




 本文介绍了使用Python进行高考成绩查询的爬虫技巧,包括通过F12开发者模式观察网络请求,验证请求正确性,模拟发送请求,处理headers以避免反爬虫,以及利用etree和xpath解析HTML内容。特别提到了如何使用.xpath()方法获取包含特定class的div标签内容,并给出了模拟登录知乎的参考代码。
本文介绍了使用Python进行高考成绩查询的爬虫技巧,包括通过F12开发者模式观察网络请求,验证请求正确性,模拟发送请求,处理headers以避免反爬虫,以及利用etree和xpath解析HTML内容。特别提到了如何使用.xpath()方法获取包含特定class的div标签内容,并给出了模拟登录知乎的参考代码。
文章目录
F12开发者模式
打开谷歌浏览器,F12进入后观察network部分
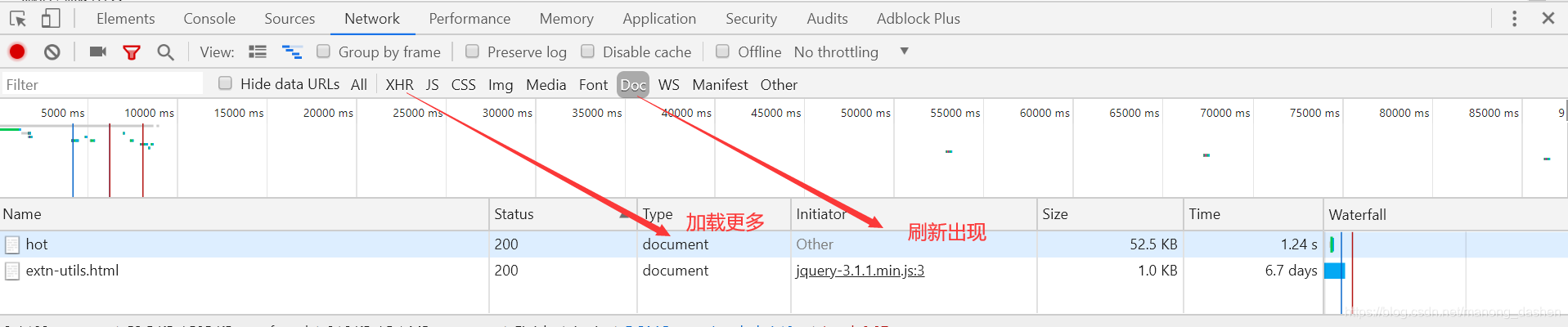
如何找到network中我们需要的部分
如果是按F5刷新才出来的,一般在DOC里面
如果是点击按钮加载更多,请求在XHR里面
如何验证请求正确
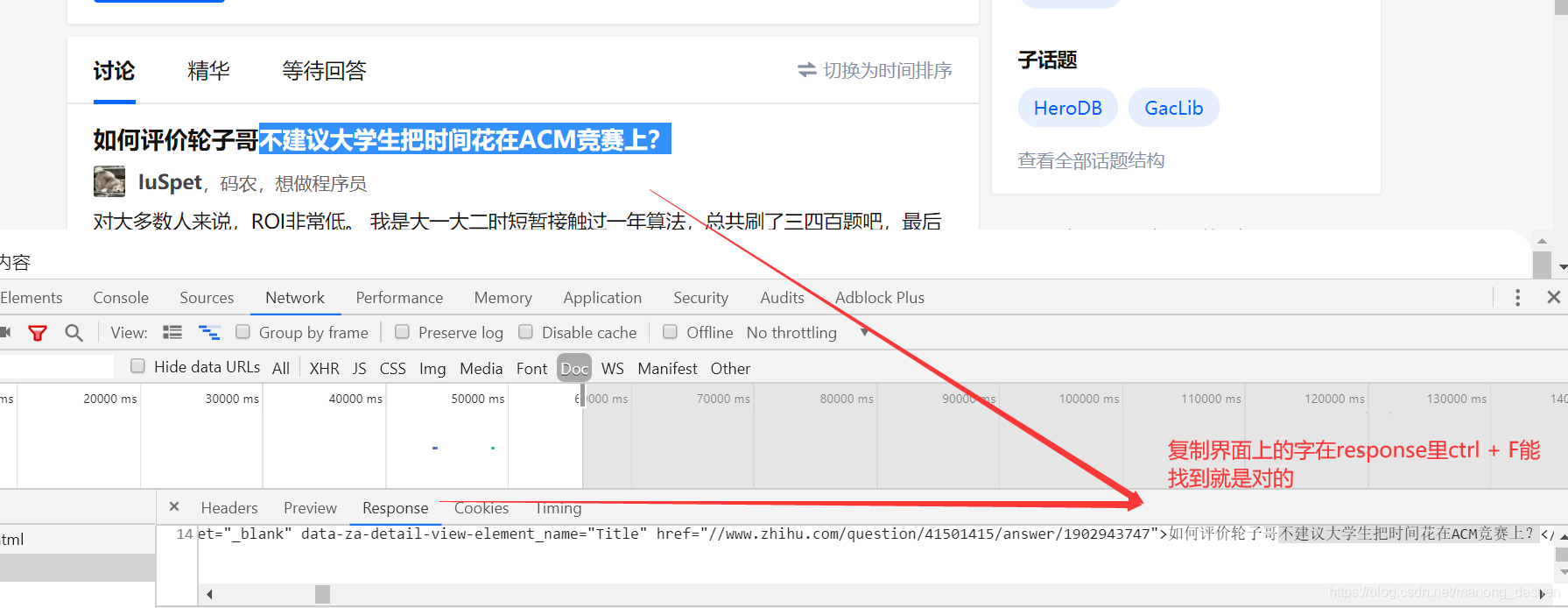
