




Key的操作命令
查找
- 语法:keys pattern
作用:查找所有符合模式pattern的key. pattern可以使用通配符。
通配符:
*:表示0或多个字符,例如:keys *查询所有的key。
?:表示单个字符,例如:wo?d , 匹配 word , wood
[ ]:表示选择[ ]内的一个字符,例如wo[or]d, 匹配word, wood, 不匹配wold、woord

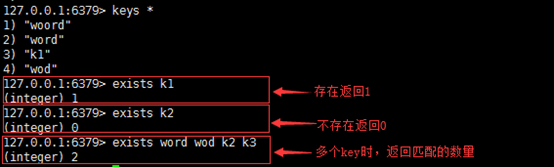
exists(判存)
- 语法:
exists key [key…] - 作用:判断key是否存在
返回值:整数,存在key返回1,其他返回0。使用多个key,返回存在的key的数量。
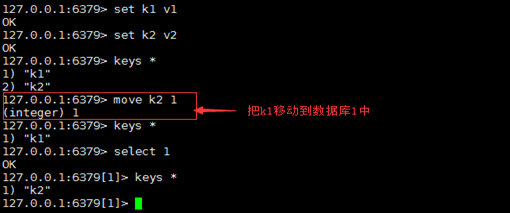
move(移动)
- 语法:
move key db - 作用:移动key到指定的数据库,移动的key在原库被删除。
返回值:移动成功返回1,失败返回0.
ttl(查看剩余生存时间)
- 语法:
ttl key - 作用:查看key的剩余生存时间(ttl: time to live),以秒为单位。
返回值:
-1 :没有设置key的生存时间, key永不过期。
-2:key不存在

expire(设置生存时间)
- 语法:
expire key seconds - 作用:设置key的生存时间,超过时间,key自动删除。单位是秒。
返回值:设置成功返回数字 1,其他情况是 0 。

type(查看key存储的类型)
语法:type key
作用:查看 key所存储值的 数据类型
返回值:字符串表示的数据类型
none (key不存在)
string (字符串)
list (列表)
set (集合)
zset (有序集)
hash (哈希表)

rename(更改key名)
语法:rename key newkey
作用:将key改为名newkey。当 key 和 newkey 相同,或者 key 不存在时,返回一个错误。
当 newkey 已经存在时, RENAME 命令将覆盖旧值。
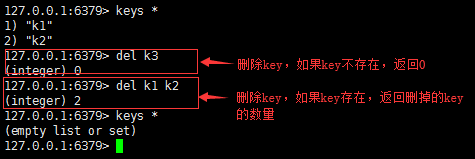
del(删除)
语法:del key [key…]
作用:删除存在的key,不存在的key忽略。
返回值:数字,删除的key的数量。

















 1803
1803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









