









关键词:Scrapy-Splash、JavaScript渲染、动态网页爬取、Lua脚本、浏览器渲染、爬虫中间件、Docker部署、Ajax请求、SPA应用爬取、网页截图
摘要:本文深入剖析Scrapy-Splash组合解决JavaScript渲染网页爬取难题的完整方案,从实际问题出发,详细讲解Splash浏览器引擎的工作原理、与Scrapy的集成方法以及Lua脚本编写技巧。通过实战案例演示如何爬取单页应用、处理Ajax请求、等待动态元素加载及执行交互操作,最后提供性能优化和大规模部署策略,帮助读者轻松应对现代Web应用的爬取挑战。
Scrapy-Splash攻略:轻松爬取JavaScript动态渲染网页
文章目录
引言:动态网页爬取的挑战
现代Web应用越来越多地依赖JavaScript来动态生成内容。当你使用浏览器访问这些网站时,一切看起来很正常,但当你尝试用传统爬虫(如基础的Scrapy)爬取时,却只能获取到空荡荡的HTML框架,而看不到实际内容。这是因为传统爬虫只能获取服务器直接返回的HTML,无法像浏览器那样执行JavaScript代码来渲染页面。
想象一下,你需要从一个使用Vue.js或React构建的电商网站抓取商品数据,或者从一个使用Ajax加载内容的新闻网站抓取文章。如果使用传统爬虫,你将面临以下挑战:
- 页面内容由JavaScript动态生成,初始HTML几乎为空
- 数据通过Ajax异步加载,需要等待请求完成
- 内容可能需要用户交互(如点击、滚动)才会加载
- 网站可能有反爬机制,检测浏览器特征
这就是为什么我们需要Scrapy-Splash这样的解决方案,它能让Scrapy具备执行JavaScript的能力,像真正的浏览器一样渲染网页。
一、Scrapy-Splash工作原理
1.1 什么是Splash?
Splash是一个由Python编写的轻量级JavaScript渲染服务,它使用WebKit引擎来渲染网页。与Selenium或Puppeteer不同,Splash专为爬虫设计,提供了HTTP API,可以通过HTTP请求控制浏览器行为,非常适合与Scrapy集成。
Splash的主要特点包括:
- 执行JavaScript渲染页面
- 支持Lua脚本编写复杂的浏览器操作
- 提供截图和HTML导出功能
- 支持并发请求处理
- 可通过Docker轻松部署
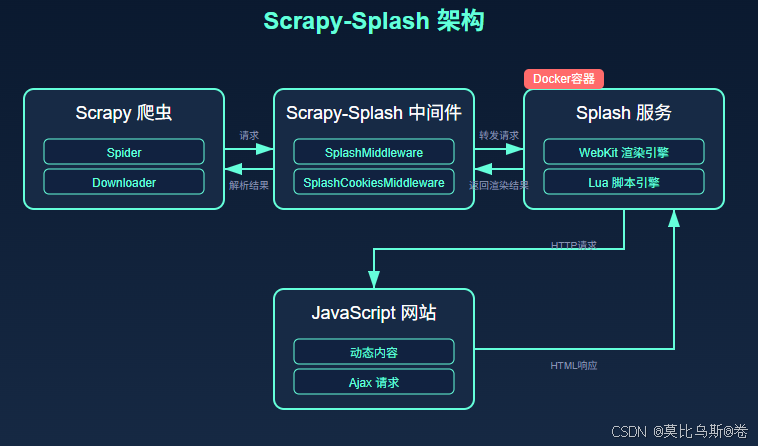
1.2 Scrapy-Splash如何工作?
Scrapy-Splash是一个Scrapy中间件,它将Scrapy与Splash服务无缝集成。工作流程如下:
- Scrapy爬虫发送请求
- Scrapy-Splash中间件拦截请求,将其转发给Splash服务
- Splash执行JavaScript渲染页面
- Splash返回渲染后的HTML、截图或其他数据
- Scrapy-Splash中间件将结果传回Scrapy爬虫
- Scrapy爬虫解析渲染后的内容
这种架构使得Scrapy能够处理JavaScript渲染的网页,就像使用真实浏览器一样。
二、环境搭建与配置
2.1 安装Splash服务
Splash最简单的安装方式是通过Docker。如果你还没有安装Docker,请先前往Docker官网下载安装。
安装Docker后,运行以下命令启动Splash服务:
# 拉取Splash镜像
docker pull scrapinghub/splash
# 启动Splash服务,默认端口8050
docker run -p 8050:8050 scrapinghub/splash
启动成功后,你可以通过访问http://localhost:8050来查看Splash的Web界面。
2.2 安装Scrapy-Splash
使用pip安装Scrapy-Splash:
pip install scrapy-splash
2.3 配置Scrapy项目
在Scrapy项目的settings.py中添加以下配置:
# Splash服务器地址
SPLASH_URL = 'http://localhost:8050'
# 启用Splash中间件
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
# 设置Splash渲染的去重过滤器
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
# 配置Splash缓存策略
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
这些配置将启用Scrapy-Splash的中间件,使爬虫能够通过Splash渲染JavaScript页面。
三、基本用法
3.1 简单的Splash请求
最基本的Splash请求如下:
import scrapy
from scrapy_splash import SplashRequest
class MySpider(scrapy.Spider):
name = 'myspider'
def start_requests(self):
urls = [
'https://example.com/javascript-page',
'https://example.com/another-js-page'
]
for url in urls:
yield SplashRequest(
url=url,
callback=self.parse,
args={'wait': 2}, # 等待2秒,确保JS执行完成
)
def parse(self, response):
# 处理渲染后的页面
title = response.css('h1::text').get()
content = response.css('div.content::text').get()
yield {
'title': title,
'content': content
}
在这个例子中,我们使用SplashRequest替代标准的scrapy.Request,并通过args参数传递配置给Splash。wait参数告诉Splash在返回结果前等待2秒,确保JavaScript有足够时间执行。
3.2 使用Lua脚本
对于更复杂的场景,我们可以使用Lua脚本来控制Splash的行为:
def start_requests(self):
lua_script = """
function main(splash, args)
splash:go(args.url)
splash:wait(2)
-- 点击"加载更多"按钮
splash:select('.load-more-button'):mouse_click()
splash:wait(2)
-- 返回渲染后的HTML和截图
return {
html = splash:html(),
png = splash:png(),
har = splash:har(),
}
end
"""
yield SplashRequest(
url='https://example.com/products',
callback=self.parse,
endpoint='execute', # 使用execute端点执行Lua脚本
args={
'lua_source': lua_script,
'timeout': 90,
}
)
在这个例子中,我们使用Lua脚本控制Splash点击"加载更多"按钮,并等待新内容加载。Lua脚本可以执行各种浏览器操作,如点击、滚动、填写表单等。
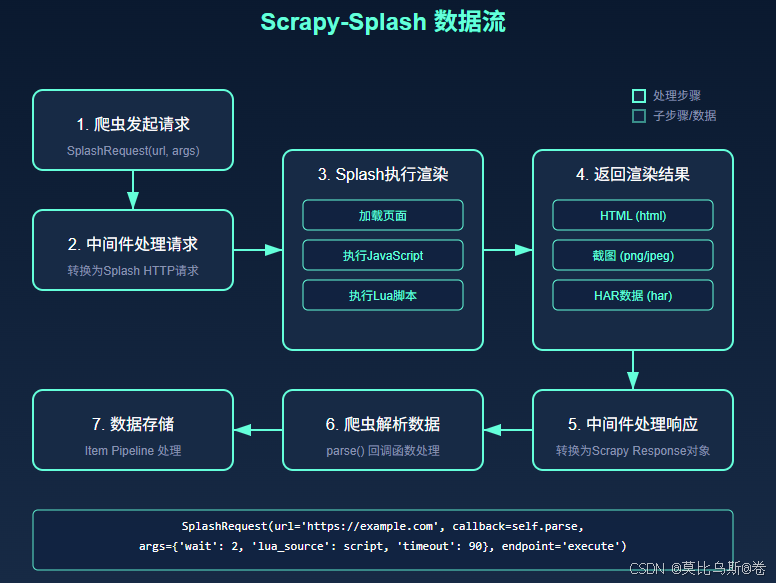
四、实战案例:爬取SPA电商网站
让我们通过一个实际案例来展示如何使用Scrapy-Splash爬取单页应用(SPA)电商网站。假设我们要爬取一个使用Vue.js构建的电商网站,获取商品信息。
4.1 创建Scrapy项目
首先,创建一个新的Scrapy项目:
scrapy startproject ecommerce_spa
cd ecommerce_spa
scrapy genspider products example.com
4.2 配置项目
在settings.py中添加Scrapy-Splash配置(如前所述)。
4.3 编写爬虫
修改products.py爬虫文件:
import scrapy
from scrapy_splash import SplashRequest
