




要搞清楚 > 和 >> 的区别,首先要先搞清楚,什么是文件描述符?
1、文件描述符
文件描述符(File Descriptor,简称FD)是一个非负整数。在 Linux 系统中,当有一个进程,打开了一个现有的文件,或者创建了一个新的文件的时候,内核向进程返回的,就是该文件的一个文件描述符。然后进程通过这个文件描述符,可以完成对这个文件的 IO操作。
所以,文件描述符可以理解为,
Linux 内核为高效地管理被进程打开的文件,而创建的一个索引,或者表。
有几点需要注意:
- 文件描述符是一个非负整数。
- 文件描述符是针对每个进程而言的,并不是文件本身的一个属性。
- 文件描述符是 Linux 内核为高效地管理被进程打开的文件,而创建的一个索引。
操作系统中,最大的文件描述符,可以用命令查看:
sysctl -a|grep fs.file-max

在 Linux 中有三个描述符,默认被系统所占用:
- 0 (Standard In 简写 stdin ):标准输入,通常来自键盘。
- 1 (Standard Out 简写 stdout):标准输出,通常指向终端窗口或屏幕。
- 2 (Standard Error 简写 stderr):标准错误输出,也通常指向终端窗口或屏幕,但专门用于显示错误信息。
标准输入很好理解,在这里有必要解释一下 标准输出 和 标准错误输出。
比如,我们在终端打印一行命令:
echo 'hello shell'

紧接着 hello shell 字符串被输出到终端窗口。
比如,我们在终端打印一条不存在的命令:
lsls

因为系统中并不存在 lsls 命令,所以报错信息 command not found,被输出到终端窗口。
2、重定向符号
