




PPT来自黑马程序员


32 位系统的最大寻址空间是 2^32 次方,4G。
F(16进制)=1111(2进制)
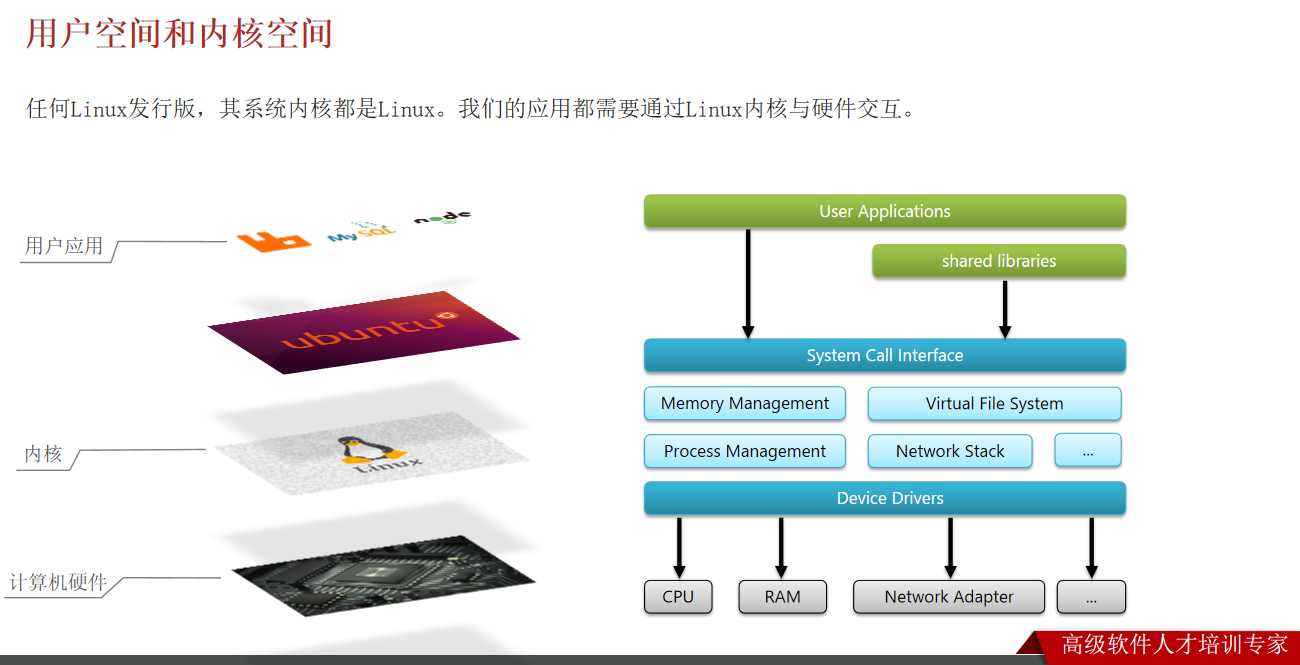
1、什么是 Linux 的虚拟内存?
