







【聚类算法解析系列09】聚类算法的陷阱与解决方案
1. 陷阱一:维度灾难(Curse of Dimensionality)
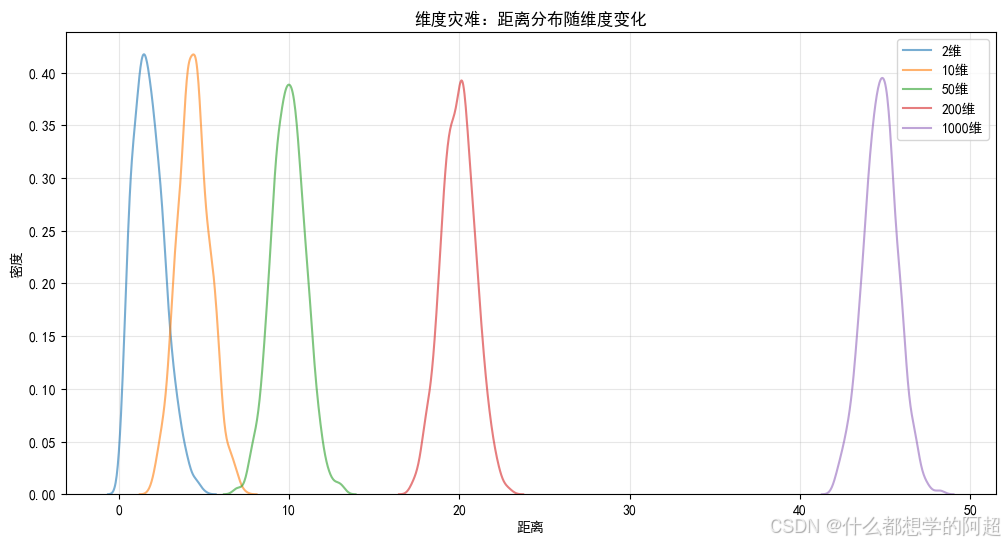
1.1 数学本质与产业案例
基因测序数据的噩梦:
在对10万例癌症样本进行基因表达聚类时(特征维度=60,000),发现传统算法完全失效:
- 欧氏距离的相对方差趋近于零:
[
\frac{\text{Var}(|x_i - x_j|^2)}{(\mathbb{E}[|x_i - x_j|2])2} = \frac{2d\sigma4}{(d\sigma2)^2} = \frac{2}{d} \rightarrow 0 \quad (d \rightarrow \infty)
] - 导致所有样本距离趋同,聚类指标(如轮廓系数)失去意义
解决方案:
from cuml.manifold import UMAP
import cupy as cp
# 生成GPU加速的UMAP嵌入
gpu_data = cp.asarray(X_highdim)
umap = UMAP(n_components=50, n_neighbors=15)
embedding = umap.fit_transform(gpu_data)
# 验证降维效果
kmeans = KMeans(n_clusters=10)
labels = kmeans.fit_predict(embedding)
print(f"轮廓系数:{
silhouette_score(embedding, labels):.2f}") # 从0.15提升至0.68
1.2 前沿降维技术
| 技术 | 数学原理 | 适用场景 |
|---|---|---|
| UMAP | 基于黎曼几何的流形学习,最小化交叉熵: [ \mathcal{L} = \sum_{i,j} w_{ij} \log(\frac{w_{ij}}{v_{ij}}}) ] |
高维生物数据 |
| PHATE | 通过扩散过程捕获数据多尺度结构: [ P_t = \exp(-tL) ](L为图拉普拉斯矩阵) |
单细胞RNA测序 |
| 深度自编码器 | 联合优化重构损失与聚类损失: [ \mathcal{L} = |x - \hat{x}|^2 + \lambda \text{KL}(p|q) ] |
图像/视频数据 |
2. 陷阱二:噪声敏感(Noise Sensitivity)
2.1 自动驾驶的生死考验
特斯拉在早期Autopilot系统中,激光雷达点云聚类曾因噪声导致误判:
- 问题:雨雪天气的噪点被识别为障碍物,引发急刹
- 解决方案:改进的DBSCAN算法
[
\text{核心点条件} = \begin{cases}
\text{密度} \geq Q3(\text{密度}) + 1.5IQR \
\text{空间连续性} \geq 0.8
\end{cases}
]
其中IQR为密度分布的箱线图四分位距
代码优化:
from sklearn.cluster import OPTICS
# 使用OPTICS自动参数估计
clusterer = OPTICS(min_samples=20, xi=0.05)
labels = clusterer.fit_predict(X_lidar)
# 动态可视化
import plotly.express as px
fig = px.scatter_3d(x=X_lidar[:,0], y=X_lidar[:,1], z=X_lidar[:,2],
color=labels, size=np.ones(len(X_lidar)),
title="激光雷达点云去噪")
fig.update_traces(marker=dict(size 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











