




概述
人脸识别技术作为深度学习在计算机视觉领域的重要分支,近年来在算法性能与实际应用中均取得了显著突破,已广泛渗透到安全防护、金融服务、智能终端等多元领域。模型的性能表现与环境鲁棒性作为决定其部署价值的核心指标,始终是研究与工程实践的焦点。AdaFace作为当前先进的人脸识别框架,创新性地引入自适应特征归一化(Adaptive Feature Normalization)机制,显著提升了模型对复杂场景的泛化能力,为解决实际应用中的挑战性问题提供了有效方案。
本系列文档系统整合并扩展了原有三篇教程的核心内容,以学术化视角构建了一套AdaFace模型从理论到实践的完整知识体系。全文遵循"数据-模型-部署"的技术链路,详细阐述从零开始构建与部署AdaFace模型的关键环节,包括数据集构建、模型训练、性能评估及工程化转换等全生命周期流程,并完整保留核心代码实现与可视化辅助材料,为读者提供兼具理论深度与实操价值的技术指南。
图像质量作为衡量视觉数据真实性与完整性的综合指标,其优劣直接取决于亮度均匀性、对比度范围、边缘锐度、噪声水平、色彩一致性、空间分辨率及色调还原度等多重因素。在人脸识别场景中,模型常需应对极端光照变化(如逆光、弱光)、多样姿态偏转(如侧颜、仰头)、动态表情干扰,以及年龄增长、妆容变化等跨时间维度的视觉差异。尤其在监控录像、无人机拍摄等实际应用场景中,低质量图像占比持续攀升(如图1所示),这类数据往往伴随模糊、遮挡、分辨率不足等问题,不仅增加了模型训练的难度,更对推理阶段的准确性构成严峻挑战。
本文将围绕AdaFace模型的工程化实践展开系统论述:首先介绍资源获取与数据集构建的标准化流程,包括数据清洗、增强与标注规范;其次深入解析模型训练的核心参数配置、损失函数设计及训练策略优化,并通过对比实验验证关键模块的有效性;随后详细阐述模型推理的实现逻辑,包括预处理 pipeline 与特征匹配算法;最后完整呈现模型从CKPT格式到ONNX格式的转换关键技术,以及转换后的精度验证方法。通过对各环节技术细节的学术化梳理与工程化验证,本文旨在为读者提供一个兼具系统性与可操作性的技术框架,助力理解并掌握AdaFace模型在实际场景中的应用落地。
AdaFace的官方代码库和相关论文是理解其核心原理和实现细节的重要资源。读者可以通过以下链接获取:

当图像质量较低时,识别任务变得难以预测。大量低质量图像会影响模型训练,导致模型在遇到低质量图像时,可能错误地关注非重点部分(如衣服、环境),从而影响训练成效。
贡献:
- 提出AdaFace损失函数: 根据样本图像质量,对不同难度的样本赋予不同权重。通过结合图像质量,避免强调难以识别的图像,专注于困难但可识别的样本。
- 学习梯度与样本难度相关: 实验表明,
angular margin的学习梯度与训练样本的难度相关。这促使作者通过自适应地改变angular margin来强调困难样本。如果图像质量较低,则忽略非常困难的样本(无法识别的图像)。 - Feature Norms代表图像质量: 证明了
feature norms可以代表图像质量,无需额外模块估计图像质量。因此,自适应angular margin无需额外复杂性。 - 广泛评估: 通过对9个不同质量数据集(LFW、CFP-FP、CPLFW、AgeDB、CALFW、IJB-B、IJB-C、IJB-S和TinyFace)的广泛评估,验证了该方法的有效性。实验表明,AdaFace在低质量数据集上的识别性能显著提高,同时保持高质量数据集上的性能。
1. 相关工作
基于Margin的损失函数
基于Margin的Softmax损失函数广泛应用于人脸识别训练中。引入Margin后,模型能学习到更好的类间和类内特征,提高可判别性。
Large-Margin Softmax Loss for Convolutional Neural Networks
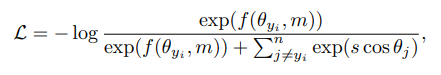
其中,θ为特征向量之间的夹角,ψ为GT(Ground Truth)的索引,m为Margin标量超参数。ψ是一个边际函数,SphereFace、CosFace和ArcFace可用以下三种不同Margin函数表达:
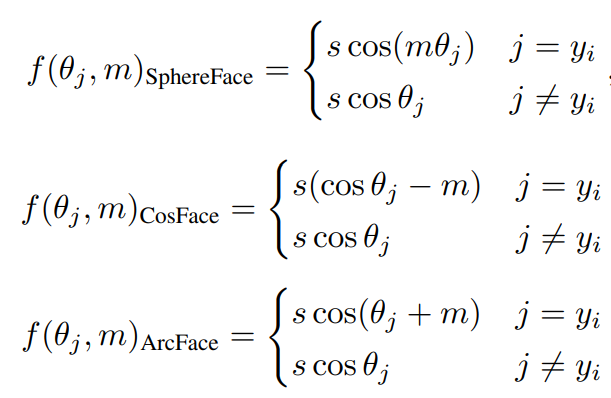
ArcFace被称为angular margin,CosFace被称为additive margin。