来自豆包
在 Linux 系统中,虚拟内存(Virtual Memory) 是一种核心内存管理技术,它通过硬件(CPU 的内存管理单元 MMU)和软件(内核)的配合,让应用程序 “以为” 自己独占了一块连续的内存空间,而实际上这些内存可能分散在物理内存的不同区域,甚至部分存储在磁盘上。
其核心作用是:突破物理内存大小的限制,同时简化应用对内存的使用,并隔离不同进程的内存空间。
一、虚拟内存的核心原理
-
地址空间的 “虚拟化”每个进程都拥有独立的虚拟地址空间(32 位系统通常为 4GB,64 位系统则更大),应用程序中使用的所有内存地址(如变量的地址、函数的地址)都是 “虚拟地址”,而非物理内存的真实地址。
-
虚拟地址 → 物理地址的映射当应用程序访问虚拟地址时,CPU 的 MMU(内存管理单元) 会通过页表(Page Table) 将虚拟地址 “翻译” 为实际的物理内存地址。页表由内核维护,记录了虚拟地址与物理地址的映射关系。
-
以 “页” 为单位管理虚拟内存和物理内存都被划分为固定大小的块(通常为 4KB,称为 “页”),映射和管理都以页为单位进行,而非单个字节。
二、虚拟内存的核心功能
1. 突破物理内存限制(“内存扩容”)
当物理内存不足时,内核会将部分暂时不用的内存页(来自不活跃的进程)转移到磁盘上的交换分区(Swap Partition) 或交换文件(Swap File) 中,这个过程称为页面置换(Page Swapping)。当进程需要访问这些被换出的页时,内核会将其从磁盘换回物理内存(可能同时将其他不活跃的页换出),从而让系统能运行比物理内存总量更大的程序。
2. 实现进程内存隔离
每个进程的虚拟地址空间是完全独立的,即使两个进程使用相同的虚拟地址(如 0x123456),通过页表映射后也会指向不同的物理内存区域。这种隔离性确保了:
- 一个进程的错误操作(如越界访问内存)不会影响其他进程;
- 进程无法直接访问内核空间或其他进程的内存,提升了系统安全性。
3. 简化内存管理
- 应用程序无需关心物理内存的实际布局(如是否连续、被谁占用),只需使用连续的虚拟地址即可;
- 内核可以更灵活地分配物理内存(例如将分散的物理页映射为连续的虚拟页)。
三、关键概念:页面异常(Page Fault)
当应用程序访问某个虚拟地址时,如果该地址未被映射到物理内存(或已被换出到磁盘),MMU 会触发页面异常(Page Fault),由内核处理:
- ** minor fault(次要异常)**:虚拟地址已分配但未加载到物理内存(如刚启动的程序,代码还在磁盘上),内核直接将对应的数据加载到物理内存并更新页表。
- ** major fault(主要异常)**:虚拟地址对应的页已被换出到磁盘,内核需要先将其从磁盘读回物理内存(可能需要先换出其他页),再更新页表。
四、虚拟内存的优缺点
优点:
- 允许运行超过物理内存总量的程序;
- 实现进程内存隔离,提高系统稳定性和安全性;
- 简化应用程序的内存使用(无需关心物理内存细节);
- 内核可高效管理内存(如按需加载、页面共享)。
缺点:
- 地址转换(虚拟→物理)会带来一定的性能开销(通过 TLB 缓存缓解);
- 频繁的页面置换(Swap)会导致系统性能急剧下降(磁盘速度远慢于内存);
- 可能掩盖内存泄漏问题(程序占用过多虚拟内存但未被及时释放)。
总结
Linux 虚拟内存通过 “地址虚拟化” 和 “磁盘交换” 技术,解决了物理内存有限、进程隔离、内存管理复杂等核心问题,是现代操作系统能高效、安全运行多任务的基础。理解虚拟内存,有助于排查内存泄漏、OOM(内存溢出)等问题,也能更好地优化系统性能(如合理设置 Swap 大小)。
2、内核空间 也是 虚拟内存吗?
是的,在 Linux 等现代操作系统中,内核空间本身也使用虚拟内存,而非直接操作物理内存地址。这是由虚拟内存机制的全局特性决定的 —— 整个系统(包括内核和用户进程)都运行在虚拟地址空间中,通过页表映射到物理内存。
为什么内核空间需要虚拟内存?
