




 本文介绍了SSD目标检测框架的核心思想与实现细节。SSD采用多尺度特征图和固定大小的候选框来提高检测精度与速度。文章详细阐述了模型结构、训练过程及损失函数。
本文介绍了SSD目标检测框架的核心思想与实现细节。SSD采用多尺度特征图和固定大小的候选框来提高检测精度与速度。文章详细阐述了模型结构、训练过程及损失函数。
今天介绍目标检测中非常著名的一个框架 SSD,与之前的 R-CNN 系列的不同,而且速度比 YOLO 更快。
SSD 的核心思想是将不同尺度的 feature map 分成很多固定大小的 box,然后对每个 box 做预测,既要预测该 box 所包含的 object 属于哪一类,也要预测该 box 与真实的 box 之间的偏差。
为了获得更高的检测精度,SSD 利用了多尺度的技巧,既利用了不同尺度的 feature map,也利用了不同尺度的 box,还利用了不同的比率。
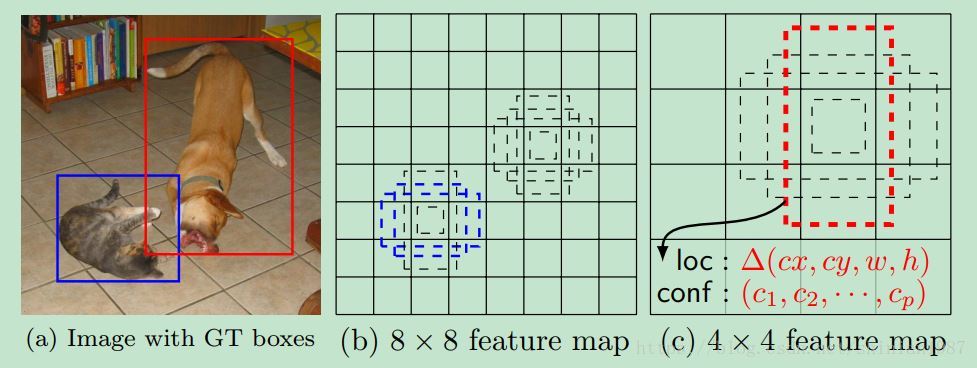
论文也给出了说明图,对 feature map 可以划分成不同尺度的 box,然后每个 box 可以取不同的比率,对应不同的形状,针对不同的形状,预测每个形状属于某一类物体的概率以及该形状偏离真实框多少。
SSD 模型包含两个部分,一部分是正常的前向传播的 CNN 网络,和很多常用的CNN 分类模型类似,论文中用的是类似 VGG 的网络结构,另外一部分是检测网络,
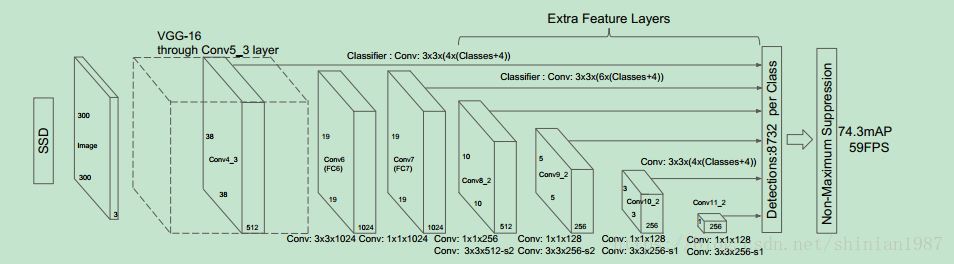
论文给出了 SSD 模型的框架示意图,前面都是正常的卷积层,区别就在后面,SSD 将前面不同卷积层的 feature map 都连接到最后一层,用来做检测,因为不同卷积层的 feature map 的 size 不一样,所以可以形成不同尺度的检测。
每一个连接到最后一层的卷积层都可以产生一系列固定的检测结果,比如,对于一个含有 pp 个通道的卷积层,feature map 的大小为 , 通过 3×33×3 的卷积,可以产生一个分类的概率值,或者四个关于 box 的偏离值,在 m×nm×n 的 feature map 上,每进行一次卷积运算,都能产生相对应的检测结果。
为了便于计算,SSD 模型先设置了一些默认的 box,比如上面图一中的那些 8×88×8 或者 4×44×4 的方块,训练的时候,计算预测的 box 与默认的box之间的偏移,所以,检测的时候,对于每一个检测点,可能先生成 kk 个不同形状的 box,然后每个 box 会输出 个预测值,这 cc 个预测值表示该 box 含有某一类物体的概率,同时也会输出 4 个偏移量,这 4 个偏移量,表示这个 box 与 默认 box 之间的偏移。对于一个检测点,会需要 个滤波器来进行检测,而对于一张大小为 m×nm×n 的 feature map,最终会生成 (c+4)kmn(c+4)kmn 个检测值。
训练的时候,SSD 需要构建 ground truth,需要确定哪些默认 box 是 positive,哪些 默认 box 是 negative,训练的时候,可能需要尝试不同的尺度,hard negative mining 等。
最终的 loss 函数包含两部分,一个是关于分类的 loss,一个是关于预测偏移的 loss,
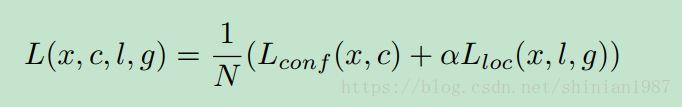
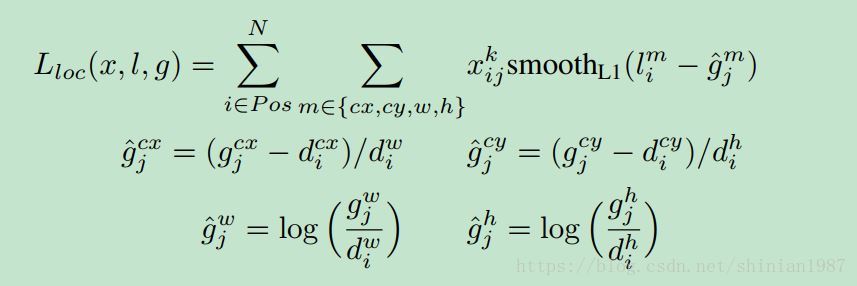
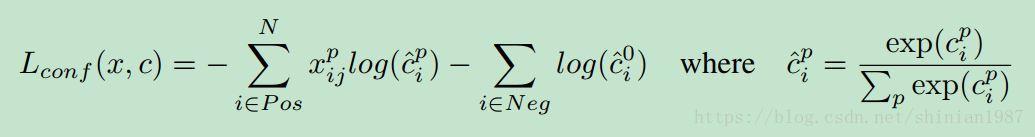
参考文献:
ECCV 2016, SSD: Single Shot MultiBox Detector

















 550
550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









