和验证。
测试集 (test.json) : 只包含问题,是我们需要处理并提交结果的目标。
挑战与难点
多模态信息融合 :如何让系统理解文本与图表之间的关联。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 711
711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