-
统一地址访问方式内核需要访问物理内存的任意位置(如管理进程数据、操作硬件缓冲区),但直接使用物理地址会导致两个问题:
- 无法利用 MMU 提供的内存保护机制(如禁止用户空间访问内核内存);
- 当物理内存布局复杂(如存在内存空洞、IO 地址映射)时,直接操作物理地址会非常繁琐。而通过虚拟地址,内核可以用统一的方式访问所有内存,由 MMU 负责底层的物理地址转换。
-
支持内存隔离与保护内核空间的虚拟地址被标记为 “特权级访问”(通过页表中的权限位),普通用户进程(运行在 Ring 3)若试图访问这些地址,会被 MMU 拦截并触发异常(如段错误),从而保护内核内存不被用户程序篡改。
-
方便内存管理功能实现内核的许多核心功能(如内存分配、页表管理、进程切换)依赖虚拟内存机制:
- 例如,内核可以通过修改页表,将物理内存的不同区域 “映射” 到内核虚拟地址的连续区域,简化内存操作;
- 当系统启用内存分页(Paging)时,内核自身的代码和数据也必须通过页表映射,否则无法被 CPU 访问。
内核空间虚拟内存的特殊性
虽然内核空间使用虚拟内存,但它与用户空间的虚拟内存有显著区别:
-
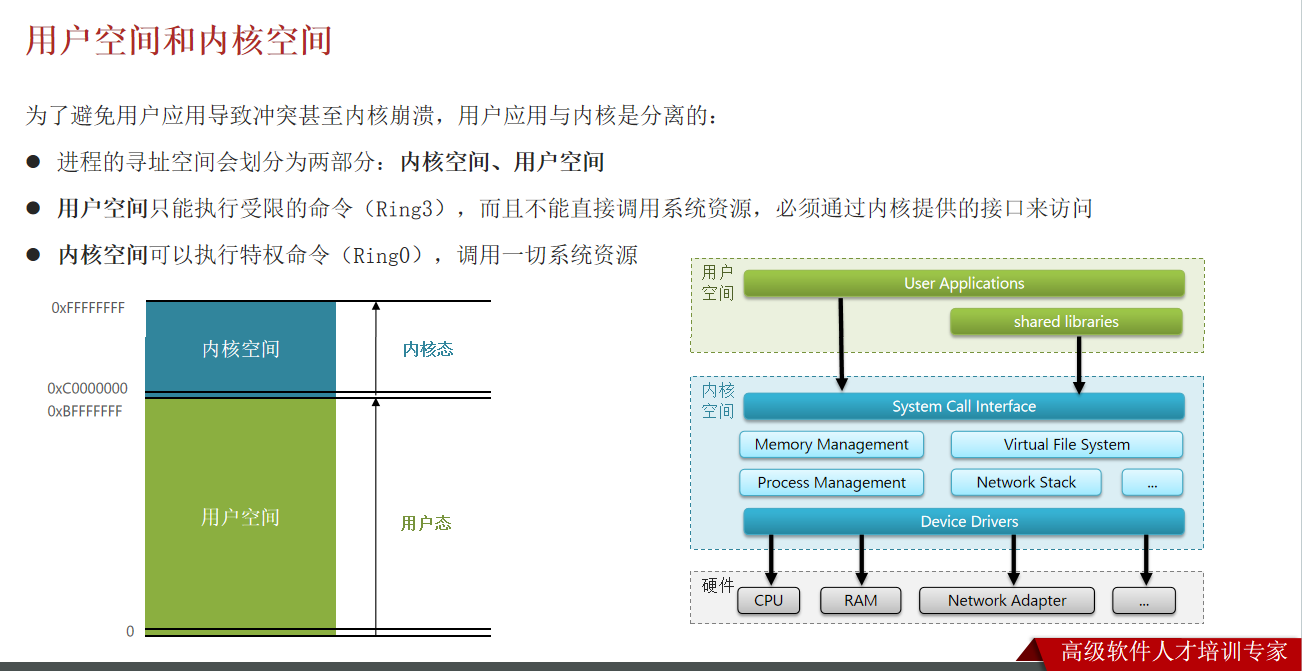
地址范围固定内核空间的虚拟地址范围是固定的(由操作系统设计决定)。例如:
- 32 位系统中,通常将 4GB 虚拟地址空间划分为两部分:用户空间(0~3GB)和内核空间(3GB~4GB);
- 64 位系统中,内核空间通常占据虚拟地址空间的高地址部分(如 Linux 为最高 128TB)。
-
全局共享所有进程的内核空间虚拟地址映射到同一块物理内存区域(内核代码和数据所在的物理内存)。也就是说,无论哪个进程执行系统调用进入内核态,看到的内核虚拟地址对应的物理内存都是相同的 —— 这保证了内核功能的一致性。
-
权限更高内核空间虚拟地址在页表中被标记为 “特权级可访问”(仅 Ring 0 级可读写),而用户空间地址通常标记为 “用户级可访问”(Ring 3 级可读写)。这种权限划分由 MMU 硬件强制执行。
-
直接映射区内核虚拟地址中有一部分称为 “直接映射区”(Direct Mapping),这部分虚拟地址与物理地址存在固定的偏移关系(如
虚拟地址 = 物理地址 + 偏移量)。内核通过直接映射区高效访问物理内存(如 DMA 缓冲区、硬件寄存器),避免了复杂的页表查询。
总结
内核空间本质上是内核专用的虚拟地址空间,它和用户空间一样依赖虚拟内存机制实现地址转换、内存保护和管理。但内核空间的虚拟内存具有范围固定、全局共享、权限更高等特性,确保了内核既能安全地访问系统资源,又能为用户进程提供稳定的服务。
简言之:内核空间是虚拟内存的一部分,是内核专属的虚拟地址区域。
3、什么是 内核空间,用户空间?