复制页面上的字,在response里ctrl+F查找,能找到说明找对了位置
模拟发送
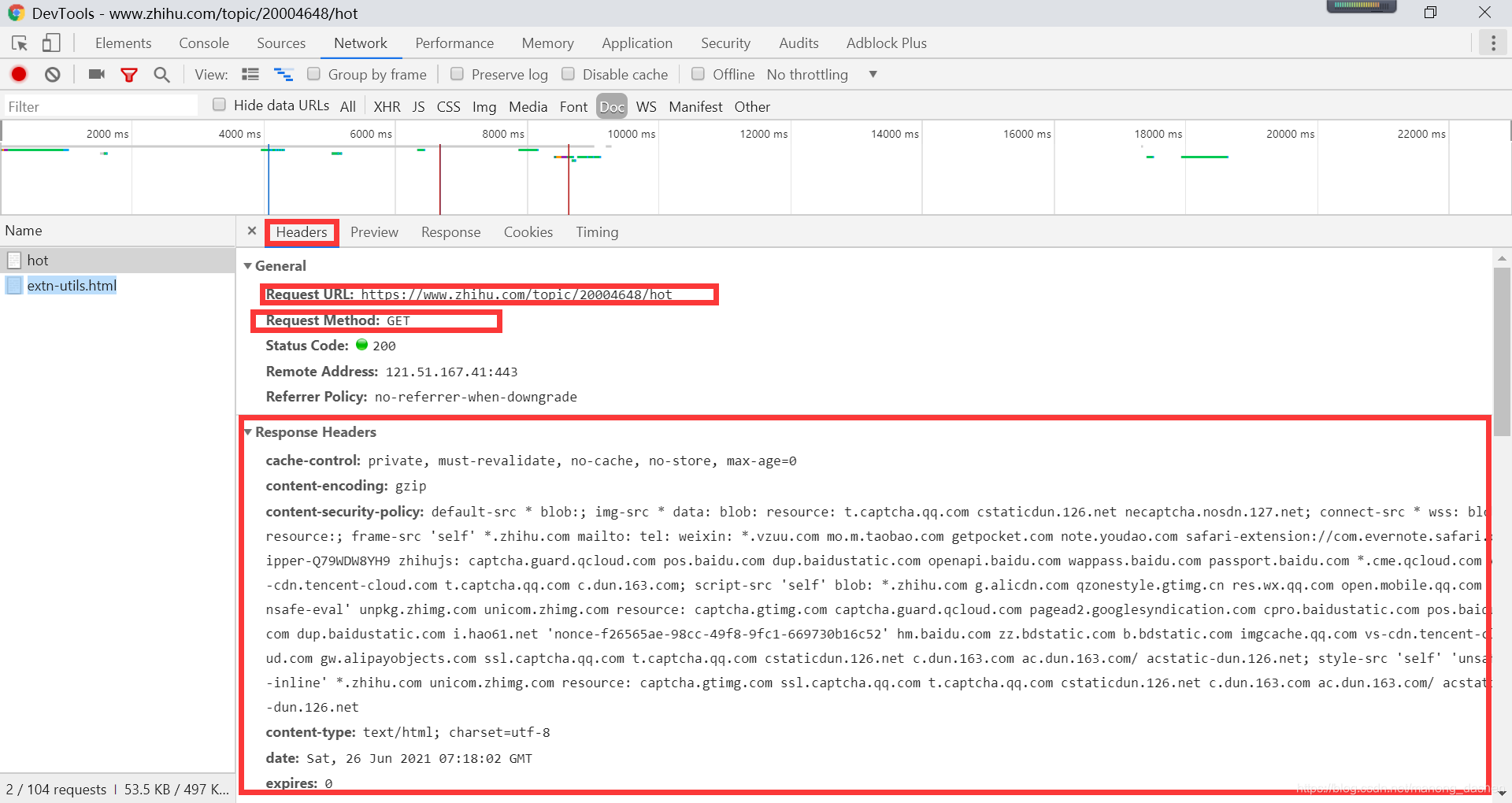
找到 url 方法以及 header
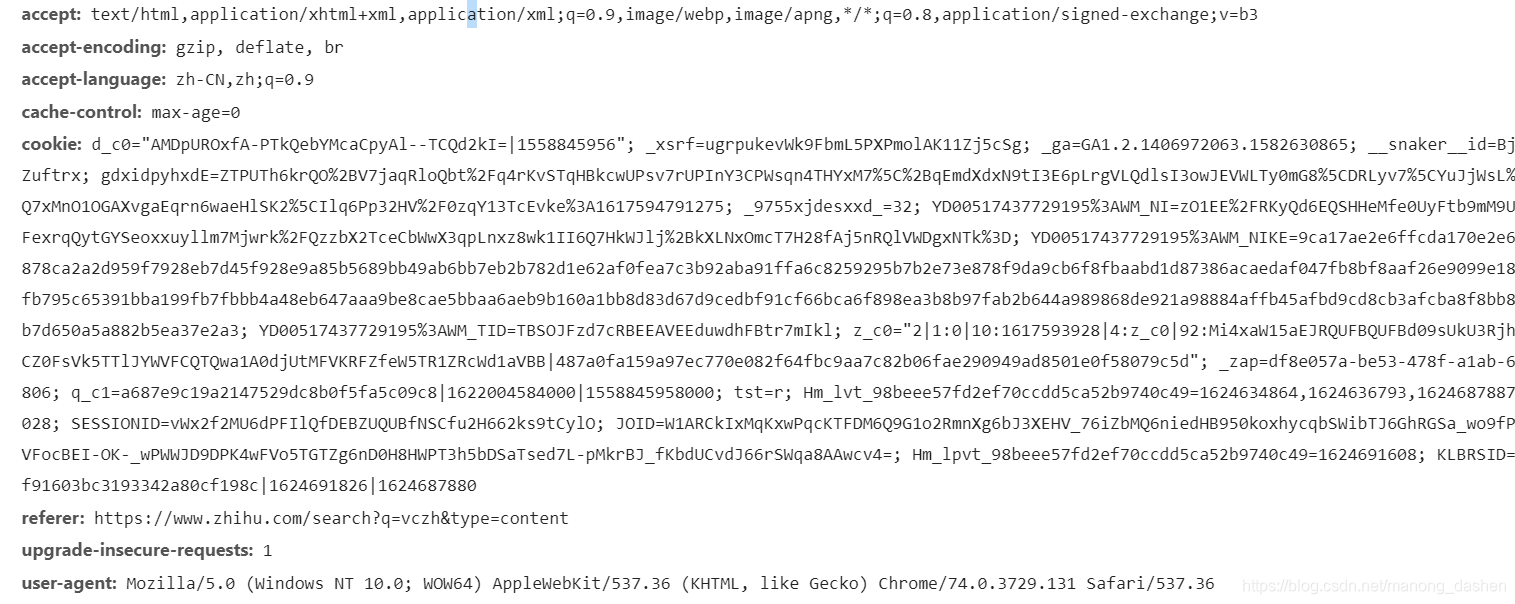
从 accept 到 user-agent 全都要,cookie 在程序中可以写空
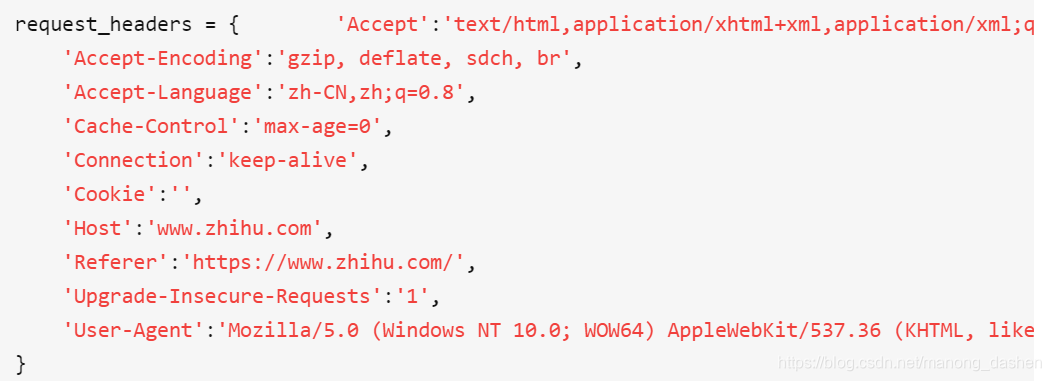
首字母大写,逗号连接
requests_headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Accept-encoding': 'gzip, deflate, br',
'Accept-language': 'zh-CN,zh;q=0.9',
'Cache-control':'max-age=0',
'Cookie': '',
'Referer': 'https://www.zhihu.com/search?q=vczh&type=content',
'Upgrade-insecure-requests': '1',
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
}
url = 'https://www.zhihu.com/topic/20004648/hot'
z = requests.get(url, headers=requests_headers)
print(z.content)
headers反爬虫
headers = {
'User - Agent': 'Mozilla / 5.0(Windows NT 6.1;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 73.0.3683.103Safari / 537.36'
}
response.status_code
如果数值是200说明请求被回应
etree 和 xpath
etre
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1038
1038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