在 Linux 中,> 和 >> 是用于重定向输出的符号,它们允许你将命令的输出保存到文件中。两者的主要区别在于如何处理目标文件中的现有内容:
> (覆盖重定向)
- 功能:使用 > 会将命令的输出重定向到指定的文件中,如果文件已经存在,则会覆盖原有内容;如果文件不存在,则会创建新文件。
- 用法示例:
# 输出 hello shell-1 到 output.txt 文件中
echo 'hello shell-1' > output.txt
# 输出 hello shell-2 到 output.txt 文件中
# 覆盖 output.txt 原来的内容
echo 'hello shell-2' > output.txt
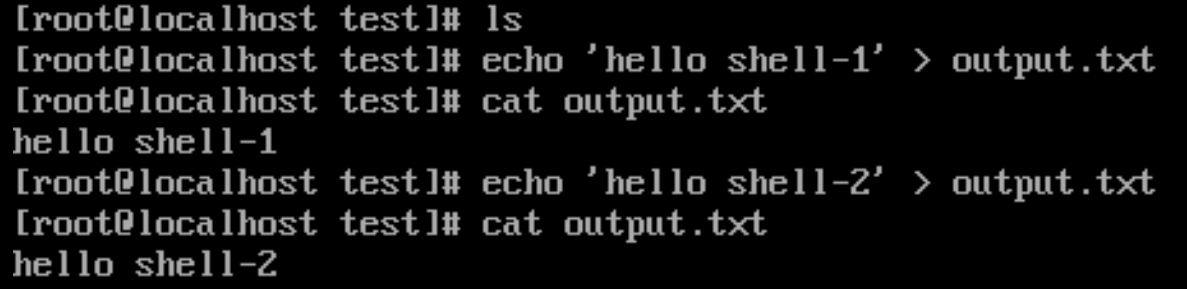
- 扩展示例1:
# 将 cat 的内容重定向到一个新的文件,文件名为 cat.txt
cat output.txt > cat.txt
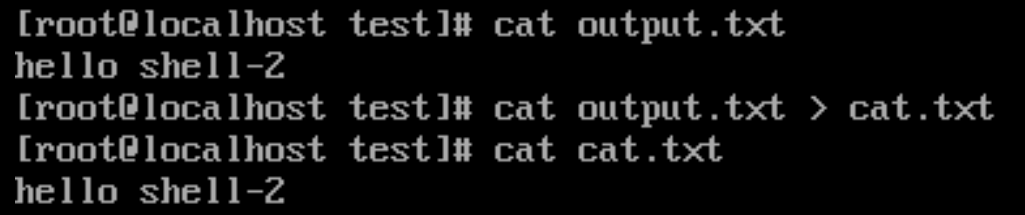
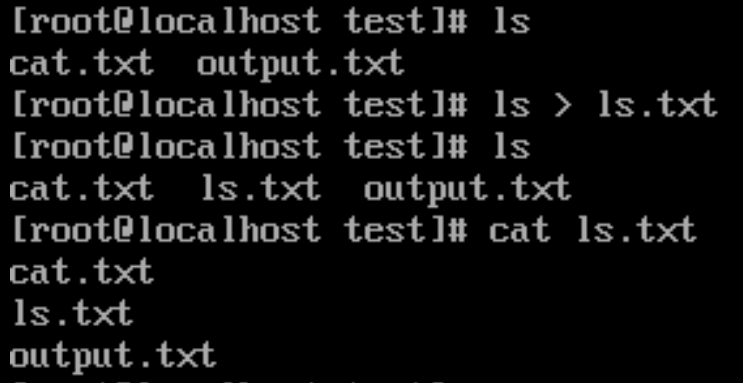
- 扩展示例2:
# 将 ls 的输出,重定向到 ls.txt 文件中
ls > ls.txt
# 查看 ls.txt 内容
cat ls.txt
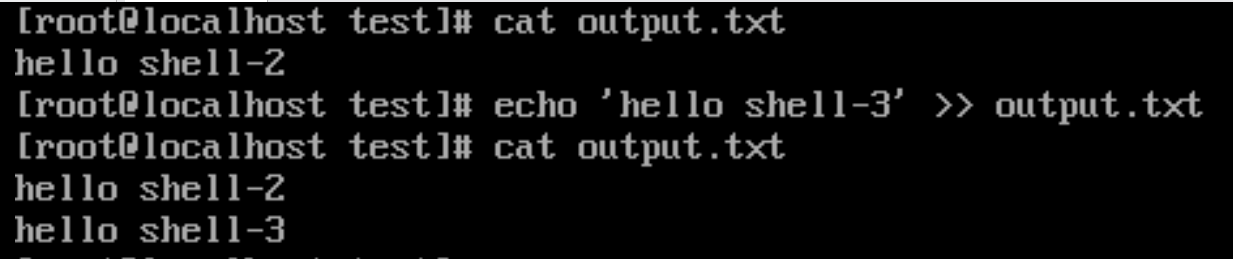
>> (追加重定向)
- 功能:使用 >> 会将命令的输出追加到指定文件的末尾,不会覆盖已有内容。如果文件不存在,则会创建新文件。
- 用法示例:
# 往 output.txt 文件追加内容
echo 'hello shell-3' >> output.txt