要理解内核空间(Kernel Space) 和用户空间(User Space),首先需要明确一个核心前提:现代操作系统(如 Linux、Windows、macOS)为了安全性和稳定性,会强制划分 “操作系统核心代码的运行区域” 和 “普通应用程序的运行区域”,两者在权限、功能、访问范围上完全隔离 —— 这就是 “内存空间隔离” 机制的核心。
一、本质区别:权限与角色的隔离
内核空间和用户空间的核心差异,本质是 “操作系统内核” 与 “普通应用” 的角色分工不同:
- 内核(Kernel):操作系统的 “大脑”,直接管理硬件(CPU、内存、磁盘、网卡等),执行最核心的操作(如进程调度、内存分配、文件读写、网络通信),拥有最高权限(Ring 0 级,CPU 硬件级特权)。
- 普通应用(如浏览器、微信、Office):用户直接使用的程序,不允许直接操作硬件,只能通过 “调用内核提供的接口” 间接完成需求,拥有最低权限(Ring 3 级,非特权级)。
两者对应的内存区域,就分别称为 “内核空间” 和 “用户空间”。
二、内核空间(Kernel Space):操作系统的 “专属领地”
内核空间是内核代码、内核数据以及内核管理的硬件资源的 “专属内存区域”,具备以下关键特性:
1. 权限最高:直接操控硬件
内核运行在 CPU 的特权级(Ring 0),可以直接访问所有硬件资源(如读写物理内存地址、控制磁盘控制器、发送网络数据包),也能执行 CPU 的特权指令(如关闭中断、修改页表)。普通应用若试图直接访问内核空间,会被 CPU 立即拦截并触发 “内存访问错误”(如 Linux 下的 Segmentation Fault),强制终止程序 —— 这是硬件级的安全防护。
2. 功能核心:管理系统所有资源
内核空间的核心职责是 “为用户空间提供服务”,具体包括:
- 进程 / 线程管理:调度 CPU 时间片,决定哪个程序先运行;创建 / 销毁进程。
- 内存管理:划分物理内存,为应用分配 “虚拟内存”,管理内存交换(Swap)。
- 设备管理:通过 “设备驱动” 对接硬件,提供统一的设备访问接口(如读写磁盘文件、操作打印机)。
- 文件系统:管理磁盘上的文件和目录,处理文件的创建、删除、读写权限。
