






目录
一 BeautifulSoup的介绍
BeautifulSoup是一个可以从html或xml文件中提取数据的Python库。它能够通过你喜欢的转换器实现惯用的文档导航、查找、修改文档的方式。在Python开发中,主要用的是BeautifulSoup的查找提取功能,修改功能很少使用
二 BeautifulSoup的使用
1.导入BeautifulSoup库
pip install beautifulsoup42.导入requests库
pip install requests3.安装和lxml(或者html5lib)
pip install beautifulsoup4 lxml
4.发送请求
使用 requests 库发送 HTTP 请求,获取网页的响应内容。
url = ‘https://www.example.com’
response = requests.get(url)
5.解析响应内容
使用 BeautifulSoup 解析获取到的网页内容,创建 BeautifulSoup 对象。
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.content, ‘html.parser’)
6.定位目标元素
使用合适的选择器(如标签名、类名、ID 等)在解析后的对象中定位到需要爬取的元素。
link = soup.find(‘a’)7.提取数据
从定位到的元素中提取所需的信息,如文本内容、属性值等。
href = link.get(‘href’)以上是找到第一个<a>标签,并获取其href属性
以上两步还可以写成这样
data = soup.find('a', class_='href').text
提取标题
title = soup.title.string
8.示例代码
import requests
from bs4 import BeautifulSoup
# 定义要爬取的网页 URL
url = 'https://example.com'
# 发送请求并获取网页内容
response = requests.get(url)
# 解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
# 提取所需的数据
data = soup.find('div', class_='athm-sub-nav__car__name').text
# 输出数据
print(data)
请将
'https://example.com'替换为你实际要爬取的网页 URL。需要注意的是,在实际应用中,还需要根据具体情况进行更多的错误处理和优化
以下是爬取网页某个信息的图片
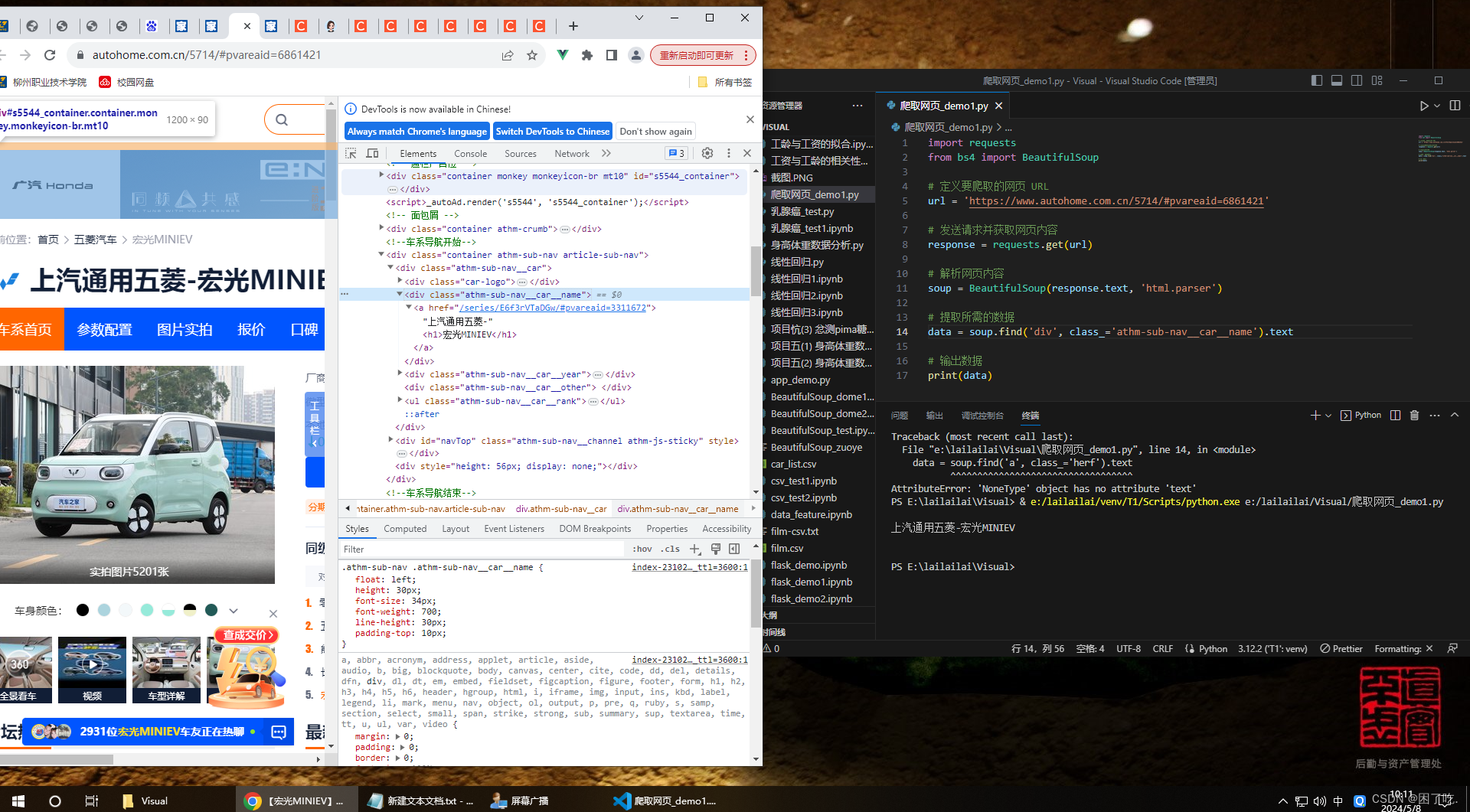
三 BeautifulSoup的错误和异常
1.**AttributeError**
当尝试访问不存在的属性或方法时出现。
2.**TypeError**
在类型不匹配或操作不正确时发生。
3.**ValueError**
当传入的值不符合要求时出现。
4.**HTTPError**
在网络请求出现错误时,如无法访问网页等。
四 处理BeautifulSoup的异常和错误
1.使用try-except语句:
将可能引发异常的代码放在try块中,在except块中处理异常情况
2.检查返回值
根据具体的操作,检查返回的结果是否符合预期,如有异常情况进行相应处理
3.添加适当的错误提示
在处理异常时,可以输出一些有意义的错误信息,帮助调试和定位问题。
4.BeautifulSoup处理HTML异常的示例代码
from bs4 import BeautifulSoup
import requests
try:
# 发送请求并获取 HTML 内容
response = requests.get('https://example.com')
html_content = response.text
# 使用 BeautifulSoup 解析 HTML
soup = BeautifulSoup(html_content, 'html.parser')
# 进行其他操作
except Exception as e:
# 处理异常
print(f"发生异常: {e}")https://mp.youkuaiyun.com/mp_blog/creation/editor?spm=1000.2115.3001.5352


















 4785
4785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









