




简介:本文将详细演示如何用Python爬取糗事百科的笑话段子内容,还会讲到爬虫的时候需要重点关注的点。Web抓取是从Internet提取数据的过程。这也称为网络收集或网络数据提取。Python使我们能够使用自动化技术执行Web抓取。BeautifulSoup是一个Python库,用于解析HTML和XML文档中的数据(结构化数据)。 |
目录
互联网有海量数据。无论你是数据科学家,商人,学生还是专业人士,所有人都会从互联网上获取数据。
网页抓取是什么意思?这是从网站提取数据的简单动作。甚至从Internet复制和粘贴数据都是Web抓取。因此,如果你从互联网上下载了喜欢的歌曲,则意味着您已经从互联网上抓取了数据。
在本文中,我们将探讨一些与Web抓取有关的最常见问题,然后我们将介绍创建Web抓取工具的整个过程,并使Web抓取任务自动化!
什么是网页抓取?
Web抓取是从Internet提取数据的过程。这也称为网络收集或网络数据提取。Python使我们能够使用自动化技术执行Web抓取。
Python中用于网络抓取的一些最常用的库是:
- requests
- BeautifulSoup4
- Selenium
- Scrapy.
为什么我们要从互联网上抓取数据?
如果按照适当的指导方针进行Web抓取,并且可以通过自动化,实现我们在Internet上重复执行的日常任务,会使我们的生活变得轻松。
- 如果你是数据分析师,并且需要每天从Internet提取数据,那么创建一个自动Web爬虫是减轻你每天手动提取数据负担的解决方案。
- 你可以使用网络抓取工具从在线购物网站提取有关产品的信息,并比较产品价格和规格。
- 你可以将网页抓取用于内容营销和社交媒体促销。
- 作为学生或研究人员,你可以使用网络抓取从网络中提取研究/项目的数据。
最重要的是,“自动采集可以让您聪明地工作!”
网站采集合法吗?
这是一个非常重要的问题,但是,对此没有具体答案。有些网站不介意你从其网页上抓取内容,而另一些网站则禁止抓取内容。因此,有必要遵循准则,并且在从其网页上抓取内容时不要违反网站的政策。
让我们看看在通过Internet抓取内容时必须牢记的一些重要准则。






在深入研究网络抓取之前,了解网络的工作原理以及什么是超文本标记语言非常重要,因为这就是我们要从中提取数据的方式。因此,让我们简要讨论一下HTTP请求响应模型和HTML。
HTTP请求/响应模型
网络工作原理的整个工作原理可能非常复杂,但让我们尝试并从简单的角度理解事物,这将使我们对如何进行网络抓取有所了解。
简而言之,HTTP请求/响应是HTTP和其他基于HTTP的扩展协议使用的通信模型,根据该模型,客户端(Web浏览器)向服务器发送对资源或服务的请求,然后服务器发送如果成功处理了请求,则返回与资源相对应的响应;否则,如果服务器无法处理该请求,则服务器将以错误消息进行响应。
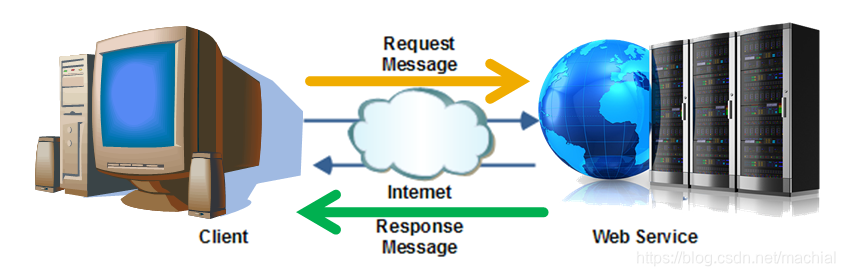
与Web服务器进行交互的HTTP方法很多。但最常用的是 get 和 post
- GET:用于从Web服务器中的特定资源请求数据。
- POST:用于将数据发送到服务器以创建/更新资源。
其他HTTP方法是:
- PUT
- HEAD
- DELETE
- PATCH
- OPTIONS
注意:为了从网站上获取数据,我们将使用 requests 库和 get() 方法向Web服务器发送一个请求。
虽然HTML本身超出了本文的讨论范围,但是你必须了解HTML的基本结构。不要担心,你不
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 428
428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