import json
class ProductsSpider(scrapy.Spider):
name = 'products'
allowed_domains = ['example.com']
def start_requests(self):
# 商品列表页URL
url = 'https://example.com/products'
# Lua脚本处理分页和等待内容加载
lua_script = """
function main(splash, args)
-- 设置浏览器窗口大小
splash:set_viewport_size(1280, 800)
-- 访问URL
splash:go(args.url)
-- 等待页面加载
splash:wait(2)
-- 滚动页面以触发懒加载
for i=1,10 do
splash:evaluate([[
window.scrollBy(0, 300);
]])
splash:wait(0.3)
end
-- 等待Ajax请求完成
splash:wait(3)
-- 返回渲染后的HTML
return {
html = splash:html(),
png = splash:png(),
url = splash:url()
}
end
"""
yield SplashRequest(
url=url,
callback=self.parse_product_list,
endpoint='execute',
args={
'lua_source': lua_script,
'timeout': 90,
},
meta={'page': 1}
)
def parse_product_list(self, response):
# 提取商品链接
product_links = response.css('div.product-card a::attr(href)').getall()
for link in product_links:
absolute_url = response.urljoin(link)
yield SplashRequest(
url=absolute_url,
callback=self.parse_product_detail,
args={'wait': 3}, # 等待3秒确保商品详情加载完成
)
# 处理下一页
current_page = response.meta['page']
if current_page < 5: # 限制爬取5页
next_page_lua = """
function main(splash, args)
splash:go(args.url)
splash:wait(2)
-- 点击下一页按钮
local next_button = splash:select('a.pagination-next')
if next_button then
next_button:mouse_click()
splash:wait(3)
end
return {html = splash:html(), url = splash:url()}
end
"""
yield SplashRequest(
url=response.url,
callback=self.parse_product_list,
endpoint='execute',
args={'lua_source': next_page_lua},
meta={'page': current_page + 1}
)
def parse_product_detail(self, response):
# 提取商品详情
product = {
'name': response.css('h1.product-title::text').get(),
'price': response.css('span.price::text').get(),
'description': response.css('div.product-description::text').get(),
'images': response.css('div.product-gallery img::attr(src)').getall(),
'specifications': {}
}
# 提取规格参数
specs = response.css('table.specifications tr')
for spec in specs:
key = spec.css('td:nth-child(1)::text').get()
value = spec.css('td:nth-child(2)::text').get()
if key and value:
product['specifications'][key.strip()] = value.strip()
yield product
这个爬虫展示了如何使用Scrapy-Splash处理以下场景:
- 滚动页面触发懒加载内容
- 等待Ajax请求完成
- 点击分页按钮加载更多内容
- 提取渲染后的商品数据
4.4 处理Ajax API请求
许多SPA网站通过Ajax从API获取数据。我们可以使用Splash的网络监控功能来捕获这些请求:
lua_script = """
function main(splash, args)
-- 启用请求监听
splash:on_request(function(request)
if request.url:match('/api/products') then
splash.args.api_url = request.url
end
end)
-- 访问页面
splash:go(args.url)
splash:wait(3)
-- 如果捕获到API URL,直接请求它
if splash.args.api_url then
splash:go(splash.args.api_url)
splash:wait(2)
return {json = splash:html()}
end
return {html = splash:html()}
end
"""
这个脚本可以捕获页面加载过程中的API请求,并直接返回API响应,这通常比解析渲染后的HTML更高效。