注意事项
- > 或 1>:将标准输出(文件描述符 1)重定向到一个文件中。如果只写 >,它默认指的是 1>。
- >> 或 1>>:将标准输出追加到一个文件中。
# 覆盖
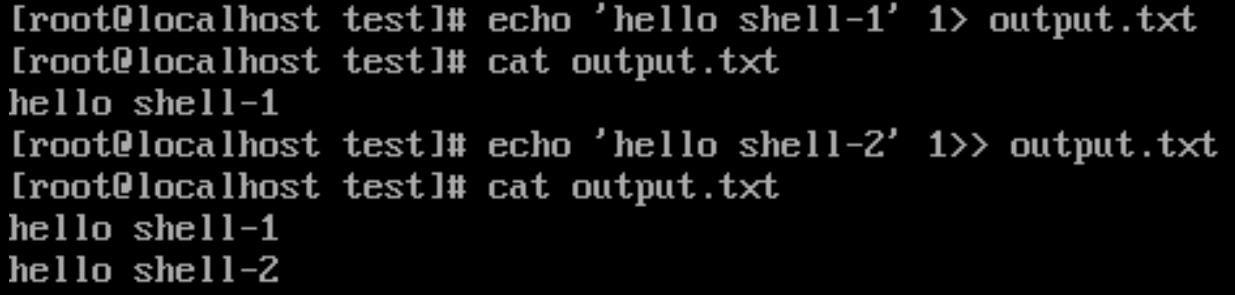
echo 'hello shell-1' 1> output.txt
# 追加
echo 'hello shell-2' 1>> output.txt
- 标准错误重定向:默认情况下,> 和 >> 只重定向标准输出(stdout)。如果你也想重定向标准错误(stderr),可以使用 2> 或 2>> 分别进行覆盖或追加重定向。
- 2>:将标准错误(文件描述符 2)重定向到一个文件中。
- 2>>:将标准错误追加到一个文件中。
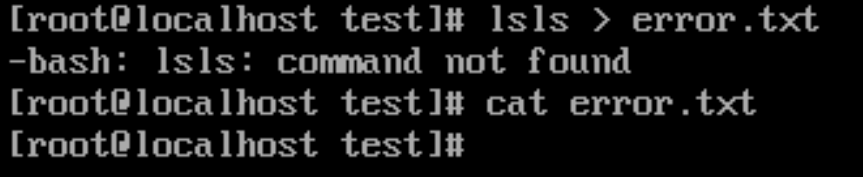
# 尝试将 lsls 的报错信息,重定向到文件 error.txt 中
lsls > error.txt
# 会发现报错信息继续显示在终端屏幕上
-bash: lsls: command not found
# 查看 error.txt 的内容,会发现什么都没有
cat error.txt
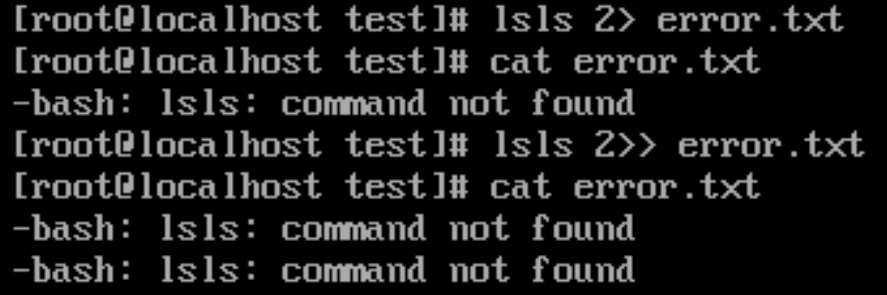
# 这是因为,标准错误输出的文件描述符是2,没有指定,默认是1,所以2要显式写
lsls 2> error.txt
cat error.txt
lsls 2>> error.txt
cat error.txt
合并输出到同一个文件 2>&1
假设现在我们运行一个 SHELL 脚本 command.sh,可能会产生一些标准输出和标准错误信息,并且你想把所有这些信息都保存到一个文件里:
command.sh > output.log 2>&1
这条命令的作用是:
- command.sh > output.log:首先将 command.sh 的标准输出重定向到 output.log 文件。
- 2>&1:然后将标准错误重定向到标准输出(此时标准输出已经指向了 output.log),因此标准错误也会被写入 output.log 文件。
结果就是,无论 command.sh 输出的是普通消息还是错误信息,都会被保存到 output.log 文件中。
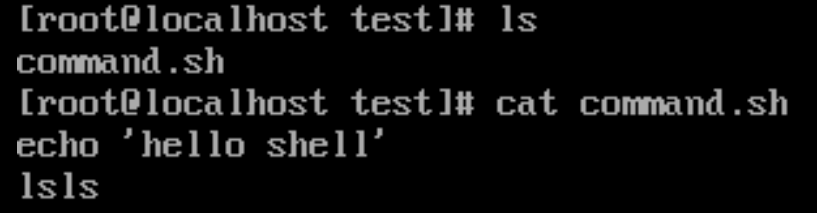
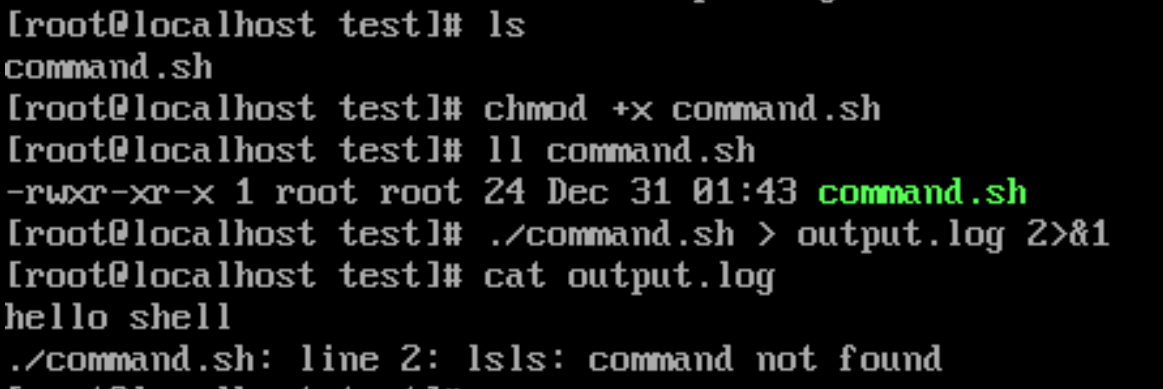
假设 command.sh 脚本内容如下
echo 'hello shell'
lsls
运行 command.sh 脚本
# 给文件 command.sh 增加可执行权限
chmod +x command.sh
# 合并脚本执行过程中的标准输出和标准错误,重定向到 output.log
./command.sh > output.log 2>&1
# 查看 output.log 内容
cat output.log
注意事项
./command.sh > output.log 2>&1
2:指的是标准错误(Standard Error)的文件描述符,其数值为 2。- >:是重定向操作符,用于将输出指向某个地方。
- &1:这里的 & 表示后面的数字是一个文件描述符,而不是一个普通文件的名称。1 则是指标准输出(Standard Output)的文件描述符。
- 不要将 2>&1 写成 2>1 或类似的格式,因为后者会尝试将标准错误重定向到名为 1 的文件,而不是文件描述符 1。
