







 本文介绍了两种处理数据库中无法存储的 Emoji 表情的方法。一种是修改数据库编码为 utf8mb4,以支持4字节的 Emoji,但可能需要重启数据库。另一种方法是通过编程过滤 Emoji,使用 emoji-java 库或正则表达式进行替换,将 Emoji 替换为指定字符。
本文介绍了两种处理数据库中无法存储的 Emoji 表情的方法。一种是修改数据库编码为 utf8mb4,以支持4字节的 Emoji,但可能需要重启数据库。另一种方法是通过编程过滤 Emoji,使用 emoji-java 库或正则表达式进行替换,将 Emoji 替换为指定字符。
方式一: 修改数据库编码为utf8mb4
当我们将数据库字符集设置为UTF-8的时候,是不能存储手机的那些Emoji表情的,因为那些Emoji表情占用了4个字节,而我们常用的utf8_general_ci这种字符集只支持1-3字节,所以会存储失败;
知道了存储失败的原因,我们就可以将表字符集改为 utf8mb4 格式,改了之后有可能会不生效需要重启数据库;(网上很多都是这个解决方案,但是我没有使用这种方式去实现,我的方式是直接将表情包过滤掉,这里只是提供了一个思路…)。
方式二:将表情包过滤掉
2.1 使用emoji-java去过滤表情包
使用方式:
- 引入对应jar包
<dependency>
<groupId>com.vdurmont</groupId>
<artifactId>emoji-java</artifactId>
<version>5.1.1</version>
</dependency>
- 将需要过滤的数据传入
EmojiParser.replaceAllEmojis(需要过滤的字段, 将表情包过滤成的样子)
EmojiParser.replaceAllEmojis(userInfo.getNick_name(), "*")
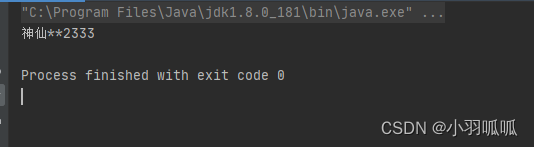
使用案例
public static void main(String[] args) {
String name = "神仙😎😎2333";
String newName = EmojiParser.replaceAllEmojis(name, "*");
System.out.println(newName);
}
输出:会将对应的表情替换成 * 号
2.2 使用正则表达式取过滤
这些表情包,在代码中其实是一些编码 比如直接粘贴😎😎表情到idea编译器中,会被自动转义为"\uD83D\uDE0E",在网上找了对应的编码正则,即可实现替换:
可以将这个方法写到工具类,每次需要使用的时候就调用
public static String replaceEmoji(String source, String slipStr) {
if (StrUtil.isNotBlank(source)) {
return source.replaceAll("[\\ud800\\udc00-\\udbff\\udfff\\ud800-\\udfff]", slipStr);
} else {
return source;
}
}
使用示例:
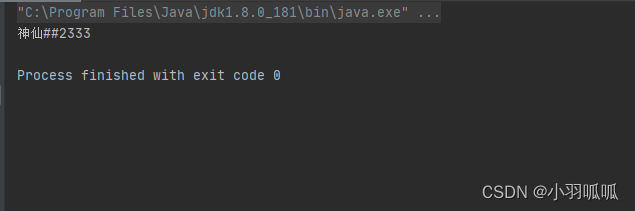
还是用这个案例:
public static void main(String[] args) {
String name = "神仙😎😎2333";
// String newName = EmojiParser.replaceAllEmojis(name, "*");
String newName = replaceEmoji(name, "#");
System.out.println(newName);
}
public static String replaceEmoji(String source, String slipStr) {
if (StrUtil.isNotBlank(source)) {
return source.replaceAll("[\\ud800\\udc00-\\udbff\\udfff\\ud800-\\udfff]", slipStr);
} else {
return source;
}
}
代码输出:

















 5698
5698

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