自适应损失函数
许多研究在训练目标中引入自适应机制,用于困难样本挖掘、训练期间的调度困难或寻找最优超参数。例如,CurricularFace将课程学习思想引入损失函数,在训练初期设置较小的Margin以学习简单样本,后期增加Margin以学习困难样本。CurricularFace中Margin的适应性基于训练进展。
AdaFace则认为Margin的适应性应基于图像质量。对于高质量图像,如果样本对模型而言很困难,网络应学习利用图像信息;但对于低质量图像,如果样本很困难,可能是因为缺乏适当信息,网络则不应学习相关特征。
MagFace探索了基于可识别性应用不同Margin的思想,对high norm features应用大角度Margin,使其更接近类别中心。但它未强调困难训练样本。DDL使用蒸馏损失最小化简单和困难样本特征之间的差距。
低质量图像人脸识别
近期FR模型在LFW、CFP-FP、CPLFW、AgeDB和CALFW等数据集上表现良好。然而,在监控、无人机或低质量视频等低质量数据集下,FR面临诸多问题。IJB-B、IJB-C和IJB-S等数据集中的图像质量普遍较低,有些甚至不包含足够身份信息,难以人工标注。这些无法识别的图像对训练过程有害,因为模型可能试图利用图像中其他视觉特征(如服装颜色或图像分辨率),从而影响训练。如果这些图像在低质量图像分布中占主导,模型在测试时可能表现不佳。
为确定图像质量感知,提出了概率方法预测FR表示中的不确定性。AdaFace是对传统Softmax损失的修改,易于使用。此外,AdaFace使用feature norms在质量感知融合过程中负责预测质量。
合成数据或数据增强可模拟低质量数据。有方法通过训练人脸属性标记器生成训练数据的伪标签。这些辅助步骤会使训练过程复杂化,难以推广。AdaFace方法仅涉及简单的裁剪、模糊和光照增强,适用于其他数据集。
2. 提出的方法
Margin形式与梯度
在反向传播过程中,由Margin引起的梯度变化会影响样本相对重要性。angular margin可在梯度中引入附加项,根据样本难度进行缩放。
Norm与图像质量
图像质量是一个综合性术语,涵盖亮度、对比度、锐度等特征。图像质量评估(IQA)在计算机视觉中广泛研究。SER-FIQ是一种用于人脸IQA的无监督DL方法。Brisque是一种流行的盲/无参考IQA算法。
然而,这些方法计算成本高。AdaFace不引入额外模块计算图像质量,而是使用feature norm作为图像质量的代表。作者观察到,在使用基于Margin的Softmax Loss训练的模型中,feature norm表现出与图像质量相关的趋势。
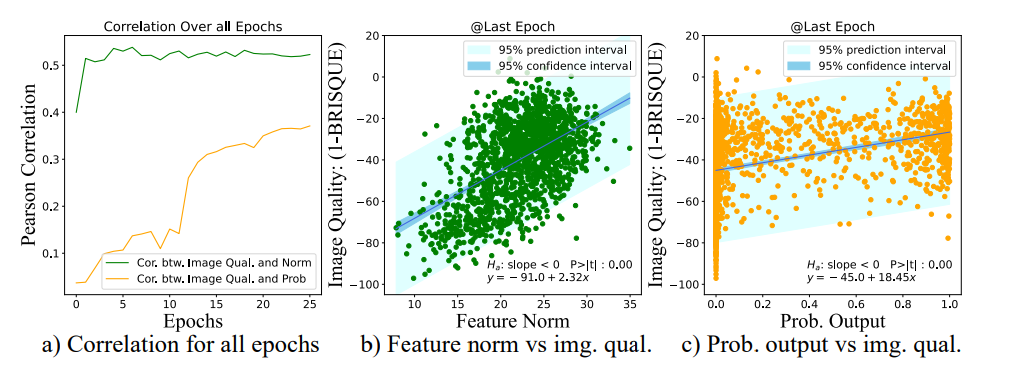
图a显示了feature norm与图像质量(1-brisque)之间的相关图。从MS1MV2数据集中随机抽取1534张图像,并使用预训练模型计算feature norm。在最后阶段,feature norm与IQ得分之间的相关性达到0.5235。对应的散点图如图b所示,feature norm和IQ得分之间的高相关性支持了使用feature norm作为图像质量的代表。
图a还展示了概率输出与IQ得分之间的相关图,feature norm的相关性总是高于概率输出。此外,feature norm与IQ得分之间的相关性在训练早期阶段就已显现,这对于将其作为图像质量指标很有用。
图c展示了图像质量与样本难度之间的散点图。样本难度和图像质量之间存在非线性关系。图中显示了样本难度的分布随图像质量的不同而不同。因此,在根据难度调整样本重要性时考虑图像质量是有意义的。
AdaFace: 基于Norm的自适应Margin
图像质量指标:
作为feature norm,是一个模型依赖数值,使用batch统计并进行归一化。
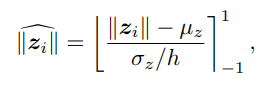
其中,µz和σz为一个batch内所有值的平均值和标准差。[](clip)表示在-1和1之间进行阈值处理,阻止梯度流动。由于将Batch分布近似为单位高斯分布,因此将该值限制在-1和1范围内,以便更好地处理。
已知大约68%的高斯分布落在-1和1之间,因此引入h来控制集中度。设置h,使大多数值落在-1和1之间。实现这一点的是h=0.33。
如果Batch size较小,Batch统计信息可能不稳定。因此,使用µz和σz跨多个步骤的指数移动平均数(EMA)来稳定Batch统计数据。
