




本文根据StarRocks Hacker Meetup的录播视频进行整理。如有错误欢迎指正。视频链接:列式存储中实时更新与查询性能如何兼得?演讲者常冰琳,Apache Kudu PMC。
为什么update很重要?
实时分析已经不是新鲜的概念了。数据分析像是和时间赛跑,虽然永远也跑不过时间,但业务总希望能尽早获取数据,诸如反欺诈、订单分析等场景。因此对数据的获取有如下的要求:
- 从实时数据,到热数据,到经常会被修改的数据都需要能够获取并落地使用
- 能够直接对tp系统里的数据进行分析
传统的AP数据库可以完成的工作大多有以下几类:
- T+1的批量ETL,延时太高;
- 做增量append,没有update;
- append update&merge on read,查询性能太差。
常见技术路径
一个基础例子:想要完成整行的更新或者删除,应该如何完成?
方案1:Merge on Read
方案:类似LSM树的数据结构,当有更新数据进来时直接append,在读的时候merge。实现起来相对简单。
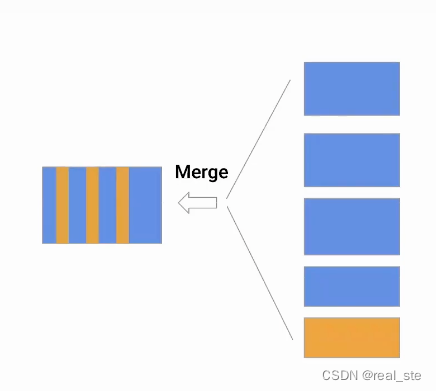
特点:写很快,读很慢
