







参考资料:学习R
3、排序
把数值数据按大小进行排序通常很有用,sort函数按向量从小到大(或从大到小)排序。
x<-c(2,32,4,16,8)
sort(x)
sort(x,decreasing = TRUE)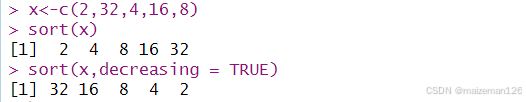
字符串也可以排序,通常字母从a到z排序:
y<-c("I","shot","the","city","sheriff")
sort(y)
order函数是sort函数的某种逆转操作。order中的第i个元素是x中的元素在排序之后最终将出现的位置。这种说法有点令人头晕,你需要了解的是:x[order(x)]将返回与sort(x)相同的结果。
x
order(x)
x[order(x)]
sort(x)
identical(sort(x),x[order(x)])

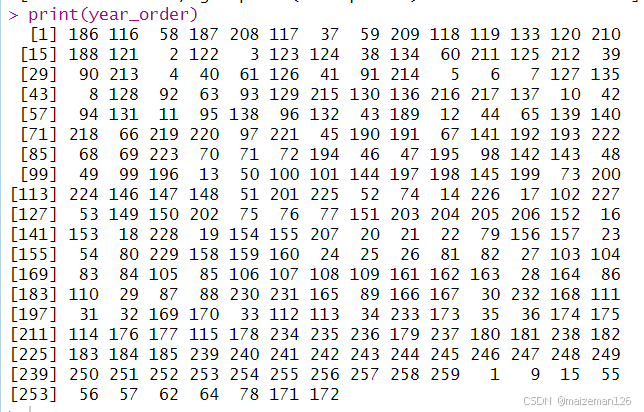
order在对数据框排序时很有用,因为数据框不能直接使用sort:
year_order<-order(english_monarchs$start.of.reign)
english_monarchs[year_order,]

plyr包中的arrange函数提供了一个替代函数,它只用一行就能对数据框排序:
library(plyr)
arrange(english_monarchs,start.of.reign)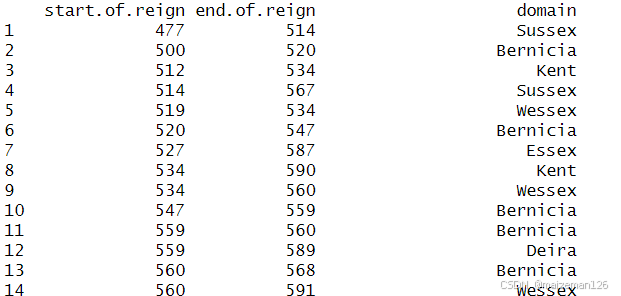
rank函数为数据集中每个元素给出了排名,提供了排名情况相等时的几种处理方法:
x<-sample(3,7,replace=TRUE)
print(x)
rank(x)
rank(x,ties.method="first")
4、函数式编程
Negate函数是接受一个谓词(即一个返回逻辑向量的函数)并返回一个刚好相反的谓词。当输入是FALSE时,则返回TRUE。
ct2<-deer_endocranial_volume$VolCT2
isnt.na<-Negate(is.na)
identical(isnt.na(ct2),!is.na(ct2))
Filter可以接受两个参数:第一个参数为返回一个逻辑向量的函数,第二个参数是一个输入向量,它只有在函数返回为TRUE时才会返回那些值:
Position函数的行为向which函数。它将返回第一个把谓词应用于矢量上而返回TRUE的索引下标。
Find与Position类似,但它返回的是第一个值而不是第一个索引。
ct2
Filter(isnt.na,ct2)
Position(isnt.na,ct2)
Find(isnt.na,ct2)
Map函数将一个函数应用于输入参数中的每个元素上。它只是使用了SIMPLIFY=FALSE选项的mapply函数的封装函数。Map函数的行为和mapply一样:它接受一个函数作为第一个参数,然后其他所有的参数会逐个传递给它:
get_volume<-function(ct,bead,lwh,finarelli,ct2,bead2,lwh2){
# 如果有第二次测量,取平均值
if(!is.na(ct2)){
ct<-(ct+ct2)/2
bead<-(bead+bead2)/2
lwh<-(lwh+lwh2)/2
}
# 把lwh除以4,使它与其他测量结果看起
c(ct=ct,bead=bead,lwh.4=lwh/4,finarelli=finarelli)
}
measurements_by_deer<-with(
deer_endocranial_volume,
Map(
get_volume,
VolCT,
VolBead,
VolLWH,
VolFinarelli,
VolCT2,
VolBead2,
VolLWH2
)
)
head(measurements_by_deer)

Reduce函数能把一个二元函数转变为接受多个输入的函数。例如,+运算符能计算两个数据字典的综合,但sum函数能计算多个输入的总和。sum(a,b,c,d,e)相当于Reduce("+",list(a,b,c,d,e))
我们可以定义一个简单的二元函数来计算两个输入值的最大值:
pmax2<-function(x,y) ifelse(x>=y,x,y)
Reduce(pmax2,measurements_by_deer)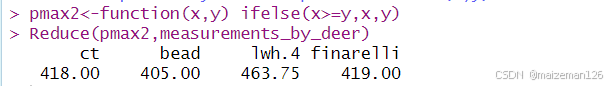
Reduce的一个限制条件是,它将对其输入成对地反复调用二元函数,也就是说:
Reduce("+", list(a, b, c, d, e))相当于((((a + b) + c) + d) + e)
这意味着,它不能用于例如求平均值这样的计算因为:
mean(mean(mean(mean(a, b), c), d), e) != mean(a, b, c, d, e)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