- 网络管理:处理 TCP/IP 协议、数据包收发,实现应用的网络通信(如浏览器访问网页)。
3. 共享性:所有进程共享同一内核空间
虽然每个应用都有独立的用户空间,但所有进程共享同一个内核空间。例如:Chrome、微信、终端这三个进程,它们的用户空间是隔离的,但调用的内核代码(如文件读写函数)是同一个 —— 这保证了内核资源的高效利用,也避免了内核代码的重复加载。
三、用户空间(User Space):普通应用的 “受限区域”
用户空间是普通应用程序代码、数据的运行区域,是用户能直接交互的 “应用层”,具备以下特性:
1. 权限最低:无法直接操作硬件
应用运行在 CPU 的非特权级(Ring 3),不能直接访问硬件或内核空间的内存。例如:
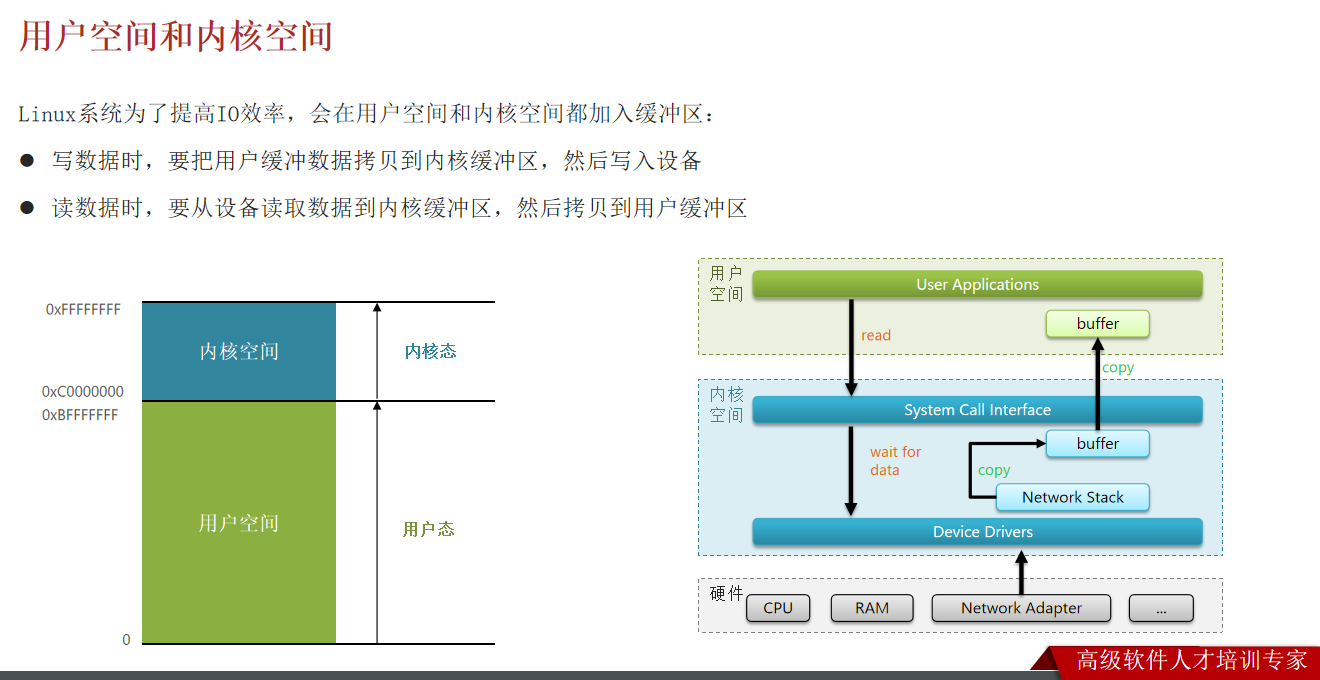
- 应用想读取磁盘上的文件,不能直接发送指令给磁盘控制器,必须通过 “调用内核的文件读写接口(如 Linux 的
read()系统调用)”,由内核代劳。 - 应用想分配内存,不能直接划分物理内存,必须通过 “调用内核的内存分配接口(如
malloc(),最终会触发brk()或mmap()系统调用)”,由内核分配虚拟内存并映射到物理内存。
2. 隔离性:每个应用的用户空间独立
为了避免应用之间的相互干扰(如 A 程序修改 B 程序的内存导致 B 崩溃),操作系统会为每个进程分配独立的用户空间(基于 “虚拟内存” 技术)。例如:Chrome 进程的用户空间内存地址 0x123456,和微信进程的 0x123456 指向的是不同的物理内存 —— 这种 “地址隔离” 保证了一个应用崩溃(如 Chrome 闪退)不会影响其他应用或操作系统。
3. 依赖内核:通过 “系统调用” 获取服务
用户空间的应用要完成任何 “超出自身权限” 的操作(如读写文件、联网、创建进程),都必须通过系统调用(System Call) 向内核 “请求服务”—— 系统调用是用户空间与内核空间通信的唯一合法 “桥梁”。
举个具体例子:当你用记事本保存文件时,背后的流程是:
- 记事本(用户空间)调用 “写入文件” 的函数(如 Windows 的
WriteFile()、Linux 的write()); - 该函数触发系统调用,CPU 从 “非特权级(Ring 3)切换到特权级(Ring 0)”,进入内核空间;