案例:Hudi的Merge on read 表, StarRocks的Unique Key
缺点:对于AP系统更应该更关注查询性能,但Merge-on-read的查询性能显然不佳
方案2:Copy-on-Write
方案:当有新数据进来的时候会和原始数据文件进行对比。
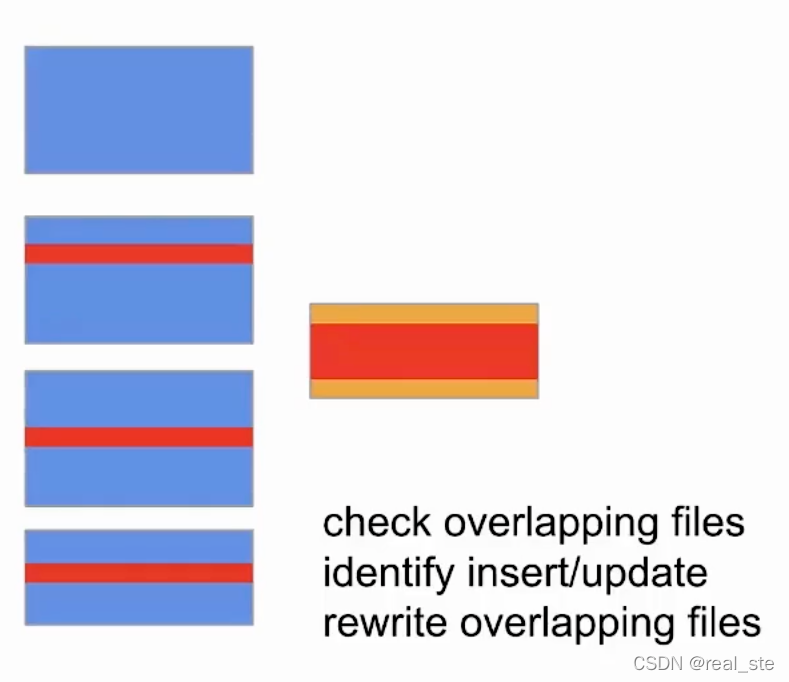
把有变更的文件找出来全部重写,如果找不到历史文件则写入新的文件,其他文件保持不动。
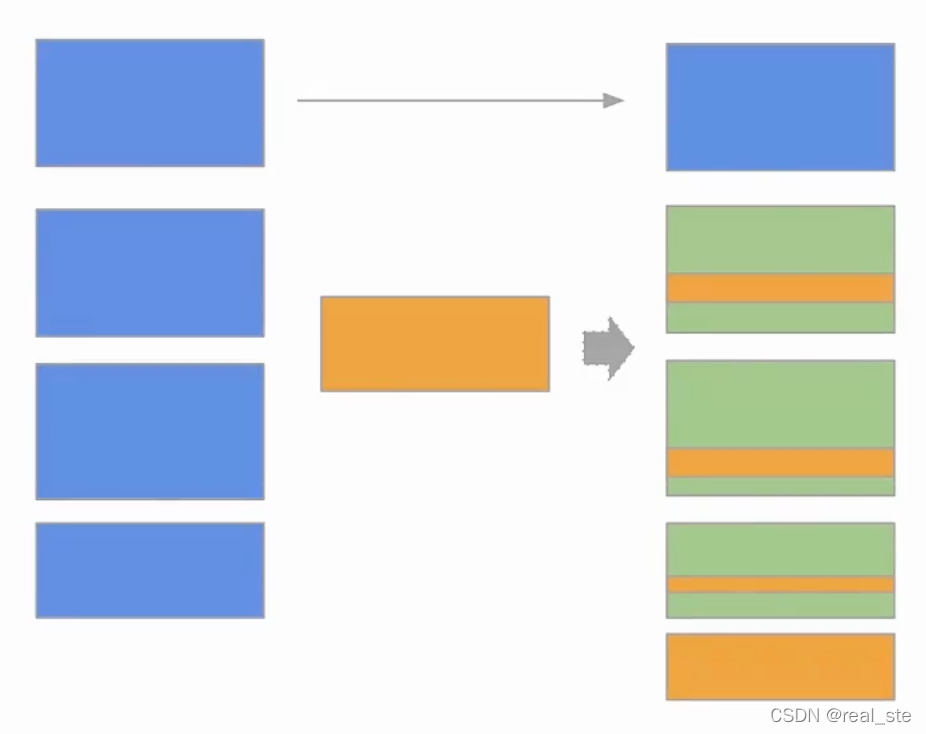
特点:写很慢,读很快。
案例:delta lake,Hudi的copy on write表,Iceberg,Snowflake
缺点:写入的代价太高(每次都要做join操作,如果涉及到更改的文件过多,可能要把数据集全重写一遍),因此适用于那些写入不频繁(例如小时级/天级)的场景,对于秒级写入代价太大。
方案3: Delta Store
方案:由额外的组件索引delta store来定位所有新来的数据原来所在的位置和新的修改。数据读取时需要获取老数据和delta store从而得到最新的版本。
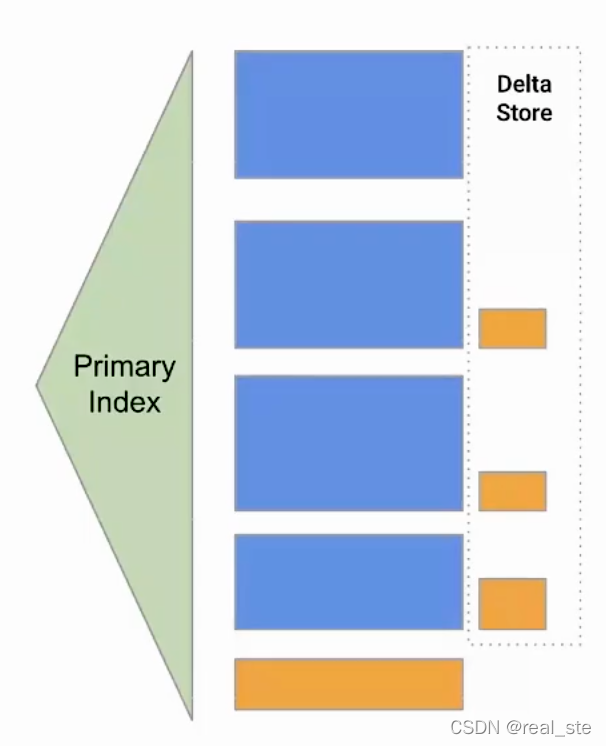