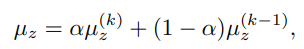
自适应Margin函数:
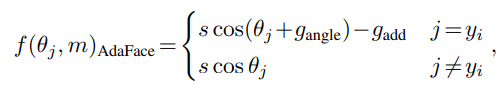
- 如果图像质量高,强调困难样本。
- 如果图像质量低,不强调困难样本。
3. 实验
高质量数据集与低质量数据集的结果:
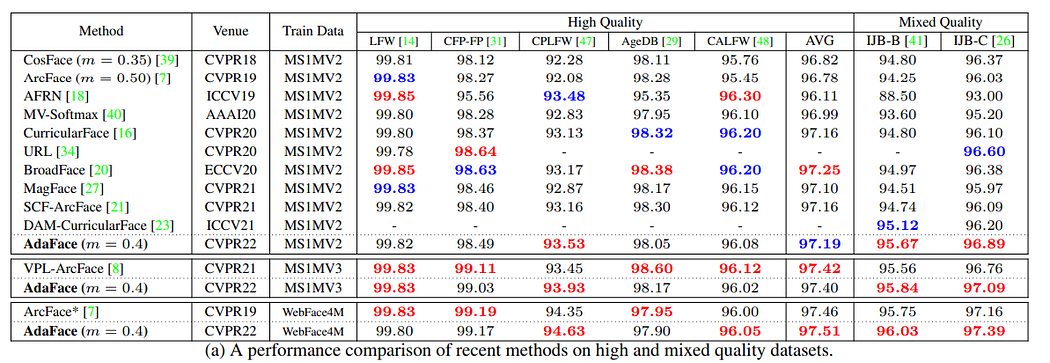
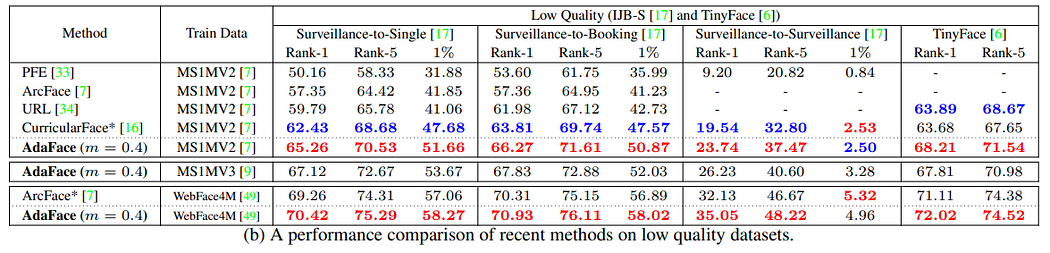
局限性:
本工作解决了训练数据中存在的无法识别图像的问题。然而,噪声标签也是大规模人脸训练数据集的突出特征之一。AdaFace损失函数对贴错标签的样本没有特殊处理。由于自适应损失赋予高质量的困难样本很大的重要性,高质量的错误标记图像可能会被错误地强调。未来可以同时适应不可识别性和标签噪声。
4. 资源下载与数据准备
本节将详细介绍AdaFace项目所需的资源下载以及大规模人脸识别数据集的制作过程。高质量的数据集是训练高性能模型的基石,因此,正确地获取和处理数据至关重要
4.1. 数据集下载
为了训练出具有强大泛化能力的人脸识别模型,通常需要使用大规模数据集。AdaFace项目推荐使用MS1M-ArcFace数据集(包含85K个身份和5.8M张图像)。该数据集的下载链接可以在InsightFace的GitHub仓库中找到:
- MS1M-ArcFace数据集下载链接:https://github.com/deepinsight/insightface/tree/master/recognition/datasets
该数据集的规模庞大,下载可能需要较长时间,请确保网络连接稳定并预留足够的存储空间。
4.2. 数据集制作与预处理
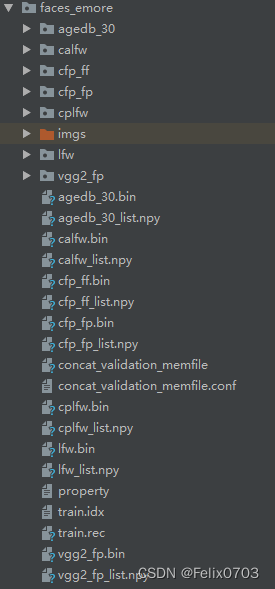
下载的原始数据集通常不能直接用于模型训练,需要进行一系列的预处理步骤,例如将train.rec文件中的图像提取出来,并生成对应的图像-标签映射文件。以下是用于数据集制作的Python脚本及其详细解析。
原始文档中提到,该脚本会将train.rec文件中的图片读取出来,并保存到指定文件夹中,同时生成图片和标签对应的txt文件。由于数据集庞大,此过程可能耗时较长,需要耐心等待。处理后的数据集将包含数百万张图像和数万个身份文件夹。
from pathlib import Path
import argparse
import mxnet as mx
from tqdm import tqdm
from PIL import Image
import bcolz
import pickle
import cv2
import numpy as np
from torchvision import transforms as trans
import os
import numbers
def save_rec_to_img_dir(rec_path, save_correct_channel_order=False, save_as_png=False):
save_path = rec_path/\"imgs\"
if not save_path.exists():
save_path.mkdir()
imgrec = mx.recordio.MXIndexedRecordIO(str(rec_path/\"train.idx\"), str(rec_path/\"train.rec\"), \"r\")
img_info = imgrec.read_idx(0)
header,_ = mx.recordio.unpack(img_info)
max_idx = int(header.label[0])
for idx in tqdm(range(1,max_idx)):
img_info = imgrec.read_idx(idx)
header, img = mx.recordio.unpack_img(img_info)
if not isinstance(header.label, numbers.Number):
label = int(header.label[0])
else:
label = int(header.label)
if save_correct_channel_order:
# this option saves the image in the right color.
# but the training code uses PIL (RGB)
# and validation code uses Cv2 (BGR)
# so we want to turn this off to deliberately swap the color channel order.
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
img = Image.fromarray(img)
label_path = save_path/str(label)
if not label_path.exists():
label_path.mkdir()
if save_as_png:
img_save_path = label_path/\"{}.png\".format(idx)
img.save(img_save_path)
else:
img_save_path = label_path/\"{}.jpg\".format(idx)
img.save(img_save_path, quality=95)
def load_bin(path, rootdir, image_size=[112,112]):
test_transform = trans.Compose([
trans.ToTensor(),
trans.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
if not rootdir.exists():
rootdir.mkdir()
bins, issame_list = pickle.load(open(path, \"rb\"), encoding=\'bytes\')
data = bcolz.fill([len(bins), 3, image_size[0], image_size[1]], dtype=np.float32, rootdir=rootdir, mode=\'w\')
for i in range(len(bins)):
_bin = bins[i]
img = mx.image.imdecode(_bin).asnumpy()
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
img = Image.fromarray(img.astype(np.uint8))
data[i, ...] = test_transform(img)
i += 1
if i % 1000 == 0:
print(\'loading bin\', i)
print(data.shape)
np.save(str(rootdir)+\'_list\', np.array(issame_list))
return data, issame_list
if __name__ == \'__main__\':
parser = argparse.ArgumentParser(description=\'for face verification\')
parser.add_argument("-r", "--rec_path", help="mxnet record file path", default=\'./faces_emore\', type=str)
args = parser.parse_args()
rec_path = Path(args.rec_path)
save_rec_to_img_dir(rec_path)
# bin_files = [\'agedb_30\', \'cfp_fp\', \'lfw\', \'calfw\', \'cfp_ff\', \'cplfw\', \'vgg2_fp\']
bin_files = list(filter(lambda x: os.path.splitext(x)[1] in [\'.bin\'], os.listdir(args.rec_path)))
bin_files = [i.split(\'\.\')[0] for i in bin_files]
for i in range(len(bin_files)):
load_bin(rec_path/(bin_files[i]+\'.bin\'), rec_path/bin_files[i])
脚本说明:
save_rec_to_img_dir函数:该函数负责从MXNet的.rec和.idx文件中读取图像数据,并将其保存为独立的图像文件(默认为JPG格式,也可选择PNG)。图像会根据其标签(ID)被组织到不同的子文件夹中。值得注意的是,原始图像通道顺序可能为RGB,但为了与后续训练流程兼容,通常需要转换为BGR格式,这通过cv2.cvtColor(img, cv2.COLOR_RGB2BGR)实现。load_bin函数:此函数用于处理验证集(如LFW, AgeDB-30等)的.bin文件。它将二进制数据加载为图像,并进行必要的预处理(如归一化和转换为PyTorch Tensor格式),最终保存为.npy文件,以便于模型评估。
运行上述脚本后,训练集图像将被提取到faces_emore/imgs目录下,并按类别(人脸ID)组织。同时,验证集数据将转换为.npy格式,用于模型测试。生成的.npy文件是测试集使用的数据集,而train.rec文件是真正的训练数据。
重要提示:在处理图像时,需要特别注意图像的通道顺序。原始rec文件读取的图像可能是RGB格式,但在某些深度学习框架中,例如使用OpenCV进行图像处理时,通常默认使用BGR格式。因此,在将图像送入模型训练之前,务必进行正确的通道转换,即img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR),以避免潜在的兼容性问题和训练效果下降。
5. 模型训练与测试
本节将详细阐述AdaFace模型的训练过程和性能测试方法。成功的模型训练是获得高性能人脸识别系统的核心,而有效的测试则能验证模型的实际能力。
5.1. 训练环境配置
在开始训练之前,需要配置好训练环境和模型参数。AdaFace项目通常使用PyTorch框架进行开发,并依赖于一些常见的深度学习库。以下是config.py文件中关键参数的解析,这些参数直接影响模型的训练行为和性能。
parent_parser = argparse.ArgumentParser(add_help=False)
#数据集路径
parent_parser.add_argument(\'--data_root\', type=str, default=\'\')
#训练数据集的路径
parent_parser.add_argument(\'--train_data_path\', type=str, default=\'faces_emore/imgs\')
#验证集的路径
parent_parser.add_argument(\'--val_data_path\', type=str, default=\'faces_emore\')
#训练数据集
parent_parser.add_argument(\'--train_data_subset\', action=\'store_true\')
parent_parser.add_argument(\'--prefix\', type=str, default=\'default\')
#使用多少个gpu进行训练
parent_parser.add_argument(\'--gpus\', type=int, default=1, help=\'how many gpus\')
#用多卡多机进行训练