- 内核(内核空间)执行真正的磁盘写入操作(通过磁盘驱动控制硬件);
- 写入完成后,CPU 切换回 “非特权级”,内核将结果返回给记事本(用户空间)。
四、核心对比:内核空间 vs 用户空间
为了更清晰地理解两者差异,下表总结了关键维度的对比:
| 对比维度 | 内核空间(Kernel Space) | 用户空间(User Space) |
|---|---|---|
| 运行主体 | 操作系统内核(Kernel)、设备驱动 | 普通应用程序(浏览器、Office、游戏等) |
| CPU 权限级 | 特权级(Ring 0),可执行所有指令 | 非特权级(Ring 3),仅能执行普通指令 |
| 内存访问范围 | 可访问所有物理内存、硬件资源、内核数据 | 仅能访问自身的虚拟内存区域,无法直接访问硬件 / 内核 |
| 进程共享性 | 所有进程共享同一内核空间 | 每个进程有独立的用户空间,相互隔离 |
| 核心功能 | 管理硬件、调度进程、分配内存、提供系统服务 | 实现用户交互逻辑(如界面显示、数据处理) |
| 崩溃影响 | 内核崩溃会导致整个系统宕机(如 Linux 内核 panic) | 单个应用崩溃仅影响自身,不影响系统 / 其他应用 |
五、为什么需要这种隔离?
划分内核空间和用户空间,是现代操作系统 “安全稳定” 的基石,主要解决两个核心问题:
-
防止应用破坏系统:若没有隔离,恶意应用或有 Bug 的应用可能直接修改内核代码或硬件设置(如删除系统文件、篡改内存),导致整个系统崩溃或被入侵。例如:早期的 DOS 系统没有空间隔离,一个应用的错误可能直接让整个系统蓝屏。
-
简化应用开发:应用无需关心硬件细节(如不同品牌的磁盘如何读写、不同网卡如何联网),只需调用内核提供的统一接口即可 —— 内核帮应用屏蔽了硬件的复杂性,降低了开发难度。
总结
- 内核空间是操作系统的 “特权区”,负责管理硬件和核心资源,权限最高、不可被普通应用访问;
- 用户空间是应用的 “受限区”,负责实现用户功能,权限最低、相互隔离,必须通过系统调用依赖内核服务;
- 两者的隔离是 “硬件级 + 软件级” 的双重防护,最终保障了操作系统的安全与稳定。
4、什么叫 内核态,用户态?