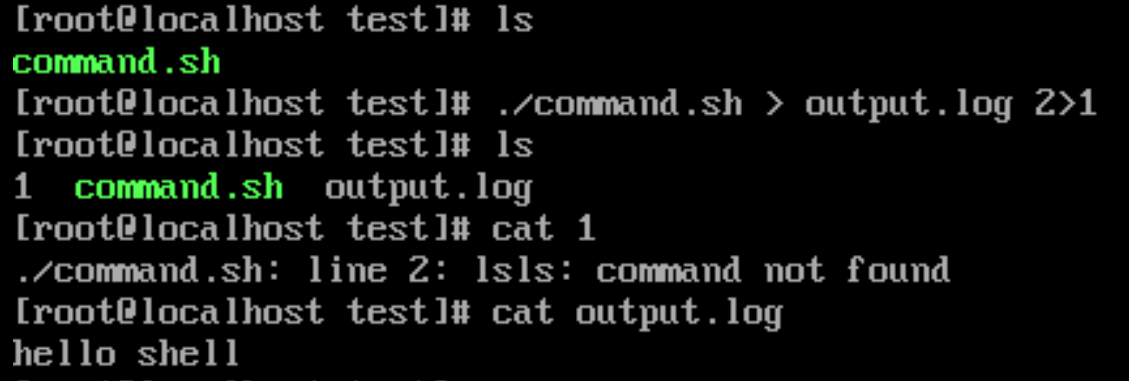
- 不要将 2>&1 写成 2>>&1 的格式,会报命令格式不对。

- 顺序很重要:在使用 2>&1 时,确保它出现在命令行的正确位置。例如,在上面的例子中,2>&1 必须放在 > output.log 之后,因为我们需要先定义标准输出的目标,然后再将标准错误重定向到那里。
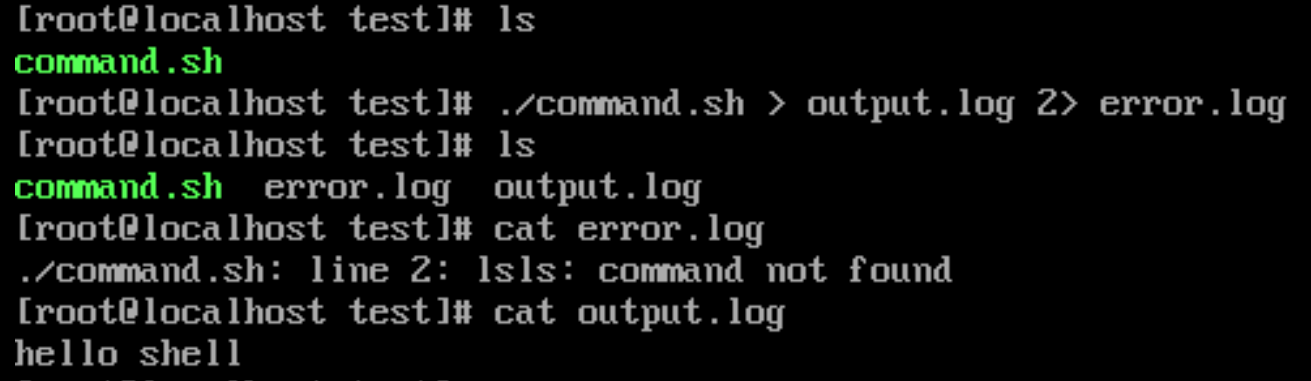
合并标准输出和标准错误到不同的文件
./command.sh > output.log 2> error.log
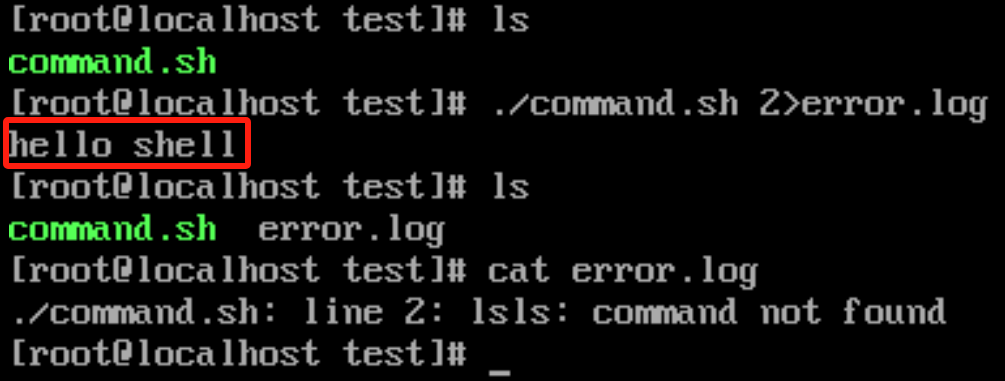
只重定向标准错误
如果你想只重定向标准错误而不影响标准输出,可以这样做:
./command.sh 2> error.log
这会将标准错误输出到 error.log 文件,而标准输出仍然显示在终端上。
丢弃输出 >/dev/null
/dev/null 文件类似于 Linux 系统的回收站,它没有任何内容,>/dev/null 的含义,是将标准输出或标准错误输出丢弃。
丢弃标准错误输出
# 重定向标准错误输出到回收站(丢弃)
./command.sh 2>/dev/null
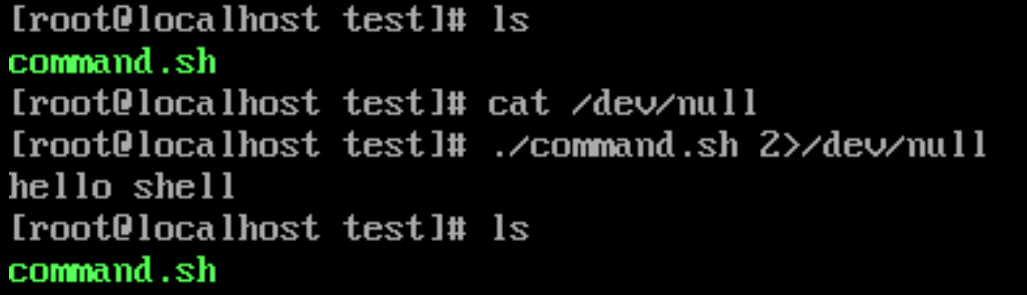
丢弃标准输出跟上面的例子是一样的,只需要把2去掉就可以,这里就不再演示了。

















 8817
8817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