parent_parser.add_argument(\'--distributed_backend\', type=str, default=\'ddp\', choices=(\'dp\', \'ddp\', \'ddp2\'),)
parent_parser.add_argument(\'--use_16bit\', action=\'store_true\', help=\'if true uses 16 bit precision\')
#训练的一个总epoch
parent_parser.add_argument(\'--epochs\', default=26, type=int, metavar=\'N\', help=\'number of total epochs to run\')
parent_parser.add_argument(\'--seed\', type=int, default=42, help=\'seed for initializing training.\')
#训练一个epoch所用到的图片,这里面是指一共训练的多少张图片,如果用多卡的话,就要一张卡可以训练的图片数量乘以几张卡。
#例如两张卡的话,一张卡能训256张图,两张卡就是2*256=512,那么下面就填512。
parent_parser.add_argument(\'--batch_size\', default=256, type=int,
help=\'mini-batch size (default: 256), this is the total \'
\'batch size of all GPUs on the current node when \'
\'using Data Parallel or Distributed Data Parallel\')
#学习率
parent_parser.add_argument(\'--lr\',help=\'learning rate\',default=0.002, type=float)
#在epoch=12、20、24的时候进行一个学习率的下降
parent_parser.add_argument(\'--lr_milestones\', default=\'12,20,24\', type=str, help=\'epochs for reducing LR\')
parent_parser.add_argument(\'--lr_gamma\', default=0.1, type=float, help=\'multiply when reducing LR\')
#线程数量
parent_parser.add_argument(\'--num_workers\', default=36, type=int)
parent_parser.add_argument(\'--fast_dev_run\', dest=\'fast_dev_run\', action=\'store_true\')
parent_parser.add_argument(\'--evaluate\', action=\'store_true\', help=\'use with start_from_model_statedict\')
parent_parser.add_argument(\'--resume_from_checkpoint\', type=str, default=\'\')
parent_parser.add_argument(\'--start_from_model_statedict\', type=str, default=\'\')
#使用ir_18作为主干网络
parser.add_argument(\'--arch\', default=\'ir_18\')
parser.add_argument(\'--momentum\', default=0.9, type=float, metavar=\'M\')
parser.add_argument(\'--weight_decay\', default=1e-4, type=float)
parser.add_argument(\'--head\', default=\'adaface\', type=str, choices=(\'adaface\'))
parser.add_argument(\'--m\', default=0.4, type=float)
parser.add_argument(\'--h\', default=0.333, type=float)
parser.add_argument(\'--s\', type=float, default=64.0)
parser.add_argument(\'--t_alpha\', default=0.01, type=float)
parser.add_argument(\'--low_res_augmentation_prob\', default=0.2, type=float)
parser.add_argument(\'--crop_augmentation_prob\', default=0.2, type=float)
parser.add_argument(\'--photometric_augmentation_prob\', default=0.2, type=float)
parser.add_argument(\'--accumulate_grad_batches\', type=int, default=1)
parser.add_argument(\'--test_run\', action=\'store_true\')
parser.add_argument(\'--save_all_models\', action=\'store_true\')
关键参数说明:
--data_root:数据集的根目录。--train_data_path:训练数据集的相对路径,通常指向预处理后的图像文件夹(例如faces_emore/imgs)。--val_data_path:验证集的相对路径。--gpus:用于训练的GPU数量。支持单卡和多卡训练。--distributed_backend:分布式训练的后端,如ddp(DistributedDataParallel)。--use_16bit:是否使用16位浮点精度(FP16)进行训练,可以加速训练并减少显存占用。--epochs:总的训练轮次(epoch)数量。--batch_size:每个GPU的批处理大小。在多卡训练时,总批处理大小是batch_size乘以GPU数量。--lr:初始学习率。--lr_milestones:学习率衰减的里程碑(epoch),例如在12、20、24个epoch时降低学习率。--lr_gamma:学习率衰减的乘数,例如0.1表示学习率变为原来的1/10。--num_workers:数据加载的线程数量,影响数据加载效率。--arch:主干网络的架构,例如ir_18(ResNet-18的变体)。--head:损失函数的类型,这里是adaface。--m,--h,--s,--t_alpha:AdaFace损失函数特有的参数,用于控制特征归一化和角度裕度。--low_res_augmentation_prob,--crop_augmentation_prob,--photometric_augmentation_prob:数据增强的概率,用于提高模型的鲁棒性。
5.2. 模型训练过程
配置好参数后,可以通过运行main.py脚本来启动模型训练。训练过程会根据配置的GPU数量和分布式后端进行。训练过程中会周期性地保存模型检查点(checkpoint)。

训练成功时,控制台会显示相应的训练日志和进度。模型检查点通常保存在experiments目录下。默认情况下,系统可能只保存性能最好的模型,如果需要保存所有epoch的模型,需要修改相应的代码配置。


5.3. 模型测试与推理
