




逻辑回归 (Logistic Regression)
1)假设表示
逻辑回归模型的假设是:hθ(x)=g(θTX)h_\theta(x)=g(\theta^TX)hθ(x)=g(θTX),它的输出值永远在0到 1 之间。
其中:
X代表特征向量
g代表逻辑函数(logistic function)是一个常用的逻辑函数为S形函数(Sigmoid function),公式为:g(z)=11+e−zg(z) = \frac{1}{1+e^{-z}}g(z)=1+e−z1 。
hθ(x)h_\theta(x)hθ(x)的作用是,对于给定的输入变量,根据选择的参数计算其输出为1的可能性→hθ(z)=P(y=1∣x;θh_\theta(z)=P(y=1|x;\thetahθ(z)=P(y=1∣x;θ)
Python代码实现:
import numpy as np
def sigmoid(z):
return 1/(1+np.exp(-z))
sigmoid函数图像

2)决策边界
在逻辑回归中有:
当 hθ(x)>=0.5h_\theta(x)>=0.5hθ(x)>=0.5 时,预测 y=1y=1y=1;当 hθ(x)<0.5h_\theta(x)<0.5hθ(x)<0.5 时,预测 y=0y=0y=0
由 g(z)=11+e−zg(z) = \frac{1}{1+e^{-z}}g(z)=1+e−z1 有:
z>0z>0z>0 时,g(z)>0.5g(z) >0.5g(z)>0.5;z=0z=0z=0 时,g(z)=0.5g(z) =0.5g(z)=0.5;z<0z<0z<0 时,g(z)<0.5g(z) <0.5g(z)<0.5
又因为z=θTxz=\theta^Txz=θTx,所以有:
θTx>=0,y=1\theta^Tx >=0,y=1θTx>=0,y=1;θTx<0,y=0\theta^Tx <0,y=0θTx<0,y=0
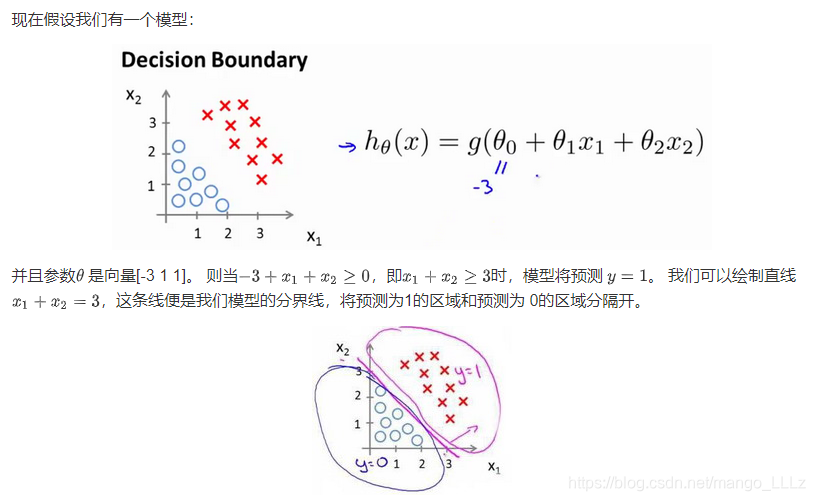
3)代价函数
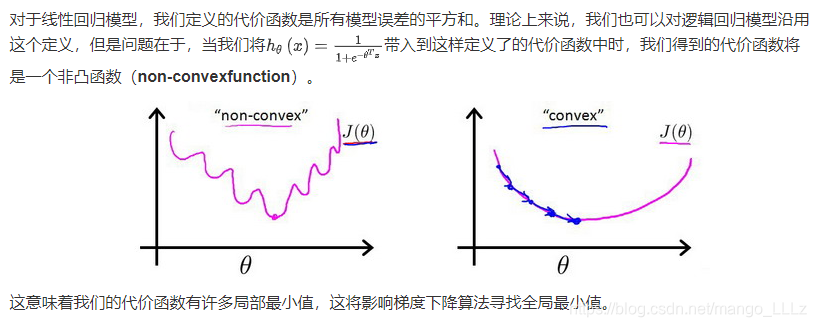
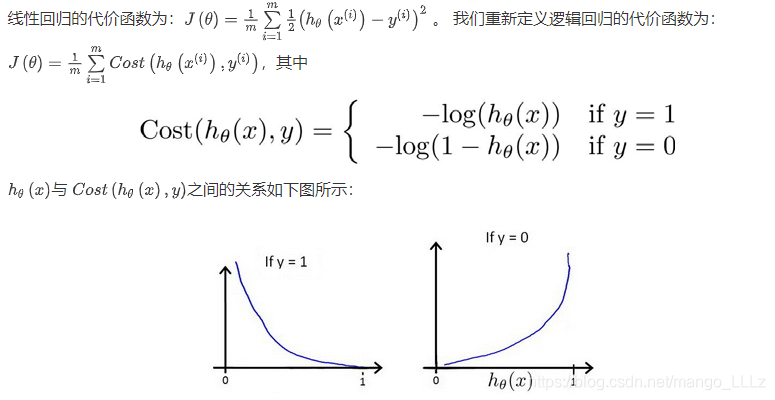
Cost函数简化如下:
Cost(hθ(x),y)=−ylog(hθ(x))−(1−y)log(1−hθ(x))Cost(h_\theta(x),y) = -ylog(h_\theta(x))-(1-y)log(1-h_\theta(x))Cost(hθ(x),y)=−ylog(hθ(x))−(1−y)log(1−hθ(x))
代入代价函数得:
J(θ)=1m∑i=1n[−y(i)log(hθ(x(i)))−(1−y(i))log(1−hθ(x(i)))]J(\theta)=\frac{1}{m}\sum_{i=1}^{n}[ -y^{(i)}log(h_\theta(x^{(i)}))-(1-y^{(i)})log(1-h_\theta(x^{(i)}))]J(θ)=m1∑i=1n[−y(i)log(hθ(x(i)))−(1−y(i))log(1−hθ(x(i)))]
Python代码实现:
import numpy as np
def cost(theta,X,y):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
m = len(X)
h = sigmoid(X*theta.T)
# np.multiply 矩阵对应元素位置相乘
J = np.sum(np.multiply(-y,np.log(h))-np.multiply(1-y,np.log(1-h))) / m
return J

