




一、引入
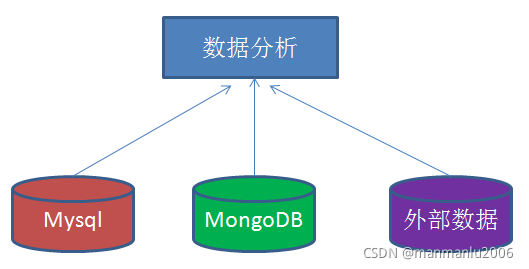
问题:需要对各种数据源(MySQL、MongoDB、第三方数据)进行整合汇总分析时
一个故事
在很久很久以前,世界上生活着许多种族,有人类,有矮人,有精灵......他们有着不同的信仰,不同的文化,彼此相安无事。可是,有一个猥琐男却偏偏想要统治整个世界。
如何统治这么多不同文化信仰的种族呢?猥琐男想出一个馊主意,打造出几枚拥有魔力的戒指,免费送给不同种族的领袖,让他们可以更好地统治各自的族人。

当各个种族的领袖美滋滋地戴上各自的魔戒,走上人生巅峰的时候,猥琐男又打造出一枚独一无二的至尊魔戒。他利用至尊魔戒的力量控制了所有的魔戒,从而控制了各个种族的领袖,继而控制了整个世界。

这个故事告诉我们:数据库和数据仓库之间的关系。
如果说,那个世界的每一个生命个体都是一条数据记录,那么普通的魔戒的地位就好比是数据库,而至尊魔戒的地位就好比是数据仓库。
二、数据仓库
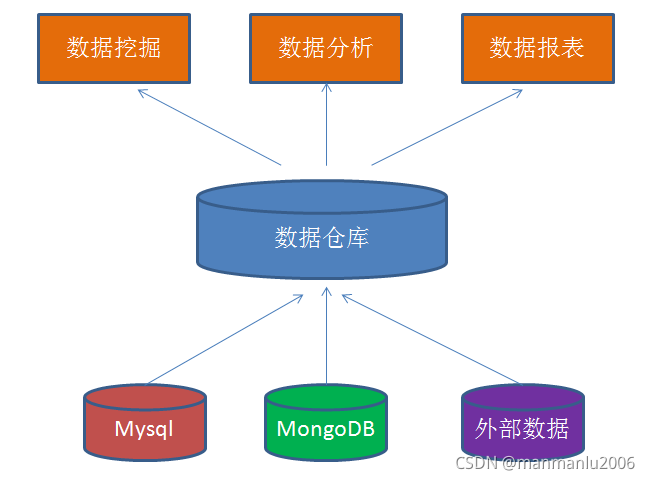
数据仓库,英文名称Data Warehouse,简写为DW。数据仓库顾名思义,是一个很大的数据存储集合,出于企业的分析性报告和决策支持目的而创建,对多样的业务数据进行筛选与整合。
数据仓库的输入方是各种各样的数据源,最终的输出用于企业的数据分析、数据挖掘、数据报表等方向。
特点:
1.主题性:将不同数据源的数据在一个较高的抽象层次上做整合,所有数据都围绕某一主题来组织。
2.集成性:来自不同的数据源,存储方式各不相同。要整合成为最终的数据集合,需要从数据源经过一系列抽取、清洗、转换的过程。
3.稳定性:保存的数据是一系列历史快照,不允许被修改。
4.时变性 :定期接收新的集成数据,反应出最新的数据变化
三、如何集成不同的数据源