特点:写慢一些,读很快。
案例:Kudu
缺点:写入会比merge on read慢一点,读的性能虽然达不到copy-on-write,也是比较快的。
方案4: Delete+Insert
方案:和Delta Lake类似,有索引。当有更新数据进来时,需要找到这条数据的位置并在索引中记录它已经被删除了。然后将更新的数据当作新的数据直接append操作。读取时遇到被删除的数据直接跳过。
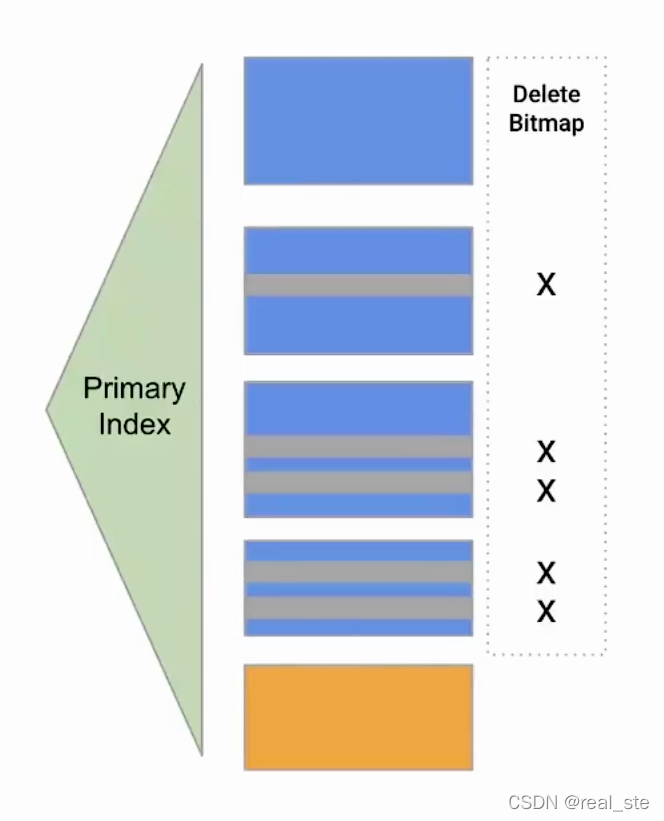
特点:写慢一些,读很快。
案例:SQL Server,ADB,Hologres,StarRocks Primary Key table
缺点:写入会比merge on read慢一点,读的性能虽然达不到copy-on-write,也是比较快的。
方案总结
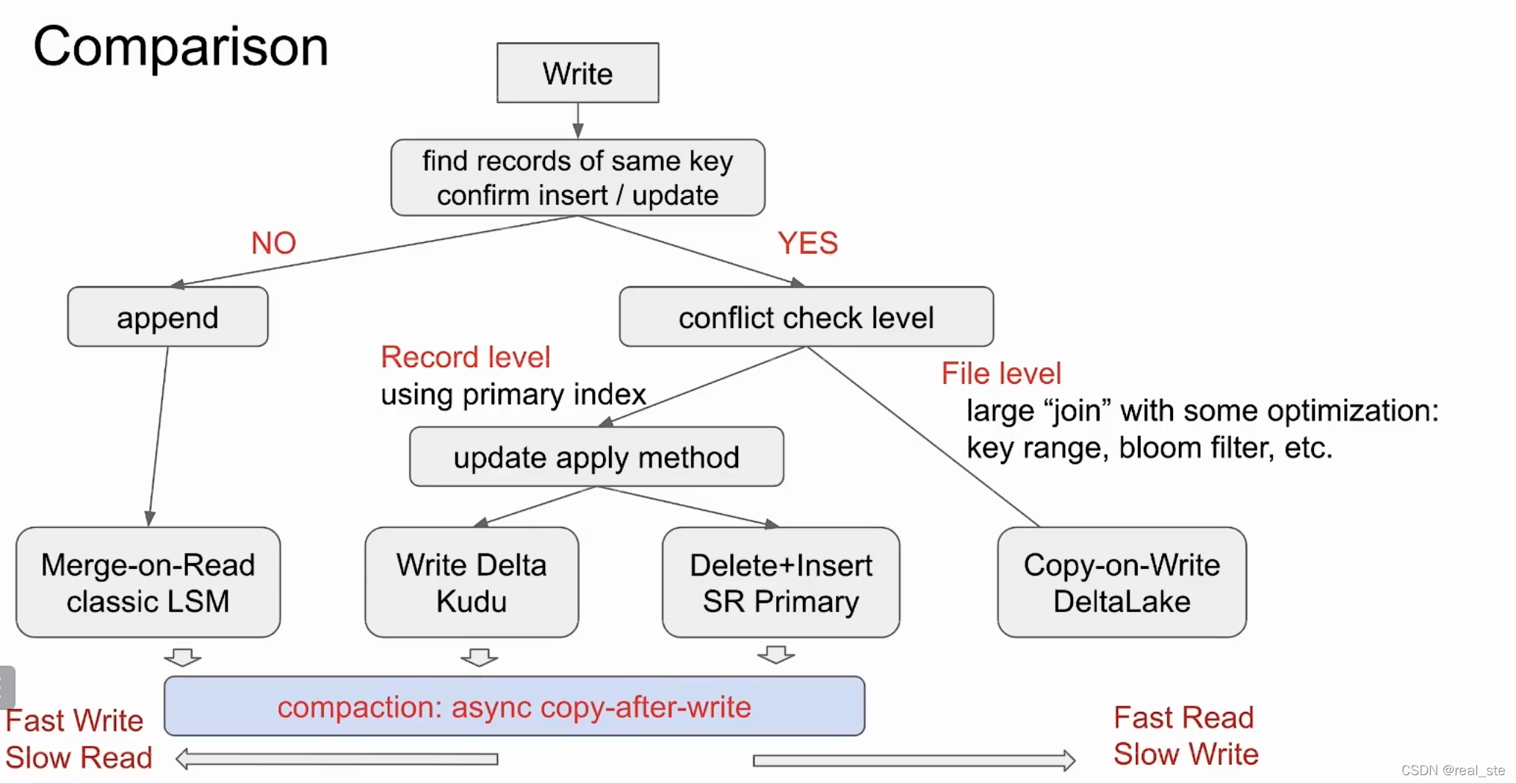
需要注意的是,merge-on-read, delta store和delete+insert都有compaction操作来合并数据。在方案上,读和写不可兼得,只有取舍。
StarRocks的技术路径
一条写入事务在StarRocks内是如何完成的?
