







参考资料:学习R
1、创建因子
当我们用一列文本数据创建数据框时,R不再将文本默认为因子型了,需要进行人为的转换。
heights<-data.frame(
height_Cm=c(153,181,150,172,165,149,174,169,198,163),
gender=c("female","male","female","male","male",
"female","female","male","male","female")
)
heights
class(heights$gender)
heights$gender<-as.factor(heights$gender)
class(heights$gender)
heights$gender
因子中的每个值都是一个字符串,本例中它们被限制为"female"、"male"或缺失值。如果我们把不同的字符串添加到genders中,此项约束则变得很明显:
heights$gender[1]<-"Female"
heights$gender
这里的选项"female"和"male"被称为因子水平,它能用levels函数查询到。水平的级数(相当于level的length)可由nlevel函数查询到:
levels(heights$gender)
nlevels(heights$gender)
我们还可以使用factor函数创建因子。它的第一个参数(唯一的强制要求)必须是一个字符向量。
gender_char<-c(
"female","male","female","male","male",
"female","female","male","male","female"
)
gender_fac<-factor(gender_char)
gender_fac
2、更改因子水平
我们可以通过指定levels参数来更改因子被创建时水平的先后顺序(默认是按首字母先后顺序排序):
factor(gender_char,levels=c("male","female"))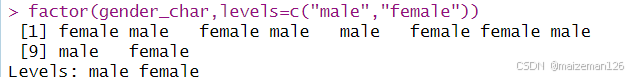
如果想在因子创建后再改变因子水平的顺序,就再次使用factor函数,这是它的参数是当前的因子(而不是字符向量):
factor(gender_fac,levels=c("male","female"))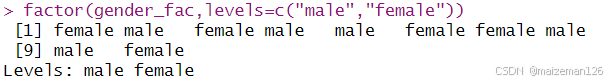
不能使用levels函数直接改变因子的水平,因为这将重新为每个水平打上标签,更改数据。在下例中,直接设置因子的水平会将数据中的male变成female,female变为male:
levels(gender_fac)<-c("male","female")
gender_fac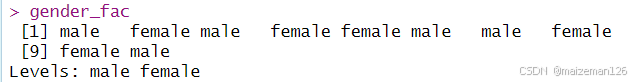
relevel函数是另一种改变因子水平顺序的方法。在这种情况下,我们只需指定第一个水平的值,但多数情况下,使用factor函数来设置水平值。
3、去掉因子水平
在数据集清理过程中,我们可能需要去掉所有与因子水平对应的数据。
getting_to_work<-data.frame(
mode=c(
"bike","car","bus","car","walk",
"bike","car","bike","car","car"
),
time_mins=c(25,13,NA,22,65,28,15,24,NA,14)
)
class(getting_to_work$mode)
getting_to_work$mode<-factor(getting_to_work$mode)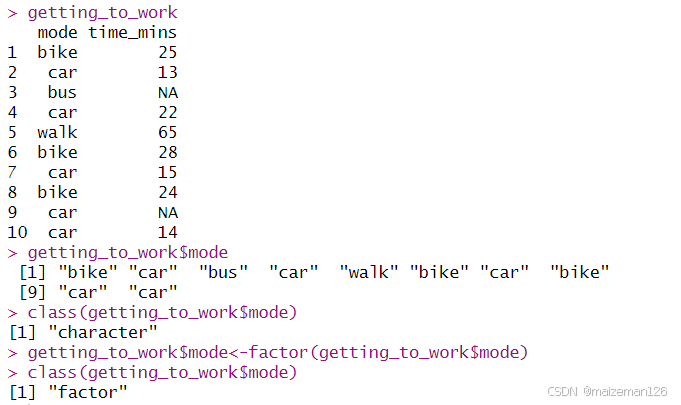
并非每次都有记录,所以我们的第一个任务是去掉time_mins是NA的行。我们可以看到mode列只有三个不同的值,而因子水平确实4个。
getting_to_work<-subset(getting_to_work,!is.na(time_mins))
getting_to_work
unique(getting_to_work$mode)
如果要删除未使用的因子,我们可以使用droplevels函数,它接受因子或是数据框作为参数。对于后者来说,它将丢弃输入因子中所有未使用的水平。因为我们的数据框中只有一个因子未使用,所以下例中的两行代码是等价的:
levels(droplevels(getting_to_work$mode))
getting_to_work<-droplevels(getting_to_work)
levels(getting_to_work$mode)
4、有序因子