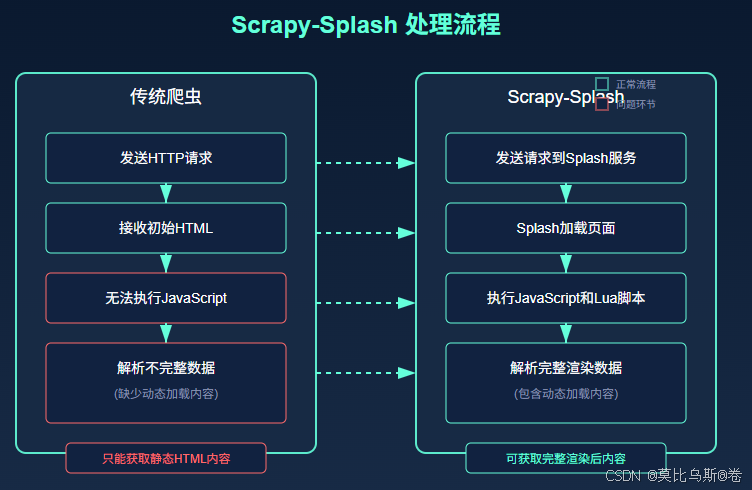
五、高级技巧与最佳实践
5.1 处理Cookie和会话
有些网站需要登录才能访问内容。使用Splash处理登录和会话:
login_script = """
function main(splash, args)
splash:go(args.url)
splash:wait(1)
-- 填写登录表单
splash:select('input[name=username]'):send_text(args.username)
splash:select('input[name=password]'):send_text(args.password)
splash:select('button[type=submit]'):mouse_click()
-- 等待登录成功并跳转
splash:wait(5)
-- 返回cookies和HTML
return {
cookies = splash:get_cookies(),
html = splash:html(),
url = splash:url()
}
end
"""
yield SplashRequest(
url='https://example.com/login',
callback=self.after_login,
endpoint='execute',
args={
'lua_source': login_script,
'username': 'myusername',
'password': 'mypassword',
}
)
登录成功后,你可以在后续请求中使用获取到的cookies。
5.2 处理验证码
对于有验证码的网站,可以结合OCR服务或人工识别:
captcha_script = """
function main(splash, args)
splash:go(args.url)
splash:wait(2)
-- 获取验证码图片
local captcha_img = splash:select('img.captcha')
local captcha_base64 = captcha_img:png_base64()
-- 这里可以将验证码发送给OCR服务或保存下来
return {
captcha = captcha_base64,
html = splash:html(),
cookies = splash:get_cookies()
}
end
"""
5.3 绕过反爬机制
许多网站会检测爬虫行为。使用Splash设置自定义用户代理和浏览器特征:
anti_bot_script = """
function main(splash, args)
-- 设置自定义User-Agent
splash:set_user_agent(args.user_agent)
-- 设置自定义浏览器特征
splash:evaluate([[
Object.defineProperty(navigator, 'webdriver', {
get: () => false,
});
]])
-- 添加随机鼠标移动,模拟真实用户
splash:go(args.url)
splash:wait(2)
-- 随机鼠标移动
for i=1,10 do
local x = math.random(100, 800)
local y = math.random(100, 600)
splash:mouse_move(x, y)
splash:wait(math.random() * 0.3)
end
return {html = splash:html()}
end
"""
yield SplashRequest(
url=url,
callback=self.parse,
endpoint='execute',
args={
'lua_source': anti_bot_script,
'user_agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36',
}
)
5.4 优化性能
Splash渲染比直接HTTP请求慢得多,所以优化性能很重要:
- 使用缓存:配置HTTP缓存减少重复渲染
# settings.py
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 3600 # 缓存1小时
HTTPCACHE_DIR = 'httpcache'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
- 最小化JavaScript执行:只在必要时使用Splash
def start_requests(self):
for url in self.start_urls:
# 先尝试普通请求
yield scrapy.Request(url, self.parse_normal, dont_filter=True)
def parse_normal(self, response):
# 检查是否需要JavaScript渲染
if not response.css('div.content::text').get():
# 内容为空,可能需要JavaScript渲染
yield SplashRequest(
url=response.url,
callback=self.parse_with_js,
args={'wait': 2}
)
else:
# 正常解析
yield self.extract_data(response)
- 并行Splash实例:部署多个Splash服务提高并发
# settings.py
SPLASH_URL = [
'http://splash1:8050',
'http://splash2:8050',
'http://splash3:8050',
]
# 自定义中间件选择Splash实例
class RotatingSplashMiddleware:
@classmethod
def from_crawler(cls, crawler):
return cls(crawler.settings.getlist('SPLASH_URL'))
def __init__(self, splash_urls):