StarRocks由FE和BE组成。每张表都会分成很多分区,每个分区又会拆成很多Tablet,每个Tablet都可以做多副本,会被分布在不同的BE上。
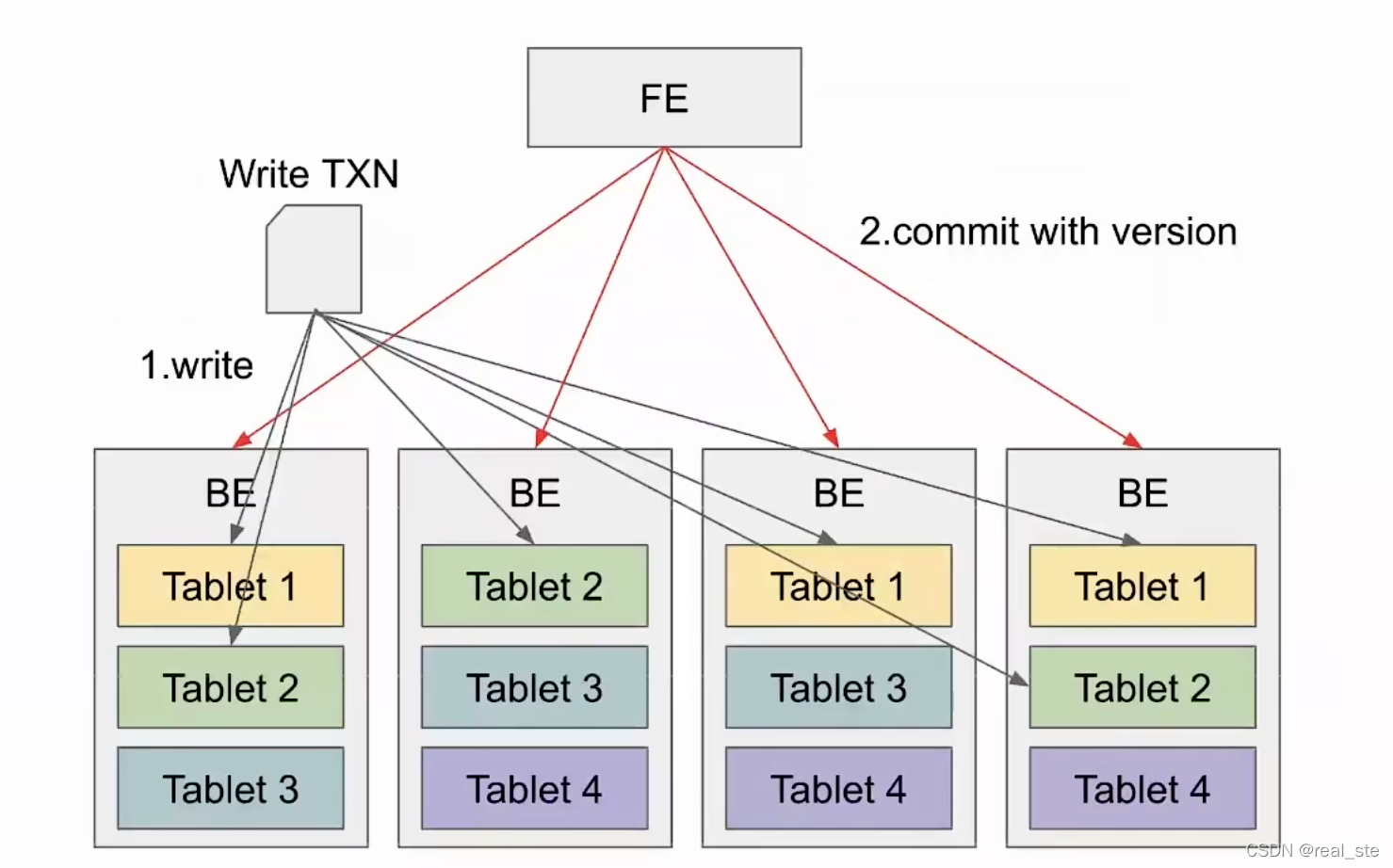
当有写入事务时,StarRocks会根据分区分桶的规则把数据分散至对应tablet上进行数据写入。写入执行完成后,FE会发起带有版本号的commit的消息给BE。BE commit成功后,事
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1533
1533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









