



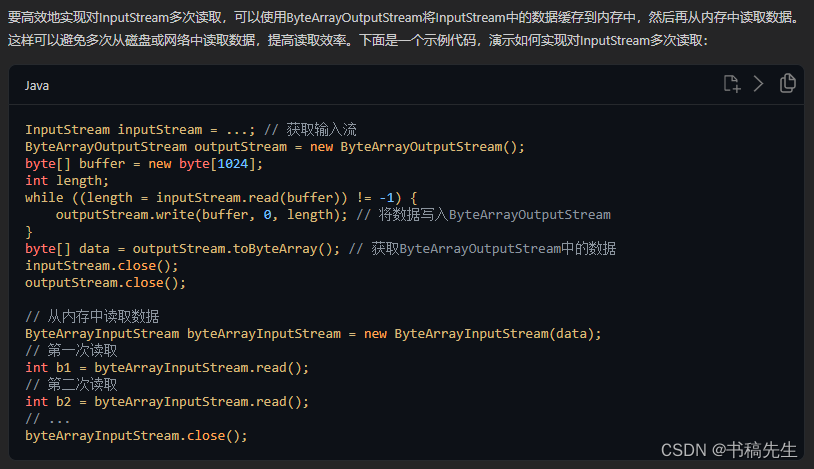
1.Java中,我如何高效实现对InputStream多次读取
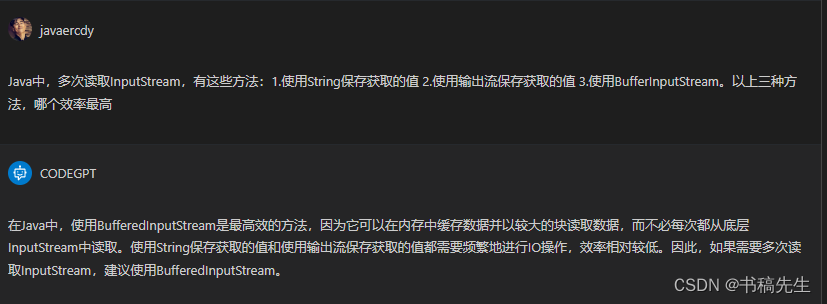
2.Java中,多次读取InputStream,有这些方法:1.使用String保存获取的值 2.使用输出流保存获取的值 3.使用BufferInputStream。以上三种方法,哪个效率最高
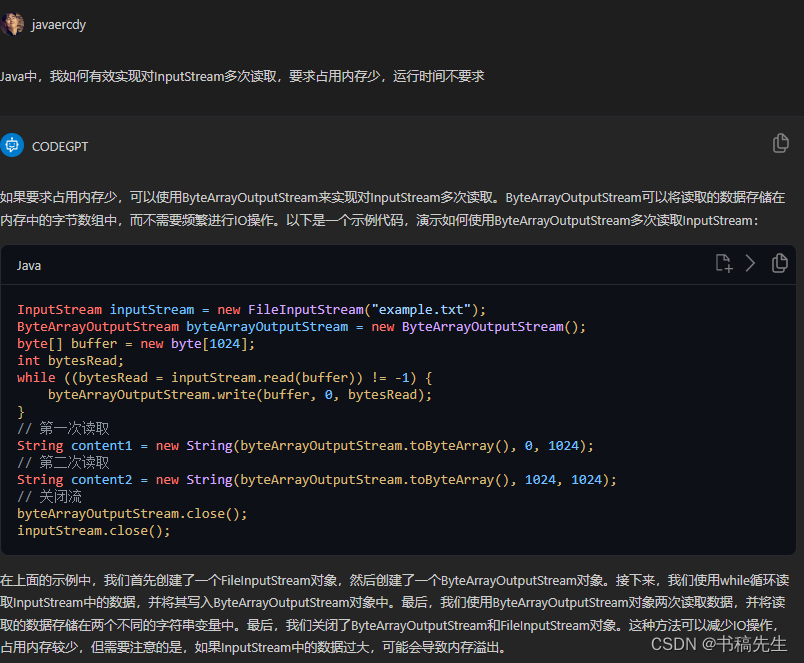
3.Java中,我如何有效实现对InputStream多次读取,要求占用内存少,运行时间不要求
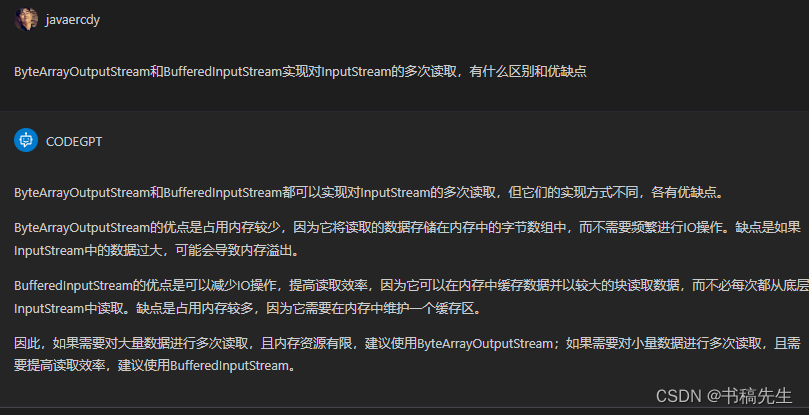
4.ByteArrayOutputStream和BufferedInputStream实现对InputStream的多次读取,有什么区别和优缺点
 JavaInputStream高效读取策略:内存优化与方法比较
JavaInputStream高效读取策略:内存优化与方法比较
 本文探讨了在Java中如何高效地多次读取InputStream,涉及String、输出流、BufferInputStream以及ByteArrayOutputStream和BufferedInputStream的使用,关注内存效率和运行时间。
本文探讨了在Java中如何高效地多次读取InputStream,涉及String、输出流、BufferInputStream以及ByteArrayOutputStream和BufferedInputStream的使用,关注内存效率和运行时间。
1.Java中,我如何高效实现对InputStream多次读取
2.Java中,多次读取InputStream,有这些方法:1.使用String保存获取的值 2.使用输出流保存获取的值 3.使用BufferInputStream。以上三种方法,哪个效率最高
3.Java中,我如何有效实现对InputStream多次读取,要求占用内存少,运行时间不要求
4.ByteArrayOutputStream和BufferedInputStream实现对InputStream的多次读取,有什么区别和优缺点


















 1407
1407




 到【灌水乐园】发言
到【灌水乐园】发言






