






 本文介绍了一种NLP领域的迁移学习方法,通过预训练语言模型并采用精调技巧,如Discriminative fine-tuning和Slanted triangular learning rates,有效避免了小数据集上的过拟合,同时在文本分类任务上保持了模型的泛化能力。
本文介绍了一种NLP领域的迁移学习方法,通过预训练语言模型并采用精调技巧,如Discriminative fine-tuning和Slanted triangular learning rates,有效避免了小数据集上的过拟合,同时在文本分类任务上保持了模型的泛化能力。
迁移学习在nlp领域的应用之pretrain language representation,四连载,建议按顺序看,看完对该方向一定会非常清楚的!
(一)ELMO:Deep contextualized word representations
(二)Universal Language Model Fine-tuning for Text Classification
(三)openAI GPT:Improving Language Understanding by Generative Pre-Training
(四)BERT: Pretraining of Deep Bidirectional Transformers for Language Understanding
一、问题描述
这是一篇18年的ACL文章。以前的nlp迁移学习,要么是使用task数据fine-tuning词向量(如glove这种),相当于更改模型的第一层,要么是将其他任务得到的词向量和本任务的输入concat起来,但其实这些pretrain的词向量都是被当做固定参数用的,且该任务的模型是从头训练的。因此出现了pretrain语言模型(language model),但是语言模型容易在小型数据上过拟合,且当训练分类器时容易忘记pretrain语言模型学到的知识,本文提出一种语言模型的精调(fine-tuning)技巧,用于nlp领域的迁移学习(transfer learning),并在6个文本分类任务上做验证。
二、语言模型及trick
整个模型框架分为三个阶段:
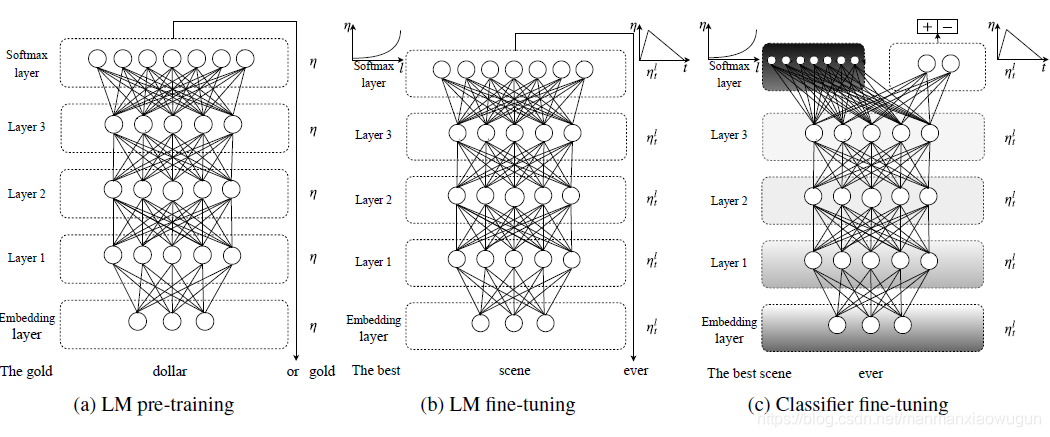
a) LM pre-training。在该阶段就是包含大量各种domain中的数据(如wikitext)进行预训练语言模型; 语言模型是指3层的单向LSTM(双向后面会讲),这里LSTM的小细节(无attention、有一些dropout超参数)来源于AWD-LSTM(有兴趣可百度)
b) LM fine-tuning。在该阶段就是是使用目标domain中的数据进行语言模型的fine-tuning操作,但是作者在该阶段fine-tuning的时候采用了2种策略:
Discriminative fine-tuning,即对layer1,layer2和layer3采用不同的学习速率,layer3是最后一层学习速率为,那么layer2 的学习速率就是
,layer3的学习速率就是
;
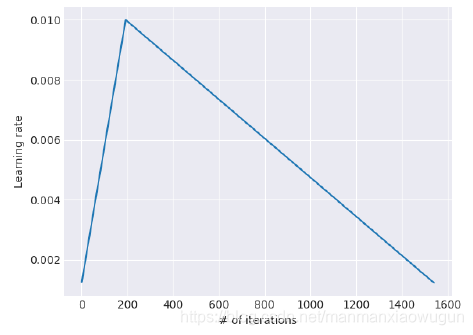
Slanted triangular learning rates,学习率不断下降未必是好事,需要先增后降。即每一个iteration都会对学习速率有一个修正(iteration和epoch不一样,一个iteration是一次参数的更新,相当于一个batch),具体的修正公式如下:
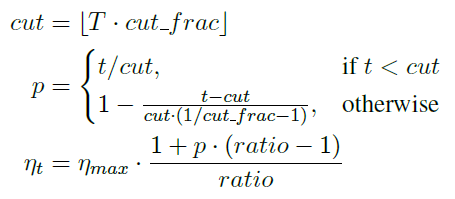
其中,是总的迭代次数,
是当前的迭代次数,
是转折比例,
是最大的学习速率,
是最大和最小学习率的差值。整个学习速率的图像如下所示:
c) Classifier fine-tuning。在该阶段就是使用domain中的有标注数据进行分类器的训练,就是把layer3的LSTM的输出变量进行一系列的变换操作,最后输入分类器的形式就是 ,
就是最后一时刻的输出向量,分类器为两个线性block,每个线性block包含(batch normalization,dropout,ReLU),最后跟一个softmax输出属于某一类的概率。对于每个任务来说,这两个线性block和softmax都是从头训练的。那么在对分类器进行训练的时候,除了Discriminative fine-tuning和Slanted triangular learning rates技术。为了避免全部fine-tuning导致语言模型对之前学到的general知识的遗忘,引入
Gradual unfreezing,从后往前(从layer3到layer1方向)逐步的添加。先只把最后一层解冻,接下来就把一个多余的网络层加入到解冻集合中去。由于后面的网络更多的是specific信息,前面的网络包含的更多general信息,这样的方式可以最大的幅度保存(a)、(b)阶段学习到的信息。
BPTT for Text Classification,为了当输入文本很长时,可以较好的fine-tuning分类器,将文档拆成几个batch,每个batch的长度是一致的,哪一个batch促成了最后的preciction,就反向传播给哪个batch(具体操作还需看一下代码)。
双向语言模型,使用两个单向语言模型(一个forward,一个backward),进行分类,最后取平均结果。
三、存在疑问
1. inductive transfer learning和transductive transfer learning的区别?
参考网址:https://blog.youkuaiyun.com/guoyuhaoaaa/article/details/80805223

















 887
887





 到【灌水乐园】发言
到【灌水乐园】发言







