



零、本文教学,可用源代码在此👇
【免费】python爬取网易云音乐歌曲(含VIP)(有无损音质)资源-优快云下载
一、获取url
1、排行榜页面右键——>检查
2、点击网络——>文档——>刷新网页(ctrl+R)
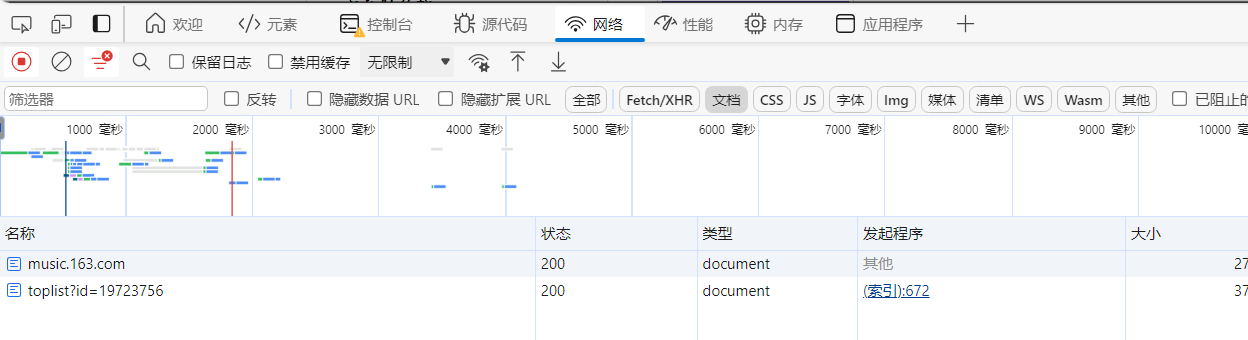
3、点击“toplist?id=19723756“——>标头——>找到”请求url“(第一行),复制(为爬虫的请求地址)


二、发送请求并获取响应
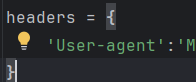
1、拉到最下面寻找user-agent——>复制到代码headers字典中
![]()
 (隐私不截屏全部)
(隐私不截屏全部)
2、防止反爬,在headers加一行代码(防反爬代码)
headers = {
'User-agent':'XXXXXX',
'Referer': 'https://music.163.com/',
}3、发送请求并获得相应(顺便检查print)
response = requests.get(url,headers=headers)
html_data = response.text
print(html_data)查看结果,终端ctrl+F搜索榜单上任意歌曲

说明成功获得响应
三、利用正则表达式爬取歌曲名称、播放id
1、点击“toplist?id=19723756“——>响应

2、点击响应版面——>ctrl+F查找一首当前榜单上的歌曲名称

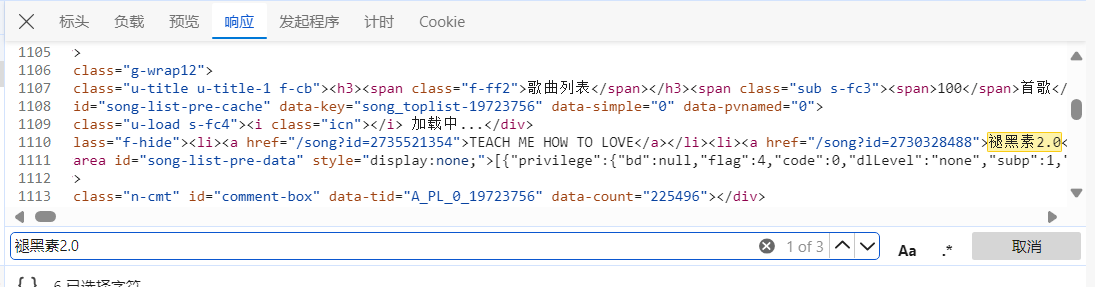
3、向右移动发现其他榜单上歌曲——>找到相似结构——>复制(正则表达式原型)

4、整理正则表达式并获取所有符合条件的项(正则表达式整理过于复杂,请另行学习)——简单讲:不用的.*?,需要的(.*?)
song_list = re.findall('<li><a href="/song\?id=(.*?)">(.*?)</a></li>',html_data)]依旧print(song_list)检查
![]()
5、整理爬取的信息(从song_list列表提取,因为上述findall函数返回值为列表)
for song in song_list:
song_id = song[0]
song_name = song[1]
print(song_id,song_name)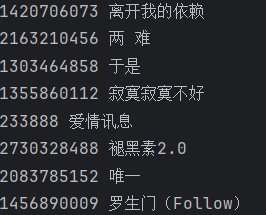
四、利用获取的播放id,下载音乐(⭐重点API网站)
可从此网站获取逆向后的歌曲下载地址:byfuns.top(不是我做的,好厉害的)
也可直接看代码(包括其中):
download_url = f'https://www.byfuns.top/api/1/?id={song_id}'
#无损音质:
#download_url = f'https://www.byfuns.top/api/1/?id={song_id}&level=lossless'
download_response = requests.get(download_url,headers=headers)
download_text = download_response.text
music_content = requests.get(download_text,headers=headers).contentdownload_url即从该网站获取的api,可将载荷(不太需要知道是啥,可自行搜索)解码 download_text获得的是text(文本信息),是最终的音乐下载地址(逆向后的,VIP歌曲可用)music_content获得的是content(二进制),可播放音乐MP3
五、存储到本地
0、防止歌名中含有特殊字符出现乱码,做一个简单清理
cleaned_name = re.sub(r'[\\/?|<>*]','',song_name)1、创建存储下载音乐的文件夹(默认存入当前路径下)
filename = '网易云音乐(VIP版)'
if not os.path.exists(filename):
os.makedirs(filename)2、写入下载的音乐
with open(os.path.join(filename,f'{cleaned_name}.mp3'),'wb') as file:
file.write(music_content)完成了。源代码中有进阶:如何选择榜单、选择下载歌曲数。(很简单,可自行琢磨)



















 2777
2777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









