




 本文介绍了一个珠宝选择问题的解决方法,旨在帮助一位女士在有限的珠宝中选择价值重量比最高的几种进行保留。通过迭代的方式不断优化选择组合,最终达到价值重量比的最大化。
本文介绍了一个珠宝选择问题的解决方法,旨在帮助一位女士在有限的珠宝中选择价值重量比最高的几种进行保留。通过迭代的方式不断优化选择组合,最终达到价值重量比的最大化。
Description
Demy has n jewels. Each of her jewels has some value vi and weight wi .
Since her husband John got broke after recent financial crises, Demy has decided to sell some jewels. She has decided that she would keep k best jewels for herself. She decided to keep such jewels that their specific value is as large as possible. That is, denote the specific value of some set of jewels S = {i 1 , i 2 , …, ik } as
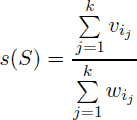 .
.
Demy would like to select such k jewels that their specific value is maximal possible. Help her to do so.
Input
The first line of the input file contains n — the number of jewels Demy got, and k — the number of jewels she would like to keep (1 ≤ k ≤ n ≤ 100 000).
The following n lines contain two integer numbers each — vi and wi (0 ≤ vi ≤ 106 , 1 ≤ wi ≤ 106 , both the sum of all vi and the sum of all wi do not exceed 107 ).
Output
Output k numbers — the numbers of jewels Demy must keep. If there are several solutions, output any one.
Sample Input
3 2
1 1
1 2
1 3
Sample Output
1 2
这道题的迭代方法我真是不会,希望能通过作越来越多的题突破瓶颈,sigh
假设已有的v/w,其中v和w是k个的总和。那么要得到更好的v/w,做法是,求出每一个对于的si,si= vi-wi*v/w
很容易就能证明si更大的k个,可以组成不比原来小的组合。 设前k个si之和为s;(s最大,如果s>0,迭代没有停止),v/w = (v1-s)/w1<=v1/w1;

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