self.splash_urls = splash_urls
self.counter = 0
def process_request(self, request, spider):
if 'splash' in request.meta:
self.counter = (self.counter + 1) % len(self.splash_urls)
request.meta['splash']['args']['url'] = self.splash_urls[self.counter]
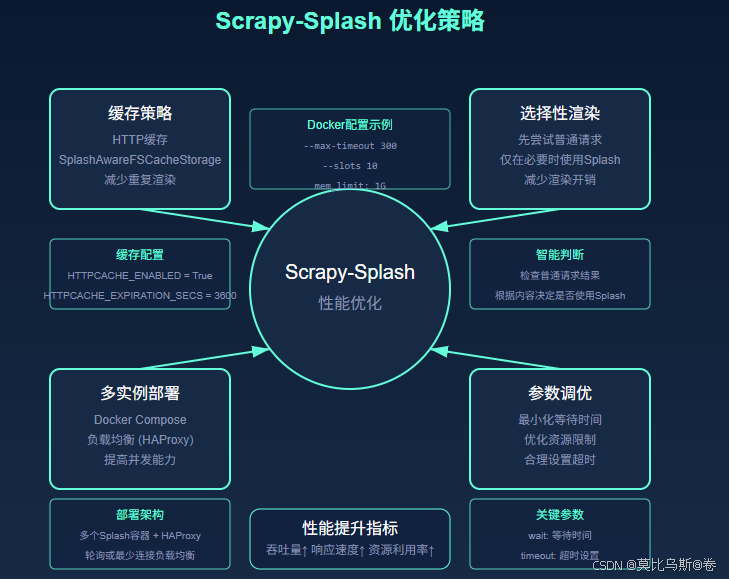
六、大规模部署
6.1 Docker Compose部署
对于大规模爬虫,可以使用Docker Compose管理多个Splash实例:
# docker-compose.yml
version: '3'
services:
splash-1:
image: scrapinghub/splash:latest
ports:
- "8050:8050"
restart: always
mem_limit: 1G
command: --max-timeout 300 --slots 10
splash-2:
image: scrapinghub/splash:latest
ports:
- "8051:8050"
restart: always
mem_limit: 1G
command: --max-timeout 300 --slots 10
splash-3:
image: scrapinghub/splash:latest
ports:
- "8052:8050"
restart: always
mem_limit: 1G
command: --max-timeout 300 --slots 10
splash-haproxy:
image: haproxy:latest
ports:
- "8030:8030"
volumes:
- ./haproxy.cfg:/usr/local/etc/haproxy/haproxy.cfg:ro
depends_on:
- splash-1
- splash-2
- splash-3
配置HAProxy负载均衡:
# haproxy.cfg
global
maxconn 4096
defaults
mode http
timeout connect 5s
timeout client 50s
timeout server 50s
frontend splash_frontend
bind *:8030
default_backend splash_backend
backend splash_backend
balance roundrobin
option httpchk GET /
server splash1 splash-1:8050 check
server splash2 splash-2:8050 check
server splash3 splash-3:8050 check
然后在Scrapy设置中使用HAProxy地址:
SPLASH_URL = 'http://splash-haproxy:8030'
6.2 监控与维护
设置监控确保Splash服务健康运行:
- 健康检查:定期检查Splash服务状态
- 资源监控:监控CPU、内存使用情况
- 自动重启:配置Docker自动重启崩溃的容器
- 日志收集:集中收集和分析日志
结语
Scrapy-Splash为爬取JavaScript渲染的网页提供了强大而灵活的解决方案。通过本文的介绍,你应该已经掌握了从基本配置到高级应用的完整知识,能够应对各种动态网页爬取挑战。
与Selenium等重量级浏览器自动化工具相比,Scrapy-Splash更轻量、更适合大规模爬虫部署。当然,它也有局限性,例如对某些复杂JavaScript框架的支持可能不如完整的浏览器。在这种情况下,你可能需要考虑Scrapy-Selenium或Scrapy-Playwright等替代方案。
最后,请记住合法合规地使用爬虫技术,尊重网站的robots.txt规则和使用条款,避免给目标网站带来过大负担。
参考资料
- Scrapy-Splash官方文档:https://github.com/scrapy-plugins/scrapy-splash
- Splash官方文档:https://splash.readthedocs.io/
- Scrapy官方文档:https://docs.scrapy.org/
- Docker官方文档:https://docs.docker.com/
健康检查:定期检查Splash服务状态 - 资源监控:监控CPU、内存使用情况
- 自动重启:配置Docker自动重启崩溃的容器
- 日志收集:集中收集和分析日志
结语
Scrapy-Splash为爬取JavaScript渲染的网页提供了强大而灵活的解决方案。通过本文的介绍,你应该已经掌握了从基本配置到高级应用的完整知识,能够应对各种动态网页爬取挑战。
与Selenium等重量级浏览器自动化工具相比,Scrapy-Splash更轻量、更适合大规模爬虫部署。当然,它也有局限性,例如对某些复杂JavaScript框架的支持可能不如完整的浏览器。在这种情况下,你可能需要考虑Scrapy-Selenium或Scrapy-Playwright等替代方案。
最后,请记住合法合规地使用爬虫技术,尊重网站的robots.txt规则和使用条款,避免给目标网站带来过大负担。
参考资料
- Scrapy-Splash官方文档:https://github.com/scrapy-plugins/scrapy-splash
- Splash官方文档:https://splash.readthedocs.io/
- Scrapy官方文档:https://docs.scrapy.org/
- Docker官方文档:https://docs.docker.com/
- HAProxy文档:http://www.haproxy.org/#docs




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