模型训练完成后,需要对其性能进行评估。这通常通过在验证集上进行推理来完成。以下是inference.py脚本的关键部分,它展示了如何加载训练好的模型并进行人脸特征提取和相似度计算。
原始文档中提到,推理代码经过修改,可以直接对预先检测并裁剪好的人脸图像进行预测,从而避免了在推理阶段再次运行人脸检测模块,提高了推理效率。
import net
import torch
import os
import cv2
from face_alignment import align
import numpy as np
adaface_models = {
\'ir_18\':r".experimentsdefault_08-01_1epoch=24-step=142174.ckpt".replace(\'\\\',\'/\
\'),
}
def load_pretrained_model(architecture=\'ir_18\'):
# load model and pretrained statedict
assert architecture in adaface_models.keys()
model = net.build_model(architecture)
statedict = torch.load(adaface_models[architecture])[\'state_dict\']
model_statedict = {key[6:]:val for key, val in statedict.items() if key.startswith(\'model.\')}
model.load_state_dict(model_statedict)
model.eval()
return model
def to_input(pil_rgb_image):
np_img = np.array(pil_rgb_image)
brg_img = ((np_img[:,:,::-1] / 255.) - 0.5) / 0.5
tensor = torch.tensor([brg_img.transpose(2,0,1)]).float()
return tensor
if __name__ == \'__main__\':
model = load_pretrained_model(\'ir_18\')
feature, norm = model(torch.randn(1,3,112,112))
test_image_path = \'face_alignment/test\'
features = []
for fname in sorted(os.listdir(test_image_path)):
# img = cv2.imread(os.path.join(test_image_path, fname))
# img = torch.from_numpy(img)
img = cv2.imread(os.path.join(test_image_path, fname))
img = np.expand_dims(img, axis=0)
img = img.astype(np.float32)
img = img.transpose(0, 3, 1, 2)
img = torch.from_numpy(img)
# aligned_rgb_img = align.get_aligned_face(path)
# bgr_tensor_input = to_input(aligned_rgb_img)
feature, _ = model(img)
features.append(feature)
similarity_scores = torch.cat(features) @ torch.cat(features).T
print(similarity_scores)
推理代码说明:
load_pretrained_model函数:用于加载训练好的AdaFace模型。它从.ckpt文件中加载模型的权重,并将其应用到模型架构中。to_input函数:将PIL图像转换为模型所需的输入张量格式,包括通道顺序调整(RGB到BGR)、归一化等。- 主程序部分:遍历测试图像文件夹,对每张图像进行预处理,然后送入模型提取特征。最后,计算所有特征向量之间的余弦相似度矩阵,以评估不同人脸之间的相似性。
测试结果分析:
以下是使用三张测试图片进行推理后得到的相似度矩阵示例:




相似度矩阵是一个3x3的矩阵,其中对角线上的值(例如,第一行第一列的值为1)表示同一张图片与自身的相似度,理论上应为1。非对角线上的值表示不同图片之间的相似度。例如,第一张图片与第二张图片的相似度为0.4200,第一张图片与第三张图片的相似度为0.2764。这些相似度分数可以用于人脸验证(判断是否为同一个人)或人脸识别(在数据库中查找匹配的人脸)。
6. CKPT到ONNX模型转换
在模型训练和测试完成后,为了将模型部署到实际应用中,通常需要将其转换为更通用的推理格式,例如ONNX(Open Neural Network Exchange)。ONNX提供了一个开放的格式,用于表示机器学习模型,使得模型可以在不同的框架和硬件上进行部署。本节将详细介绍如何将PyTorch训练生成的.ckpt模型转换为ONNX格式,并验证转换后的模型是否保持了原始模型的推理精度。
6.1. ONNX转换脚本
由于AdaFace的原始作者可能未提供直接的ONNX转换脚本,以下是一个自定义的Python脚本,用于将.ckpt模型转换为.onnx格式。
import argparse
import cv2
import numpy as np
import onnxruntime
import torchvision.transforms as transforms
import torch
import net
parser = argparse.ArgumentParser(description=\'onnx inference\')
parser.add_argument(\'--ckpt_path\', default=r\'./experiments/default_08-01_1/epoch=24-step=142174.ckpt\', type=str, required=True, help=\'\')
parser.add_argument(\'--onnx_name\', default=\'ada_Face_142174\', type=str, required=True, help=\'\')
parser.add_argument(\'--model_name\', default=None, type=str, required=True, help=\'\')
parser.add_argument(\'--onnx_path\', default=None, type=str, required=True, help=\'\')
parser.add_argument(\'--image\', default=None, type=str, required=True, help=\'\')
args = parser.parse_args()
adaface_models = {
\'ir_18\':r".experimentsdefault_08-01_1epoch=24-step=142174.ckpt".replace(\'\\\',\'/\
\'),
}
def load_pretrained_model(architecture=\'ir_18\'):
# load model and pretrained statedict
assert architecture in adaface_models.keys()
model = net.build_model(architecture)