有些因子的水平在语义上大于或小于其他水平。例如,调查中的选择题:好、很好、非常好。类似我们可以可以用"depressed""grumpy""so-so""cheery"和"ecstatic"。结果是类别变量,所以我们可以创建一个拥有5个选项的隐私。在这里,我们使用sample函数来产生10000个随机答案。
happy_choices<-c("depressed","grumpy","so-so","cheery","ecstatic")
happy_values<-sample(happy_choices,10000,replace=TRUE)
happy_values<-factor(happy_values,happy_choices)
head(happy_values)
在这种情况下,对调查者来说,5个选项其实是有序的:“grumpy”比“depressed”更快乐些, 而“so-so” 又比“grumpy” 更快乐些等。这意味着最好把答案存储在一个按顺序排列的因子中,使用ordered函数(或者给factor传入order=TRUE参数)可实现这个功能。
happy_ord<-ordered(happy_values,happy_choices)
head(happy_ord)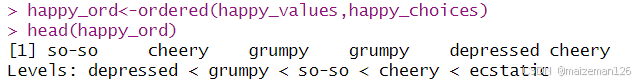
一个有序的因子还是因子,但一般的因子不一定是有序的:
is.factor((happy_ord))
is.ordered(happy_ord)
is.ordered(happy_values)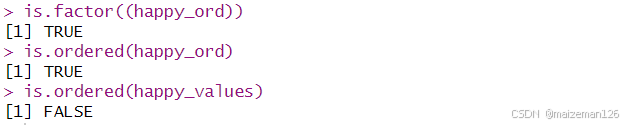
5、将连续变量转换为类别
一个汇总数值变量的方法是计算有多少个值落入不同的“组”(bins)中,cut函数能将数值变量切成不同的块,然后返回一个因子。它通常使用table函数得到每组数字的综合。(hist函数能画出直方图,也能实现这个功能)
下例中,我们随机地生成10000名工人的年龄数据(从16到66,使用beta分布),并将他们按每10年分组:
ages<-16+50*rbeta(10000,2,3)
grouped_ages<-cut(ages,seq.int(16,66,10))
head(grouped_ages)
在本例中,大部分工人的年龄分布在26到36和36到46两个列表中(这正是使用beta分布的结果)。请注意,ages是一个数字变量,而grouped_ages是一个因子:
table(grouped_ages)
class(grouped_ages)
class(ages)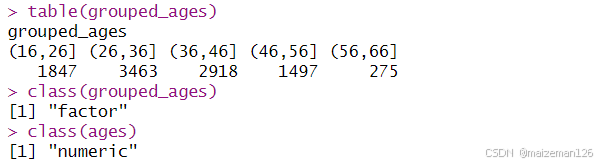
6、将类别变量转换为连续变量
与上面相反的情况是把因子转换为数值变量,这在数据清理中非常有用。如果我们有一些脏数据,例如打错了的数字,在数据导入的过程中,R会将他们解释为字符串。在下例中,其中一个数字有两个小数点,诸如read.table的导入函数将无法把这样的字符串解析为数字格式,而会默认把这一列转换为字符向量。想要把下面的x转换为数字,现在直接调用as.numeric函数就可以了。
dirty<-data.frame(
x=c("1.23","4..56","7.89")
)
as.numeric(dirty$x)
7、生成因子水平
为了平衡数据,使到每个水平的数据点的数目相等,可用gl函数来生成因子。它最简单的形式是:第一个整型参数为要生成的因子的水平数,第二个为每个水平需要重复的次数。通常我们想为每个水平命名,这可以通过给labels参数传入一个字符向量来实现。我们还可以通过传入length参数以创建更复杂的水平排序,例如交替值(alternating value):
# 生成3个因子水平,每个水平重复2个
gl(3,2)
# 为因子水平进行命名
gl(3,2,labels=c("placebo","drug A","drug B"))
# 因子水平交替出现
gl(3,1,6,labels=c("placebo","drug A","drug B"))
8、合并因子
如果我们有多个类别变量,有时把他们合并成一个单一的因子是有用的,其中每个水平由各个变量之间的交叉合并(使用interaction函数)组成:
treatment<-gl(3,2,labels=c("placebo","drug A","drug B"))
gender<-gl(2,1,6,labels=c("female","male"))
interaction(treatment,gender)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