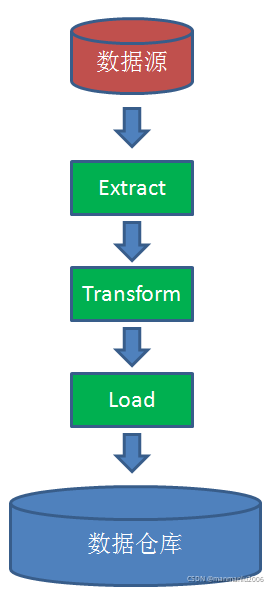
ETL的英文全称是 Extract-Transform-Load 的缩写,用来描述将数据从来源迁移到目标的几个过程:
1.Extract,数据抽取,也就是把数据从数据源读出来。
2.Transform,数据转换,把原始数据转换成期望的格式和维度。如果用在数据仓库的场景下,Transform也包含数据清洗,清洗掉噪音数据。
3.Load 数据加载,把处理后的数据加载到目标处,比如数据仓库。
在国内最常用的,是基于hadoop的开源数据仓库,即:Hive
四、Hive

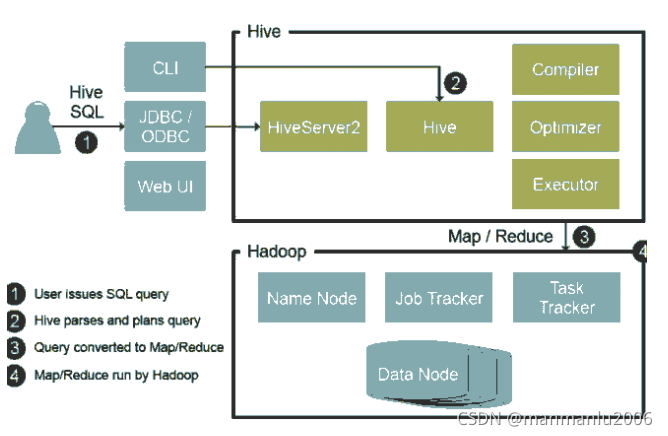
Hive是基于Hadoop的数据仓库工具,可以对存储在HDFS上的文件数据集进行查询和分析处理。Hive对外提供了类似于SQL语言的查询语言 HiveQL,在做查询时将HQL语句转换成MapReduce任务,在Hadoop层进行执行。
Hive 其实是一个客户端,类似于navcat、plsql 这种,不同的是Hive 是读取 HDFS 上的数据,作为离线查询使用,离线就意味着速度很慢,有可能跑一个任务需要几个小时甚至更长时间都有可能。

Teradata数据仓库配备性能最高、最可靠的大规模并行处理 (MPP) 平台,能够高速处理海量数据,其性能远远高于Hive。
它使得企业可以专注于业务,无需花费大量精力管理技术,因而可以更加快速地做出明智的决策,实现 ROI(投资回报率) 最大化。但是价格昂贵。
五、原理
01 Hive 查询原理
Hive 其实是将 hql 转成 MR 程序去跑,这里我们不去深入底层了解到底是怎么转换的,就简单看下Hive查询过程:
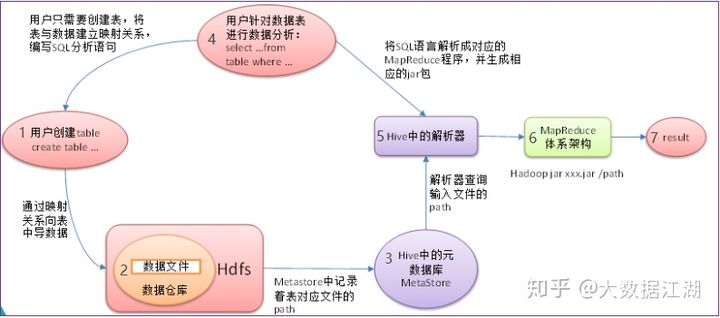
1 根据HDFS上数据格式,创建hive表
2 通过映射关系将HDFS数据导入到表中
3 此时hive表对应的元数据信息记录到 mysql 中,元数据可不是指的HDFS上的数据,它是指 hive 表的一些参数。
4 写 select 语句时,根据表与数据的映射关系去写对应的查询语句
5 在执行查询操作时 ,先从元数据库中找到 对应表对应的文件位置,
再通过 hive 的 解析器、编译器、优化器 执行器 将 sql 语句 转换成 MR 程序,运行在 Yarn 上,最终得到结果。
参考:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