statedict = torch.load(adaface_models[architecture])[\'state_dict\']
model_statedict = {key[6:]:val for key, val in statedict.items() if key.startswith(\'model.\')}
model.load_state_dict(model_statedict)
model.eval()
return model
def l2_norm(x):
""" l2 normalize
"""
output = x / np.linalg.norm(x)
return output
def to_numpy(tensor):
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
def get_test_transform():
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])])
return test_transform
def main():
# img = cv2.imread(args.image)
# img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# img = get_test_transform()(img)
# img = img.unsqueeze_(0)
# print(img.shape)
img1 = cv2.imread(args.image)
img1 = np.expand_dims(img1, axis=0)
img1 = img1.astype(np.float32)
img1 = img1.transpose(0, 3, 1, 2)
img1 = torch.from_numpy(img1)
model = load_pretrained_model(\'ir_18\')
model.eval()
torch_out = model(img1)
torch.onnx.export(model,
img1,
"%s.onnx" % args.onnx_name,
export_params=True,
opset_version=11,
do_constant_folding=True,
input_names=[\'input\'],
output_names=[\'output\'])
print("finished")
onnx_path = args.onnx_path
session = onnxruntime.InferenceSession(onnx_path)
inputs = {session.get_inputs()[0].name: to_numpy(img1)}
outs = session.run(None, inputs)[0]
# print(outs.shape)
outs = l2_norm(outs).squeeze()
num = torch_out[0].detach().numpy() * outs
de1 = np.linalg.norm(torch_out[0].detach().numpy()) * np.linalg.norm(outs)
print(np.sum(num) / de1)
if __name__ == \'__main__\':
main()
脚本说明:
ckpt_path:训练好的.ckpt模型文件的路径。onnx_name:转换后ONNX模型的名称。model_name:模型架构名称,例如ir_18。onnx_path:转换后ONNX模型的保存路径。image:用于验证转换的测试图像路径。
该脚本首先加载PyTorch模型,然后使用torch.onnx.export函数将其转换为ONNX格式。opset_version参数指定了ONNX操作集的版本,这对于确保兼容性非常重要。input_names和output_names定义了模型的输入和输出名称,这在后续使用ONNX Runtime进行推理时会用到。
6.2. ONNX模型验证
转换完成后,需要验证ONNX模型是否能够正确地进行推理,并且其输出与原始PyTorch模型的输出保持一致。脚本中通过比较PyTorch模型和ONNX模型对同一输入图像的输出特征向量的余弦相似度来完成验证。如果相似度接近1(例如大于0.999),则表明转换成功且精度保持良好。
onnx_path = args.onnx_path
session = onnxruntime.InferenceSession(onnx_path)
inputs = {session.get_inputs()[0].name: to_numpy(img1)}
outs = session.run(None, inputs)[0]
# print(outs.shape)
outs = l2_norm(outs).squeeze()
num = torch_out[0].detach().numpy() * outs
de1 = np.linalg.norm(torch_out[0].detach().numpy()) * np.linalg.norm(outs)
print(np.sum(num) / de1)
上述代码片段展示了如何使用onnxruntime加载ONNX模型并进行推理,然后计算与PyTorch模型输出的相似度。这种数值对齐的验证方法是确保模型在不同框架间无缝迁移的关键步骤。
7. 模型部署与应用
将模型转换为ONNX格式后,可以利用ONNX Runtime在各种硬件平台和操作系统上进行高效部署。ONNX Runtime支持多种执行提供器(Execution Providers),例如CPU、CUDA、TensorRT等,可以根据部署环境选择最优的推理后端。
7.1. ONNX Runtime推理示例
以下是一个使用ONNX Runtime加载ONNX模型并进行推理的简化示例:
import onnxruntime
import numpy as np
import cv2
def preprocess_image(image_path, image_size=(112, 112)):
img = cv2.imread(image_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # ONNX模型通常期望RGB输入
img = cv2.resize(img, image_size) # 调整到模型输入尺寸
img = img.astype(np.float32) # 转换为浮点型
img = (img / 255. - 0.5) / 0.5 # 归一化到[-1, 1]
img = np.transpose(img, (2, 0, 1)) # HWC to CHW
img = np.expand_dims(img, axis=0) # Add batch dimension
return img
def l2_norm(x):
return x / np.linalg.norm(x, axis=1, keepdims=True)
if __name__ == \'__main__\':
onnx_model_path = \'ada_Face_142174.onnx\'
image_path = \'path/to/your/face_image.jpg\'
# 加载ONNX模型
session = onnxruntime.InferenceSession(onnx_model_path)
# 准备输入数据
input_name = session.get_inputs()[0].name
output_name = session.get_outputs()[0].name
