




 文章探讨了大模型LLM的长度外推性能,指出目前位置编码方法如RoPE的局限性。作者分析了预测时未训练位置编码和注意力机制处理超出训练长度的问题,并提出改进策略,包括寻找近邻位置旋转和数值放缩,展示了weave方法的初步有效性。
文章探讨了大模型LLM的长度外推性能,指出目前位置编码方法如RoPE的局限性。作者分析了预测时未训练位置编码和注意力机制处理超出训练长度的问题,并提出改进策略,包括寻找近邻位置旋转和数值放缩,展示了weave方法的初步有效性。
近期,随着大模型(LLM)的兴起,关于它的长度外推性质,也受到了业界的关注。关于外推,有一个美好的愿景,即,我们总是希望用更短的文本来训练LLM,但希望在推理时,LLM仍然可以处理更长的文本。如果这一假设成立,那将使得训练成本大幅降低,美哉!
然而,现实却很骨感。目前已知的良好属性的位置编码RoPE,也仅能达到10%-20%的外推长度(参考苏剑林老师的博客[1]中的论述)。在此,假设各位伙伴对于位置编码相关知识已经有了一定的基础,故不做详细阐释。
下图展示的是直接外推的表现[2](忽略alibi和T5):

从上图中可以看出,Rotary[3](即RoPE)尽管具有理论上良好的性质:长度衰减性。但仍然外推较差。
设计良好的位置编码方法,实际表现却差强人意,原因在哪里? 这是本文想重点讨论的问题。
我们首先看一些分析:在苏剑林博客中,将这一问题总结为两个方面[4]:
1是预测的时候用到了没训练过的位置编码(不管绝对的位置编码,还是相对的位置编码)。
2是预测的时候注意力机制所处理的token数量远超训练时的数量,导致了熵增,使得注意力分散。
乍一看,这似乎就是外推失败的原因了。然而,本文仍然希望进一步深入地探索。探索的目的,就是为了抓住它的本质,只有抓住了本质,我们才能更深刻的理解它,并且进行改进创新。
再来看一个结果[5]:

在上图中,左图是右图蓝色区域的局部放大。横坐标是距离,纵坐标是attention score。
可以看出,在模型的预训练的长度之内,即0-2048,attention score的值限定在了蓝色区域;当长度超出2048之后,attention score的值,出现了较大的波动。我们以上下文2k(即2048)长度的llama为例,做过测试的伙伴们,应该能发现,当输入长度在2k以内,llama能够正常输出;当输入长度超出2k之后,llama已经不能正常work了。
分析上述现象,我们当然可以用“2k长度之后,模型就没有见过了”这一通用原因来解释。但是,似乎并不够深入。
我们先看一下论文[5]的解释:
首先,该论文整理了attention score的计算公式:

整理上式:
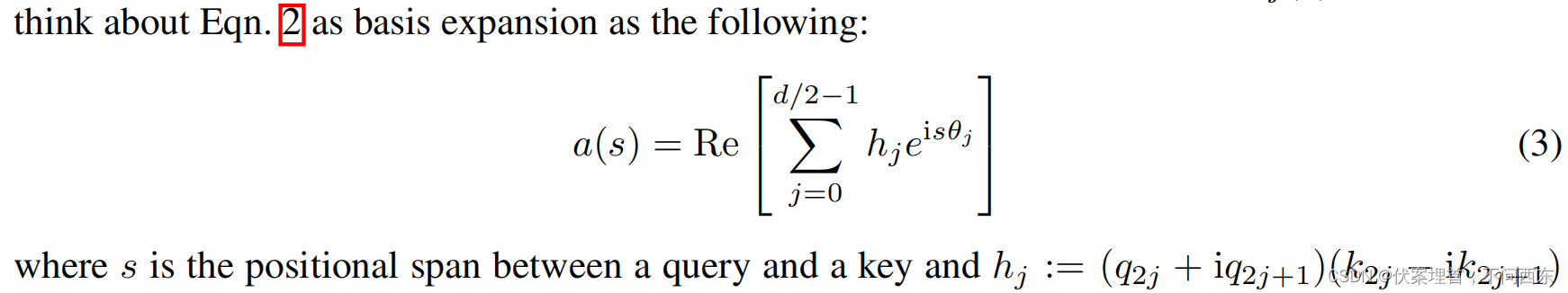
论文由此得出结论:

也就是说,在2k之内,有相关的q和k,使得a的值较小;当超出2k窗口,就会得到更大的值。
另外论文也补充了一点,RoPE提供的随着长度衰减理论证明中,给出的只是一个较高的理论上界。补充的这一点,就说明了理论和实际的gap。在此不再多说。
根据这篇论文,我们其实可以得到以下结论:
1.RoPE本身具有bound,但当位置与q,k不匹配时,导致了较大的attention score。
2.超出窗口的attention score仍然是被bound住的,但由于超出了有效范围,导致了外推的失败。
接下来,本文想继续分析。我们来看attention的作用原理:

从上图不难看出:
1.W^q, W^k是可学习的矩阵,通过反向传导,在训练过程中融合了位置信息和token信息。
2.单纯的Q和K是独立的,不带有位置信息。
3.最终位置信息融入到attention score矩阵中。
这就从侧面印证了,为什么处于[0, 2k]区间的,可以得到相关的q和k,使得attention score被bound住。
原因在于W^q 和 W^k学到了[0,2k]区间内的位置信息。
再进一步,我们可以得到下面的结论:
1.attention score 的有效范围是训练得来的。
2.人工设定(RoPE)和实际之间存在差距。
有了上面的分析,我们想要不经过finetune,就外推成功,那么不难猜测,就应该:
压制住attention score:
一种就是尽量找近邻的位置旋转,利用泛化性,让近邻位置能够使q,k相关起来;
一种就是数值上放缩,比如进行log的放缩,不至于数值超出了有效区域。
总的来说,核心就是使权重矩阵W^q 和 W^k, 能够和位置信息配合起来。
根据最后的推测,本人尝试设计了不经finetune的外推方法,不同于ReRoPE和NTK,暂且称其为weave,证明了它的有效性。具体方法将在后续章节中跟伙伴们做个分享与交流。
参考资料:
[1]https://kexue.fm/archives/9431
[2]TRAIN SHORT, TEST LONG: ATTENTION WITH LINEAR BIASES ENABLES INPUT LENGTH EXTRAPOLATION
[3]RoFormer: Enhanced Transformer with Rotary Position Embedding
[4]https://kexue.fm/archives/9431
[5]Extending Context Window of Large Language Models via Positional Interpolation


















 1358
1358




 到【灌水乐园】发言
到【灌水乐园】发言