内核态(Kernel Mode)和用户态(User Mode)是 CPU 运行程序时的两种特权级别,是操作系统实现安全性和稳定性的核心机制。它们的本质区别在于程序能访问的系统资源范围和可执行的指令类型。
一、核心区别:权限的边界
现代 CPU(如 x86 架构)通常设计了多个特权级别(称为 “Ring”),从 Ring 0(最高权限)到 Ring 3(最低权限)。操作系统只使用其中两个核心级别:
- 内核态:对应 Ring 0 级,拥有最高权限,可以直接访问所有硬件资源(如 CPU 寄存器、物理内存、磁盘控制器),执行所有类型的 CPU 指令(包括特权指令,如修改页表、关闭中断)。
- 用户态:对应 Ring 3 级,拥有最低权限,只能访问进程自身的虚拟内存和有限的指令集,不能直接操作硬件或访问内核资源。
二、内核态(Kernel Mode):操作系统的 “特权模式”
当 CPU 处于内核态时,运行的是操作系统内核代码(如进程调度、内存管理、设备驱动等),具备以下特点:
-
完全访问系统资源内核态可以直接读写物理内存的任意地址、操作硬件设备(如向磁盘控制器发送指令)、修改 CPU 状态(如切换进程上下文),不受权限限制。
-
执行特权指令某些 CPU 指令(如
cli关闭中断、in/out访问 IO 端口、mov cr0修改控制寄存器)被定义为 “特权指令”,只能在内核态执行。用户态若尝试执行这些指令,会被 CPU 立即拦截并触发异常(如崩溃)。 -
负责核心系统管理内核态的核心工作是为用户态程序提供服务,例如:
- 进程调度:决定哪个程序获得 CPU 时间;
- 内存分配:为用户程序分配虚拟内存;
- 设备交互:通过驱动程序操作硬件(如读写文件、网络传输)。
三、用户态(User Mode):应用程序的 “受限模式”
用户态是普通应用程序(如浏览器、文档编辑器、游戏)的运行模式,特点是:
-
资源访问受限用户态程序只能访问自身的虚拟内存空间,无法直接访问物理内存、硬件设备或内核数据。例如:
- 若应用想读取磁盘文件,不能直接向磁盘控制器发指令,必须通过内核提供的
read()系统调用,由内核态代劳; - 若应用想访问其他进程的内存,会被 CPU 阻止(触发段错误),确保进程隔离。
- 若应用想读取磁盘文件,不能直接向磁盘控制器发指令,必须通过内核提供的
-
只能执行非特权指令用户态程序只能使用普通指令(如算术运算、内存读写自身数据),无法执行特权指令(如修改 CPU 特权级)。
-
依赖内核提供服务任何需要 “突破自身权限” 的操作(如创建进程、联网、读写硬件),都必须通过系统调用(System Call) 向内核请求服务,从用户态切换到内核态完成操作后再返回。
四、状态切换:用户态 ↔ 内核态
用户态和内核态的切换是操作系统运行的基本过程,通常通过以下场景触发:
-
系统调用(主动切换)用户程序主动请求内核服务时(如
open()打开文件、send()发送网络数据),会执行特殊指令(如 x86 的syscall),触发 CPU 从用户态(Ring 3)切换到内核态(Ring 0)。内核处理完请求后,再通过sysret指令切回用户态。 -
中断 / 异常(被动切换)
- 硬件中断:如磁盘读写完成、网络数据包到达时,硬件会向 CPU 发送中断信号,CPU 暂停当前用户程序,自动切换到内核态执行中断处理程序(如处理网络数据),完成后返回用户态。
- 程序异常:如用户程序访问无效内存(空指针)、除零错误时,CPU 会触发异常,强制切换到内核态,由内核处理(如终止程序并提示 “段错误”)。
-
进程调度当进程的 CPU 时间片用完,或有更高优先级进程需要运行时,内核的调度器会触发切换:先将当前用户态进程暂停,保存其状态,再切换到另一个进程(可能是用户态或内核线程)。
五、为什么需要区分两种状态?
核心目的是保护系统安全与稳定:
- 防止用户程序误操作或恶意破坏系统:若所有程序都能直接访问硬件和内核资源,一个有 Bug 的程序可能篡改内核代码、删除系统文件,导致整个系统崩溃。
- 简化应用开发:用户程序无需关心硬件细节(如不同磁盘的驱动方式),只需调用内核接口,降低了开发复杂度。
总结
- 内核态:操作系统内核的运行模式,权限最高,直接管理硬件和系统资源,执行特权指令。
- 用户态:普通应用的运行模式,权限最低,只能访问自身资源,依赖内核提供服务。
- 两者通过系统调用、中断等机制切换,形成了 “用户程序受限运行,内核统一管理资源” 的安全模型,是现代操作系统的基础。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