input_data = preprocess_image(image_path)
# 执行推理
outputs = session.run([output_name], {input_name: input_data})
feature_vector = l2_norm(outputs[0]).squeeze() # 提取特征向量并L2归一化
print(\"Extracted Feature Vector Shape:\", feature_vector.shape)
print(\"Feature Vector Sample:\", feature_vector[:5]) # 打印前5个特征值
# 示例:计算两张图片相似度
# image_path_2 = \'path/to/another/face_image.jpg\'
# input_data_2 = preprocess_image(image_path_2)
# outputs_2 = session.run([output_name], {input_name: input_data_2})
# feature_vector_2 = l2_norm(outputs_2[0]).squeeze()
# similarity = np.dot(feature_vector, feature_vector_2)
# print(\"Similarity between two faces:\", similarity)
7.2. 部署注意事项
- 环境配置:确保部署环境中安装了正确版本的ONNX Runtime及其所需的执行提供器(如
onnxruntime-gpu)。 - 性能优化:对于生产环境,可以考虑使用TensorRT等专门的推理引擎,通过模型优化(如量化、图融合)进一步提升推理速度。
- 并发处理:在多用户或高并发场景下,需要合理管理ONNX Runtime会话,例如使用会话池或异步推理,以最大化吞吐量。
- 错误处理与日志:在部署代码中加入健壮的错误处理机制和详细的日志记录,便于问题排查和系统监控。
8. 实践建议与进阶话题(扩展)
本节在不改变前文工程复现流程的基础上,补充若干在学术研究与工程部署中经常被忽视、但对AdaFace等人脸识别系统性能与稳定性至关重要的要点,以帮助读者将模型更稳健地落地到真实业务场景。
8.1 人脸对齐(Alignment)与输入规范
高质量的人脸对齐可以显著提升特征的判别性与稳定性。实践中常见流程为:先用检测器(如RetinaFace或MTCNN)获得人脸框与五点关键点,再以相似变换(similarity transform)将人脸对齐到标准尺寸(如112×112),最后执行与训练阶段一致的归一化策略(例如将像素缩放到[0,1],再按mean/std标准化,或采用本文前述的[-1,1]区间映射)。需要强调的是:训练与推理的预处理必须严格一致(包括通道顺序、尺寸、裁剪与归一化方式),任何偏差都会造成域间分布不匹配,引发显著的精度损失。
在AdaFace等角度间隔(margin-based)方法中,特征的方向性尤为重要。轻微的未对齐、过度裁剪或尺度不一致,都会导致特征方向的系统性偏移,从而影响相似度分布与阈值设置。因此,建议在上线前以大规模、跨设备、跨光照的对齐策略回归测试来验证鲁棒性。
8.2 评价指标与阈值设定
人脸识别的评估应面向任务目标(验证或检索)进行:
- 验证(Verification)通常关注在给定假警报率(FAR)下的真实接受率(TAR),例如报告 TAR@FAR=1e-3/1e-4;
- 检索(Identification)常用Rank-1、Rank-5准确率,以及开集情况下的DET/ROC曲线等。
常见指标包括:
- TPR/Recall(真正率):在同一人的配对中,被正确判为同一人的比例;
- FPR(误接受率):在不同人的配对中,被错误判为同一人的比例;
- EER(Equal Error Rate):FPR与FNR相等时的错误率;
- minDCF:在特定先验与代价下的最小检测成本函数,更贴近部署风险。
阈值设置应依据验证集或与业务相似的开发集通过ROC/PR曲线网格搜索得到。在相似度为余弦相似度的设定下,常见阈值区间约在[0.2, 0.6]之间,但强烈建议以目标场景的数据进行再标定(recalibration),并在版本切换时复核阈值的稳定性。
8.3 训练细节与稳定性建议
- 学习率与里程碑:除固定里程碑外,可考虑基于余弦退火(cosine annealing)或OneCycle策略,以提升后期收敛的平滑性与最终精度。
- 数据增强:在人脸识别中,几何与光照增强需克制,避免破坏人脸结构。可在保证可识别性的前提下,轻度使用随机裁剪、颜色抖动、JPEG压缩噪声与低分辨率模拟,以提升域外鲁棒性。
- 类别不均衡:MS1M等大规模数据集中长尾现象普遍。可采用class-balanced sampling或对尾部类进行重采样;也可结合动态margin策略缓解头尾类学习难度差异。
- 混合精度与梯度累积:启用FP16与梯度累积能显著降低显存压力,但要注意数值稳定性,必要时对BN/同步BN与loss的缩放做专项检查。
8.4 ONNX导出与跨框架一致性
将PyTorch模型导出为ONNX时,建议注意:
- Opset版本:优先选择一个经验证的版本(如11或13),并确保推理后端(ONNX Runtime、TensorRT)均完整支持;
- 动态维度:若需要变批量大小或可变分辨率,使用
dynamic_axes明确声明输入输出维度的可变性; - 模型简化:导出后可使用
onnx-simplifier进行图优化,减少冗余算子; - 数值对齐:对同一批输入,比较PyTorch与ONNX输出的余弦相似度,并建立容差报警(如<0.999则报警),以自动发现导出/后端差异;
- 预处理一致:务必确保导出的推理服务在通道顺序、归一化、尺寸等预处理上与训练严格一致。
部署到ONNX Runtime时,可结合不同执行提供器(EP),如CUDA EP、TensorRT EP或DirectML EP,以兼顾不同硬件平台的吞吐与时延。建议在代表性设备上进行批量/并发压测,绘制吞吐-时延曲线,选择满足SLA的工作点。
8.5 量化、裁剪与蒸馏
在边缘设备与高并发场景中,模型压缩是关键:
- 量化(PTQ/QAT):INT8量化可在精度损失可控的情况下显著提升吞吐与降低时延;QAT通常优于PTQ但成本更高;
- 剪枝与结构化稀疏:结合通道剪枝与稀疏训练,可在保持精度的同时减少计算量;
- 知识蒸馏:以AdaFace大型教师网络蒸馏轻量学生网络,常能获得更优的速度-精度折中。
压缩后的模型必须在业务相关的数据分布上进行精度回归测试,必要时重新调整阈值。
8.6 常见问题排查(FAQ)
- 相似度普遍偏低:检查输入是否做了与训练一致的对齐与归一化;确认是否做了L2归一化;核验通道顺序(BGR/RGB)。
- 某些身份易混淆:检查样本质量,是否存在对齐失败、强遮挡或跨域(妆容、口罩、红外)问题;可针对性增加该域的数据与增强。
- 导出后不一致:对比关键中间张量(如倒数第二层特征),定位差异在前处理、网络算子还是后处理。
- 跨平台数值漂移:使用更高精度(FP32)对齐基线,再逐步引入FP16/INT8,量化时对感受性高的层保留更高精度。
9. 结语与后续工作
本文在合并与梳理三篇实践教程的基础上,系统性地呈现了AdaFace从数据准备、训练评测到ONNX导出与部署的完整流程,并补充了评测指标、对齐策略、压缩与部署优化等关键工程细节。建议读者在实际业务中建立“数据-算法-系统”闭环:持续收集与标注困难样本、进行阈值再标定与A/B测试、构建端到端的性能与稳定性监控,从而使人脸识别系统在复杂真实环境中保持可用、可靠与可演进。


















 3248
3248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