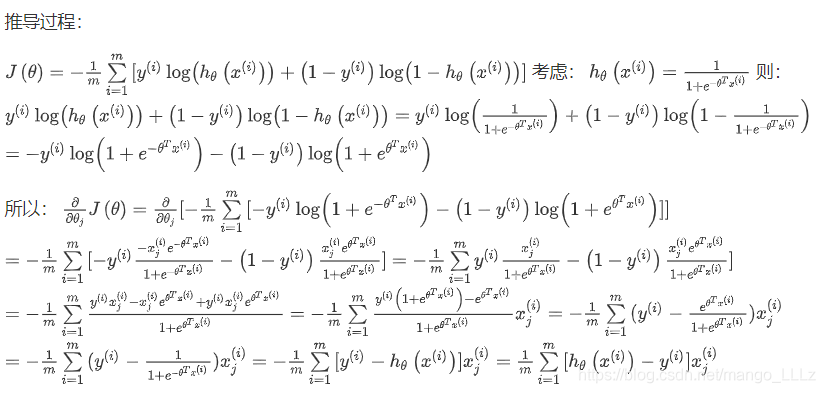
除了梯度下降算法以外,还有一些常被用来令代价函数最小的算法,这些算法更加复杂和优越,而且通常不需要人工选择学习率,通常比梯度下降算法要更加快速。这些算法有:共轭梯度(Conjugate Gradient),局部优化法(Broyden fletcher goldfarb shann,BFGS) 和 有限内存局部优化法(LBFGS)
4)正则化
给代价函数增加一个正则化的表达式,得到代价函数:
J(θ)=1m∑i=1m[−y(i)log(hθ(x(i)))−(1−y(i))og(1−hθ(x(i))log(1−hθ(x(i)))]+λ2m∑j=1nθj2J(\theta) =\frac{1}{m}\sum_{i=1}^{m}[-y^{(i)}log(h_\theta(x^{(i)}))-(1-y^{(i)})og(1-h_\theta(x^{(i)})log(1-h_\theta(x^{(i)}))]+\frac{\lambda}{2m}\sum_{j=1}^n\theta_j^2J(θ)=m1∑i=1m[−y(i)log(hθ(x(i)))−(1−y(i))og(1−hθ(x(i))log(1−hθ(x(i)))]+2mλ∑j=1nθj2
注意:θ0\theta_0θ0不正则化
通过梯度下降算法求导,得出梯度为:
θ0:=θ0−a1m∑i=1m((hθ(x(i))−y(i))x0(i)){\theta_0}:={\theta_0}-a\frac{1}{m}\sum\limits_{i=1}^{m}{(({h_\theta}({{x}^{(i)}})-{{y}^{(i)}})x_{0}^{(i)}})θ0:=θ0−am1i=1∑m((hθ(x(i))−y(i))x0(i))
θj:=θj−a[1m∑i=1m(hθ(x(i))−y(i))xj(i)+λmθj]{\theta_j}:={\theta_j}-a[\frac{1}{m}\sum\limits_{i=1}^{m}{({h_\theta}({{x}^{(i)}})-{{y}^{(i)}})x_{j}^{\left( i \right)}}+\frac{\lambda }{m}{\theta_j}]θj:=θj−a[m1i=1∑m(hθ(x(i))−y(i))xj(i)+mλθj]


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









